
These tools have saved us from the drudger of writing tens of thousands of lines of repetitive code—we hope you find them useful.
Moving data from one source to another is not all that difficult in the scheme of things. If your source data is a tab-delimited file, for example, and you need it in an SQL relational database, you might write a little SQL definition, then churn out a C program to read the data from the source file and write it out to the database. But when you're dealing with a big project, or in our case, really big, and you find yourself working with dozens of sources giving you gigabytes of data, writing all that code gets old fast.
To solve this problem, here are two tools to do the job. Together, they generate database definitions for SQL, write C header files with your data definitions and function prototypes, write C code to get data to and from C structures and generate C code for an XML parser.
The human genome is the instruction manual that is encoded in our DNA. It is made up of three billion pairs of chemical letters, commonly known by the initials G, C, A and T. The genome data is 24 long strands of these letters—not exactly light reading. The Human Genome Browser is a web site at the University of California, Santa Cruz that gives scientists around the world a visual representation of this mountain of data. The browser combines the sequence data itself with higher-level annotations of the function of particular regions of the genome. Users can locate and zoom in on genes they are interested in, link to research conducted on that section of the genome and compare the genomic data with that of other species. The browser stacks particular types of annotations as tracks beneath genome coordinate positions.
The Genome Browser has an HTML/CGI front end that lets the user view and (with the help of dynamically generated image maps) click on genome tracks. Form fields give the user a way to set zoom level and control the data density of the tracks. The CGI source code is C, and the genome data is stored in an SQL database.
There is a lot of data. The browser source code has to deal with data formats for gene prediction and for similarities between the human genome and the genomes of other species. Complicating matters is the fact that we collaborate with at least a dozen external sources that each have data in their own format. Even if we don't want to use their data formats internally, we still need to write a parser to read them in and convert them to our own format. Probably half of our use of the code generators is to make it easier to import files from other groups.
autoSql generates SQL and C code for saving and loading data to a database. By using autoSql, we don't need to write the tedious data definition, which involves reading and writing code. For example, the browser has around 30 public tracks and 30 experimental tracks. Each track is associated with a table in a relational database. All of the modules that load a track table into memory are generated by autoSql.
Later in the project, we started using XML to collaborate with a research group in Japan. XML is also useful to exchange data with other public sites via DAS (the Distributed Annotation System, a protocol for transferring genomic data over the Internet).
autoXml generates C code for an XML parser given an XML DTD file. Since XML I/O is even more code intensive than SQL I/O, autoXml has already proven to be useful.
Together, autoSql and autoXml have proved to be invaluable time-savers. autoSql has been a critical workhorse to the browser project. At 1,200 lines, it has generated fully half the browser program, tens of thousands of lines of code.
Although we don't use XML as much as SQL, we've already broken even with autoXml. In a single project to import data from the Riken mouse genome annotation project in Japan, autoXml generated approximately 1,500 lines of code. (It's only 1,200 lines itself.)
You can download the binaries for autoSql and autoXml from www.soe.ucsc.edu/~kent/exe. The source code, Linux executables and examples from this article are at www.soe.ucsc.edu/~kent/src/autoCode.tgz.
autoSql is a program that automatically generates an SQL table creation script and C code for saving and loading data to a database based on an object specification. (See Figure 1 for an overview of this process.)
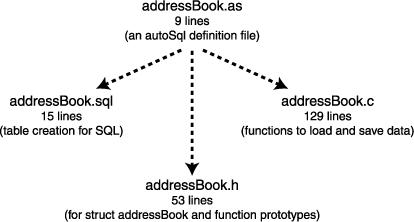
Figure 1. Running a Definition File through autoSql
The specification language is a bit quirky, but it has proven effective for many jobs. We originally developed autoSql for use with a relational database; it turns out that it generates code that can load from many flat formats as well, as long as they are in a text format.
Imagine a simple address book that just stores name, street address, zip code and state. The autoSql specification for this would be:
table addressBook
"A simple address book"
(
string name;
"Name - first, last, both, we don't care"
lstring address; "Street address"
string city; "City"
uint zipCode; "A zip code
is always positive, so can be unsigned"
char[2] state;
"Just store the abbreviation for the state"
)
If this looks like a bit of a hybrid between a C structure and an SQL table definition, it's because Jim was switching between C and SQL when he made the autoSql language.
