
By Heike Jurzik
The Streamline Editor is a popular text editor for Unix and Linux systems. In contrast to editors such as Vi and Emacs, sed is not interactive. Instead, users define text to delete, modify, or add at the command line. You can also script sed commands and run them as a single batch job. If you need to modify a number of characters in one or multiple files, sed saves you from typing till your fingers bleed.
sed normally reads texts for processing from standard input (stdin), however, you can alternatively specify one or multiple files. sed will apply the specified commands to each line, writing them to a buffer. The output of the buffer will be sent to standard output (stdout), unless you change the default. The generic command syntax is as follows:
sed [options] 'command(s)' file(s)
To prevent the shell from mangling the command, place the command in single quotes. Commands can refer to single lines, parts of lines, strings or - failing any of these options - whole files. The definition of which lines to edit is referred to as the address. Table 1 gives an overview of the main sed commands and addressing examples.
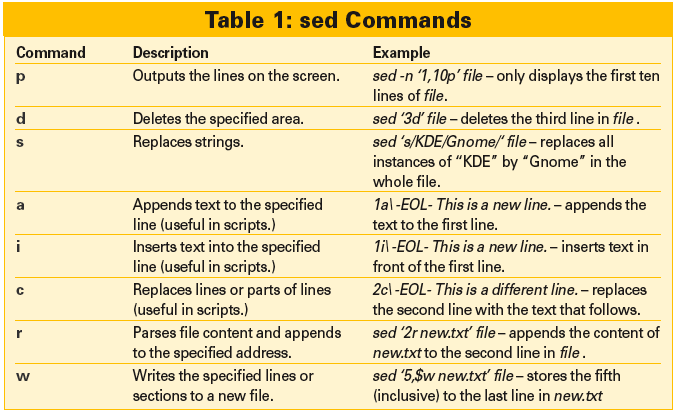
As previously mentioned, sed commands are applied to so-called addresses (specific lines or sections of a file). You can combine addresses with regular expressions for extremely precise definitions. The following sections and examples look at addressing options for various sed commands. You can use these options with any of the streamline editor's commands.
The p command is for simple output. To display the second line, for example, just insert the figure 2 before the command:
$ sed '2p' file Here is the first line. The second line. The second line. Here is line 3. ...
The output may not be what you expected: instead of the second line, the whole file is printed on screen, and the second line is printed twice. To remove the unwanted output, add the -n option:
$ sed -n '2p' file The second line.
The delete command (d) in its simplest form expects the line number to process. For example, the following command
sed '1d' file
deletes the first line in file. To delete multiple lines at one fell swoop, specify the first and last lines to be deleted and add a comma to separate the numbers. For example, the following command
sed '2,4d' file
deletes the second to fourth lines. But it is just as easy to delete every nth line. The following command
sed '1~3d' file
deletes every third line starting in the first line. If you want to remove the file content from the fifth line to the end of the file, you do not need to count the number of lines first and give sed the exact numbers. Instead, you can use a regular expression. The following command
sed '5,$d' example.txt
removes all the lines from the fifth to the end of the file, as defined by the dollar sign.
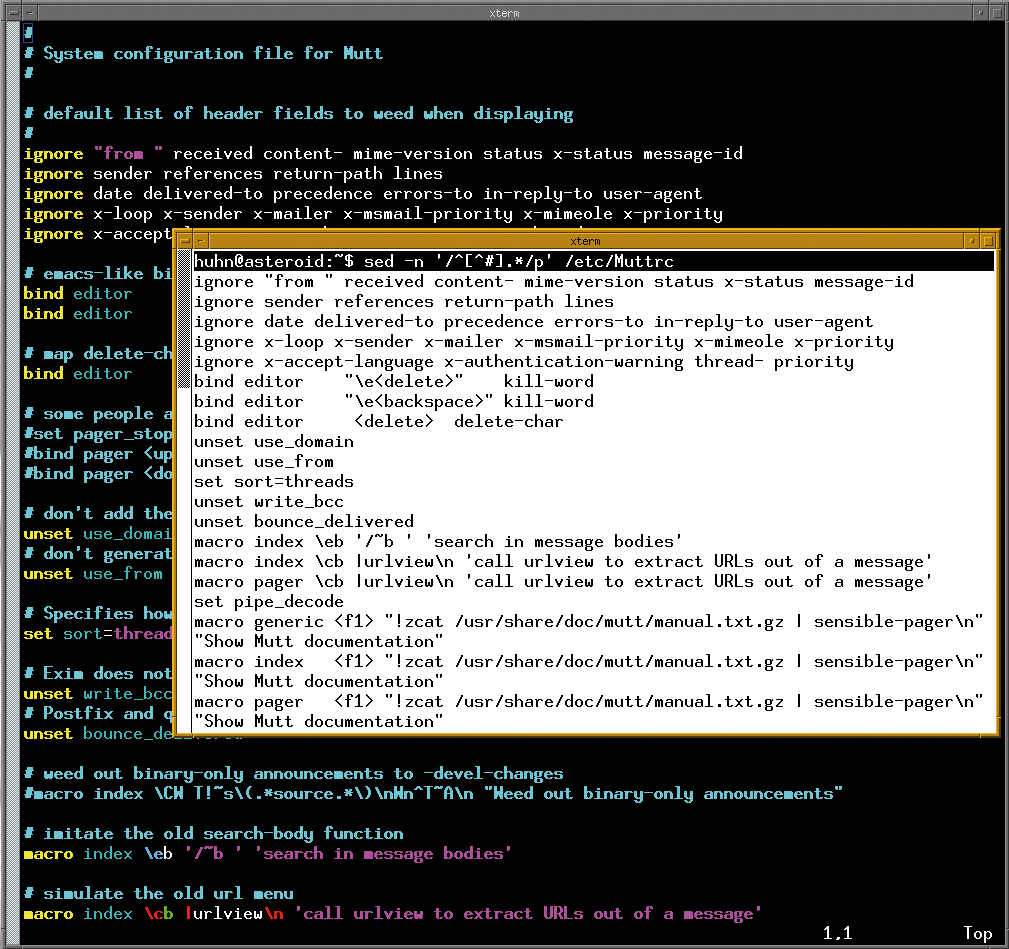
The delete command is really useful if you need to view configuration files with lots of comments below /etc. sed lets you delete any lines that start with a hash:
sed '/^#.*/d' /etc/inetd.conf
The address for the d command is the regular expression between the two slashes, which references any lines that start with a hash and continue with any or no characters. As this still outputs any blank lines in the configuration file on your screen, you might like to use a different regular expression (^[^#].*) to print (p command) any lines that do not start with a hash (Figure 1.)
