
|
The Linux kernel mailing list comprises the core of Linux development activities. Traffic volumes are immense, often reaching ten thousand messages in a given week, and keeping up to date with the entire scope of development is a virtually impossible task for one person. One of the few brave souls to take on this task is Zack Brown. Our regular monthly column keeps you abreast of the latest discussions and decisions, selected and summarized by Zack. Zack has been publishing a weekly online digest, the Kernel Traffic newsletter for over five years now. Even reading Kernel Traffic alone can be a time consuming task. Linux Magazine now provides you with the quintessence of Linux Kernel activities, straight from the horse's mouth. |
The kernel is always undergoing various clean-up jobs and housekeeping chores. Recently, most of the remaining references to DriverFS were removed by Rolf Eike Beer.
DriverFS has been called SysFS for quite a long time now, but various docs and source files have stuck to the old name, either because fixing the references to the name wasn't so important, or else because the maintainers of those files had gone on to other projects.
Adrian Bunk has been working on removing obsolete OSS sound drivers for a long time, and he recently scheduled a number of them for removal. In the case of OSS, obsolete means there are working, fully featured ALSA replacements ready to take up the slack.
Unfortunately, it's not always clear how well an ALSA driver needs to work in order to be considered a proper replacement. For example, some ALSA drivers are much larger than their OSS equivalents, which can present a significant problem for people working on embedded systems, even if the ALSA version supports everything the old OSS version does. Still, bit by bit, Adrian hacks away at OSS. There is not much reward in it, but it leads to a cleaner, happier kernel.
Russell King has also been working to remove obsolete code, including a number of kernel functions that have been deprecated for a long time. Unfortunately, removing these kernel functions would break several drivers, including MWave and ibmasm.
The situation with the obsolete kernel functions was rendered more difficult by the fact that a number of the drivers that were affected by these functions were fairly unmaintained, which was why they hadn't been updated in the first place. But as it turned out, Max Asbock fixed up ibmasm, and Alan Cox patched MWave.
In addition to OSS work, Adrian has taken over the responsibility for the Trivial Patch Monkey from Rusty Russell. The Trivial Patch Monkey is a semi-automated system that gathers together extremely simple and obvious kernel patches, so no one else has to keep track of them or resubmit them if they get missed the first time.
Originally, Rusty started up the Trivial Patch Monkey because a lot of simple patches were indeed missed the first time, and developers found it frustrating to have to resubmit obviously correct patches over and over.
The original development of the patch monkey occurred in an era when Linus Torvalds was having a difficult time keeping up with the vast number of patches coming his way. One attempt to ease developer tensions was to start using version control. The other side of the solution was to manage the simplest and most obvious patches with the Trivial Patch Monkey, which Rusty maintained for years and has now handed off to Adrian.
Phillip Hellewell and Michael Halcrow have submitted eCryptFS version 0.1 for consideration for inclusion in the official kernel tree. This is a stripped-down version of what they hope it will become; they've chosen to submit it in its current form to make the basic design and behavior easier to analyze and debug. If it passes muster, they plan to begin layering additional features on top of that infrastructure.
The basic idea of eCryptFS is to make encryption and decryption completely transparent to user applications. Encryption is done on a per-file basis, with cryptographic metadata stored within the file itself. This allows users to treat eCryptFS files exactly as they would any others. Files may be copied from, even through untrusted domains, and still remain readable only by users possessing the proper cryptographic credentials. In this way, eCryptFS behaves much like GNUPG or other public-key encryption tools.
Because of this flexibility in the basic design, tremendous latitude will exist for specifying security policies on a given system. For the moment, however, Phillip and Michael have provided only per-mount support until the basic features and design can be properly tested. It seems clear that additional code already exists and is ready to be added as the current offering gains approval.
The git developers are having a blast. The project has gone well beyond what anyone - including Linus Torvalds - expected it to be and now hovers on the brink of a 1.0 release, if that hasn't already happened by the time this article is published. But git has also stayed true to its original goals. It does not provide an easy CVS-like interface that anyone can pick up and run with. Rather, as Linus described it in the beginning, it is more a set of powerful, low-level commands, on top of which anyone may script a friendlier set of higher-level operations. Cogito remains the most popular front-end for git, and it does indeed provide an easy CVS-like interface to expose the power beneath.
While Linus some time ago stepped down as git project leader, he still maintains a big presence. In addition to coding, perhaps his biggest contribution is to keep development on track. Although a relatively small project, the elegance of its basic design is not always clear, and developers occasionally find themselves trying to solve problems that don't actually exist. For instance, the git protocol didn't handle what various folks needed, and they began discussing the possibility of replacing it, and how this would affect backwards compatibility issues; until Linus piped up with, "Hey guys, I actually planned for the protocol to be extensible."