When you run the address book template through autoSql, the program produces the SQL table definition:
#A simple address book
CREATE TABLE addressBook (
name varchar(255) not null, # Name -
first, last, both, we don't care
address longblob not null, # Street address
city varchar(255) not null, # City
zipCode int unsigned not null, # A zip code is
always positive, so can be unsigned
state char(2) not null, # Just store
the abbreviation for the state
#Indices
PRIMARY KEY(name)
);
and the following C structure definition:
struct addressBook
/* A simple address book */
{
struct addressBook *next;
/* Next in singly linked list. */
char *name;
/* Name - first, last, both, we don't care */
char *address; /* Street address */
char *city; /* City */
unsigned zipCode; /* A zip code is always
positive, so can be unsigned */
char state[3]; /* Just store
the abbreviation for the state */
};
Typically in C you access a single row of an SQL database at a
time. The row is returned as an array of strings. It is up to the C
program to convert the ASCII representation of numbers to binary
numbers. This is not hard work, but after you've typed in 20 or 30
lines that look something like:
point->x = atoi(row[1]); point->y = atoi(row[2]);you'll appreciate the following two routines that autoSql generates for you:
void addressBookStaticLoad(char **row,
struct addressBook *ret);
/* Load a row from addressBook table into ret. */
/* The contents of ret will be replaced at the */
/* next call to this function. */
struct addressBook *addressBookLoad(char **row);
/* Load a addressBook from row fetched with */
/* select * from addressBook from database.*/
/* Dispose of this with addressBookFree(). */
The first routine typically is used when you just want to process
one item at a time. It doesn't allocate any dynamic memory, and so
it's quite fast. The second routine saves the structure to dynamic
memory. Since the C structure always includes a “next” field, you
easily use this routine to build a list of address book entries.
The only problem with using dynamic memory is that you have to remember to free it. While autoSql can't remember to free things for you, it can generate routines to free a single dynamically allocated structure, or a list of dynamically allocated structures. That's what the next two routines do:
void addressBookFree(struct addressBook **pEl);
/* Free a single dynamically allocated
* addressBook such as created with
* addressBookLoad(). */
void addressBookFreeList(
struct addressBook **pList);
/* Free a list of dynamically
* allocated addressBook's */
Reading structures without having to write code to load them up a field at a time is nice, but sometimes you need to write structures, too. autoSql assumes that you'll either want to save the structure in a tab-delimited or in a comma-delimited format. It generates a routine that can do either:
void addressBookOutput(struct addressBook *el,
FILE *f, char sep, char lastSep);
/* Print out addressBook. Separate fields with
* sep. Follow last field with lastSep. */
and macros that make it convenient to do commas or tabs:
#define addressBookTabOut(el,f)
addressBookOutput(el,f,'\t','\\n');
/* Print out addressBook as a line in a
* tab-separated file. */
#define addressBookCommaOut(el,f)
addressBookOutput(el,f,',',',');
/* Print out addressBook as a comma
* separated list including final comma. */
autoSql generates a routine to
read comma-separated lists. While you are unlikely to call this
routine directly yourself, fields more complicated than simple
strings or integers get saved in the database as comma-separated
lists. This routine allows autoSql to have objects that contain
other objects.
autoSql has three types of objects:
Simple: objects that contain no variable-sized arrays.
Object: objects that can contain variable-sized arrays. A next pointer is automatically inserted as the first field in the C structure corresponding to an object.
Table: like objects, but the program generates an SQL as well as a C definition.
Simple objects differ from other objects in how the program treats array declarations. In the field declaration:
simple point[3] triangle; "A three sided figure"
the three points are stored in memory as a C array. If this were declared instead as
object point[3] triangle; "A three sided figure"the three points would be stored in memory as a singly linked list.
The following basic field types are supported:
int: 32-bit signed integer
uint: 32-bit unsigned integer
short: 16-bit signed integer
ushort: 16-bit unsigned integer
byte: 8-bit signed integer
ubyte: 8-bit unsigned integer
float: single precision IEEE floating point
char: 8-bit character (can only be used in an array)
string: variable length string up to 255 bytes long
lstring: variable length string up to 2 billion bytes long
Additionally, the simple, object and table types can be used as fields.
An array can be declared as either fixed size or variable size. A variable sized array is declared by putting a field name inside of the brackets in the array declaration. This field must be defined before the array.
Imagine that you've just built an amazing 3-D modeling program. The only problem is that now you need to save the structures in a database. Listing 1 is a way you might build the database with autoSql. Saving it as threeD.as and running
autoSql threeD.as threeD
would end up generating 393 lines of bug-free (I think!) C code and 14 lines of SQL for the investment of 33 lines of specification. (Refer to Listing 2 for the complete autoSql grammar.)
autoXml generates C code for an XML parser given an XML DTD file. It will generate a structure for each “element” in the DTD and populate the structure with fields for each attribute of the structure. By default, it will generate a parser that ignores elements and attributes not in the DTD, but otherwise is a validating parser. If you use the -picky flag, it will be fully validating.