The s command lets you replace strings. The command is followed by a separating character, the search key, another separating character, the characters you want to insert, and finally a closing separating character. Basically, there are no restrictions on what you use as a separating character, but the separating character is not allowed to occur in the search key. To replace every occurrence of the word "line" in a file with "row," you could apply the following command:
$ sed 's/line/row/' file This is the first row. The second row, but this is the end of the line. ...
sed replaces the first occurrence of the search key in each line. Specify the g command to change all occurrences:
sed 's/line/row/g' file
If the slash character, which we used as a separator in this example, occurs in the search key, you can opt for a different separating character, such as a hash or the pipe character:
sed 's#http://www.huhnix.net#http://www.huhnix.org#g' url.html
The substitution command is not restricted to processing the whole file, of course. You can address individual lines. The following command:
sed '1s/line/row/g' file
searches and replaces in the first line only; again the g is important, just in case there are multiple occurrences of the search key.
To perform multiple tasks with a single call to sed, insert -e before the individual commands. For example, you could use the following command to delete from the fifth line to the end of the file and run a search and replace job for the remaining text:
sed -e '5,$d' -e 's/KDE/Gnome/g' file
As an alternative, you can use semicolons to separate the commands and place the commands in curly braces. You could write the previous command like this:
sed '{5,$d;s/KDE/Gnome/g}' file
sed also has commands for reading and writing. If you want to insert a file titled extras after line three, try the following command
sed '3r extras' file
The w command makes it just as easy to extract and write content:
sed '1,4w 1bis4.txt' file
writes the first four lines to a new file 1bis4.txt.
If you are in the mood for automation, you can group any number of sed commands in a script, which you can then turn loose on the target files using the -f option. For example, to delete the second line in a file and add a line after line four, write the following commands in separate lines:
2d 4a\ Add this after line four.
The a command relies on you inserting a backslash and a new line character after the command itself (4a). The new line of text that you want to insert has to be in a line of its own. If you need to insert multiple lines of text, you need to terminate each of these lines (apart from the last one) with a backslash:
4a\ Add this after line four.\ And this.\ And a little bit more:)
To insert the text before a line rather than appending, just replace a with i:
1i\ This is something new...
Then store the command file (you could call it script for want of a better name), pass it to sed, and apply it to one or more files:
sed -f script file
As previously mentioned, sed does not change the original by default, but instead sends its output to stdout. After making sure that you really want to keep the changes, you can redirect the output. The > operator sends the results to a file, for example:
sed -f script file > newfile
If you need to modify the original file without taking a detour, sed has the parameter -i to do just that. The following command
sed -i -f tasks file
tells sed to overwrite the file with your changes. The parameter will create a safe copy if you like: you can specify a file extension for the backup file as follows:
sed -i.bak -f tasks file
Besides saving the file with the changes, this command also saves a copy of the original file as file.bak in the same directory.
sed is really useful in combination with other command line programs. Let's assume you have a number of files with blanks and hyphens in their filenames, and you would like to convert both the blank and hyphen characters into underscores:
$ ls -1 *.mp3 01 Saor_Free_News from Nowhere.mp3 02 Whirl-Y-Reel.mp3 ...
In this case, you would use a script to store the substitution rules for sed, as follows:
s/ /_/g s/-/_/g
Of course, you could combine the two lines to form a single regular expression, s/[ -]/_/g - but that has nothing to do with our example. Run the script against the files first, to check if the substitutions will work when you do this for real. Because sed can read from standard input, you can easily pipe the output of the ls command directory to the sed command:
$ ls -1 *.mp3 | sed -f skript 01_Saor_Free_News_from_Nowhere.mp3 02_Whirl_Y_Reel.mp3
If everything seems to be working, you can then add the mv command to rename the files. I will also modify the command to include a for loop that will allow sed to access all these files directly:
$ for i in *.mp3; do mv -v "$i"`echo $i | sed -f skript`; done `01 Saor_Free_News from Nowhere.mp3' -> `01_Saor_Free_News_from_Nowhere.mp3' `02 Whirl-Y-Reel.mp3' -> `02_Whirl_Y_Reel.mp3'
Translated into plain English, this collections of commands says: for all files with the *.mp3 extension, move the files visibly to the result of the sed operation. As the original filenames include blanks, you need to put $i in quotes.
Once you get used to the handy sed stream editor, I'm sure you'll find hundreds of uses for it.