One persistent problem with git is file rename tracking. In practice, unless you actually need to use a bit of rename history for something, git handles renames just fine. In other words, at the most basic level, if you rename a file in a git repository, git is able to track this. However, the interface to present this information to the user has yet to be written, and seems difficult. This stems from Linus's insistence on the idea that rename detection belongs at the front-end. He feels that relying on the user to tell git when a rename has occurred will lead to many error-cases, in part because users don't always even realize how data has moved from file to file. But the breadcrumbs are there, he says, to accurately and efficiently pick up the trail when the user asks for it.
The rename tracking debate is ongoing, with nobody - not even Linus - fully aware of what is required to do accurate rename tracking the way he says it should be done. Although he's presented detailed descriptions of portions of the solution, he is still stumped by several aspects; and it seems everyone else is as well. But this has the feel of things Linus has done many times before. He'll insist that a certain way is correct, even though conventional wisdom is against it, and in spite of the fact that no one including himself can see how it could be accomplished; arguments and flame-wars ensue; and in the end, the pieces fall into place and become the new conventional wisdom. It seems rename tracking is likely to turn out that way as well.
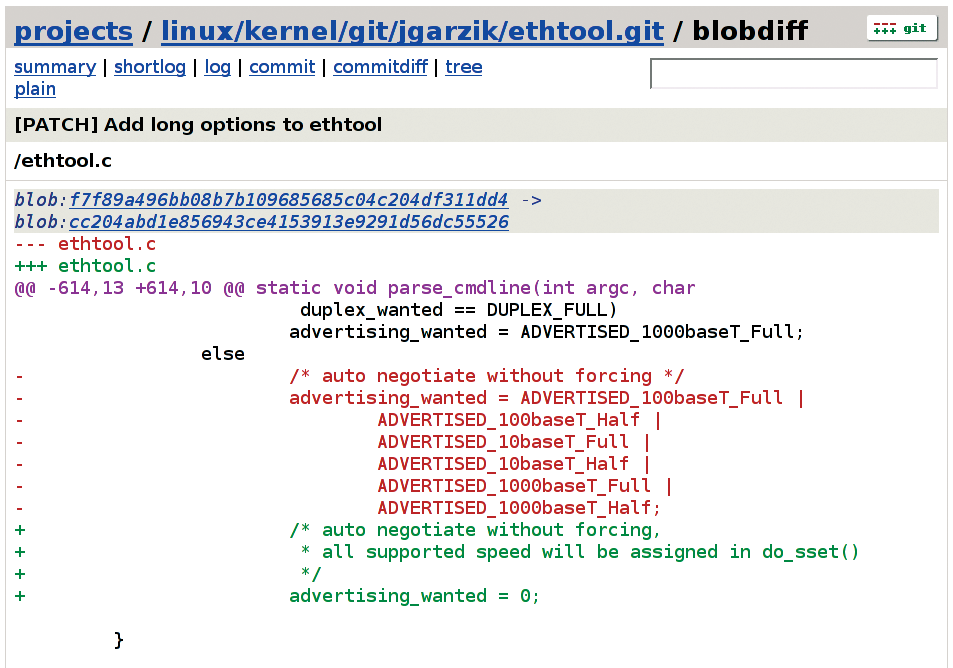
In the meantime, folks like Jeff Garzik are very active with git development. Jeff recently migrated ethtool development to a git repository, and he has also been considering some strange modifications to git itself. His latest brainstorm involves adding support for a purely networked git repository. So far, git has presented itself as a distributed system, in the sense that there is no central repository, and each node acts as the server for its own version of a given project. But Jeff would apparently do away with even this looser notion of a repository server. Instead of each machine serving its own repository, many systems would participate, with no single machine being essential to maintain the whole. Users would obtain the most recent project version by querying a git network, rather than just a single computer on the Internet. Or one git network would query another, and project repositories would float through the world on binary wings.
It's a crazy idea. But then, so is git. So is rename tracking at the front-end. So is implementing revision control as a series of system-call-like interfaces. The whole thing is insane. And that's its best feature.
Rafael J. Wysocki has split the software-suspend code into two independent subsystems; and with Pavel Machek approving of most of his changes, this is likely to be the direction taken by the official tree. The point is to simplify the code and make it saner, while (eventually) removing certain portions into user-space.
The primary subsystem is the snapshot handler, which creates the data structures that must be preserved while the system is suspended. The secondary subsystem, and the one most likely to migrate into user-space, is the swap handler, which takes whatever it is given by the snapshot code and writes it to swap prior to a suspend. On resume, this subsystem also reads the data out of swap to recreate the running system.
By taking this approach, Rafael is able to shave off three quarters of the snapshot data written to disk, making more memory available during the resume. At the same time, a size restriction that had been imposed on this data is also lifted. And various global variables are no longer needed (always a good thing).
Rafael points out that this is primarily a proof-of-concept, and little details like the error paths are yet to be tested. But the design itself seems to have met with approval, and we can expect this to be the new direction of swsusp.