The autoXml parser will load the entire file into memory. If this is a problem you'll have to resort to the lower-level xap parser, which is much like the commonly used expat parser, but a bit faster.
If you find yourself befuddled by all the acronyms so far, you're probably new to XML (eXtensible Markup Language). It has a tag-based format, and a simple example of an XML doc might be:
<POLYGON id="square">
<DESCRIPTION>
This is soooo square man
</DESCRIPTION>
<POINT x="0" y="0" ->
<POINT x="0" y="1" ->
<POINT x="1" y="1" ->
<POINT x="1" y="0" ->
</POLYGON>
Everything in XML lives between <TAG></TAG> pairs. A tag may have associated text, attributes and subtags. In the example above, POLYGON has the subtags DESCRIPTION and POINT, the attribute id and no text. DESCRIPTION has the text “This is soooo square man” and no subtags or attributes. POINT has the attributes x and y. POINT also illustrates a little XML shortcut: tags containing only attributes can be written <TAG att=“something” -> as a shortcut for <TAG att=“something”></TAG>.
XML is much like HTML but has significant differences. All attributes must be enclosed in quotes in XML, while quotes are optional in HTML. Tags must strictly nest in XML, while HTML allows tags to be opened but not closed. The tags in HTML are predefined. In XML the definition of tags is up to you.
Tags can be defined two ways in XML: by a DTD file or by an XML schema. There are pros and cons for each method. DTD files are relatively simple and are recognized by a wide variety of parsers and XML browsers. On the other hand, DTD files can't express that a certain attribute has to be numerical. XML schemas are more complex. They are themselves written in a type of XML, which is nice in some ways. They are not as widely supported yet. Currently autoXml only works with DTD files with some modest extensions.
Here is a DTD file that would describe the POLYGON format above:
<!ELEMENT POLYGON (DESCRIPTION? POINT+)> <!ATTLIST POLYGON id CDATA #REQUIRED> <!ELEMENT DESCRIPTION (#PCDATA)> <!ELEMENT POINT> <!ATTLIST POINT x CDATA #REQUIRED> <!ATTLIST POINT y CDATA #REQUIRED> <!ATTLIST POINT z CDATA "0">
The DTD has two major types of definitions: ELEMENTs and ATTLISTs (or attributes). An element definition includes the name of the element and an optional parenthesized list of sub-elements. The sub-elements must be defined elsewhere in the DTD with the exception of the #PCDATA sub-element, which is used to indicate that the element can have text between its tags. Each sub-element may be followed by one of the following characters:
?: the sub-element is optional.
+: the sub-element occurs at least once.
*: the sub-element occurs 0 or more times.
If there is no following character the sub-element occurs exactly once.
The ATTLIST defines an attribute and associates it with an element. It is good style to keep ATTLISTs together with their ELEMENT. Here are the fields in an ATTLIST:
element: name of element this is associated with.
name: name of this attribute.
type: generally CDATA. Can be a reference or date, but these are not supported by autoXml.
default: this contains a default value to be used if the attribute is not present. The keyword #REQUIRED in this field means that the attribute must be present. The keyword #IMPLIED means that it's okay for this attribute to be missing (in which case it will have a NULL or zero value after it is read by autoXml).
autoXml extends the type field of ATTLIST to include INT or FLOAT for numerical rather than string values. Similarly you can use #INT or #FLOAT in place of #PCDATA to put a numerical type in the text field. If you include these extensions, please use the .dtdx rather than .dtd suffix on your DTD file.
Currently autoXml only copes with DTD comments if they start on a line by themselves. autoXml expects all ELEMENTS and ATTLIST declarations to fit on a single line. It doesn't handle reference data types beyond saving the reference ID as a string.
Listing 3. autoXml Code Generation
Refer to Listing 3 for a complete example of the source code autoXml generates. In addition to the .h file shown in Listing 3, autoXml generates a corresponding .c file as well. Each XML file has to have a root object. In this case the root object is POLYGON (our DTD as is won't let us have more than one polygon per file). You can read an XML file that respects this DTD using the polyPolygonLoad() function, and save it back out using the polyPolygonSave.
autoSql and autoXml work well on a range of data, as you've seen, anywhere from an address book to gene tracks. We hope you'll find these tools useful on your own projects.


