
By Michael Adam
The Open Source Samba [1] system has provided file and print services for Windows and Unix-style computers since 1992. The Samba developers [2] always had difficulties emulating Windows server characteristics without the specifications, but thanks to Microsoft finally releasing the server protocol specifications late in 2007 [3], the task is now easier.
A recent add-on tool dubbed CTDB [4] now provides Samba with a feature that even Windows does not support: clustered file servers. Samba now offers the option of a distributed filesystem with multiple nodes that looks like a single, consistent, high-performance file server. And this cluster-based file server system is (more or less) infinitely scalable with respect to the number of nodes. (Windows 2003 does have some support for clustering, but it is designed with web and database servers in mind and restricted to eight nodes.)
In this article, I describe some of the the problems Samba solves with clustering, and I take a look at the history and design of the CTDB add-on at the center of Samba's clustering support. In addition, you'll get some hints on how to configure CTDB and set up your own Samba cluster.
| CTDB the Manager |
|
Although CTDB was originally developed for Samba clustering, it has subsequently evolved into a management solution for a collection of other services, such as NFS, the vsftpd FTP daemon, and Apache. CTDB manages these services by starting and stopping programs and by monitoring programs at run time. Additionally, CTDB takes the necessary actions to support IP address switching. The CTDB_MANAGES_service configuration parameters in /etc/sysconfig/ctdb specify whether or not CTDB manages a service; these parameters can be set to yes or no. Thus far, the following parameters exist:
You need to remove the start scripts for the CTDB-managed services from the runlevels, for example, using chkconfig -s smb off. Incidentally, CTDB_MANAGES_SAMBA has nothing to do with cluster-wide handling of the TDB files. CTDB does this independently of its service management functionality. Service monitoring is performed by event scripts in /etc/ctdb/events.d/ called by the CTDB daemon. Thus, to put a new service in the capable hands of CTDB, you just need to write a new event script. |
The Samba developers had to solve a few intrinsic problems in order to serve up the same file at the same time to multiple client nodes attached to a filesystem cluster. First of all, the Common Internet Filesystem (CIFS) protocol used with Samba and Microsoft file service systems requires sophisticated locking mechanisms, including share modes that exclusively lock whole files and byte-range locks to lock parts of files. These mandatory locks in Windows are just not convertible to the advisory locks used in the Posix landscape [5]. To work around this issue, Samba must store CIFS locking information in an internal database and check the database on file access.
Also, the various Samba processes must exchange messages. For example, a client can send a lock request with a timeout for a file area currently locked by another client. If one client lifts the lock within the timeout, Samba grants a new lock and sends a signal to tell the waiting target process that a message is available. The system must also synchronize ID mapping tables, which map Windows users and groups to Unix user and group IDs.
The clustering problem also adds other complications. For instance, as a member server in the domain, Samba needs to have the same join information on all nodes; that is, it needs the computer account password and the domain SID. In addition, the active SMB client connections and sessions on the nodes must be known across all nodes.
Samba's Trivial Database (TDB) [6] is a small, fast database similar to Berkeley DB and GNU DBM. TDB supports locking and thus simultaneous writing. Samba uses TDB internally in a vast number of places, including caching and other data manipulation tasks. Samba even uses the mmap() memory mapping mechanism to map TDB areas directly into main memory, which means that TDBs can act as fast shared memory.
As a first step in managing the challenge of a clustered file service, the Samba developers extended the TDB database to improve support for clustering scenarios. Cluster TDB (CTDB) made its debut in spring 2007; the CTDB Samba connection was originally only available in the form of the customized 3.0.25-ctdb version. The cluster code found its way into the default Samba distribution with version 3.2.0 in July 2008, but this initial effort was not complete. With Samba 3.3.0, which was released in January of this year, Samba now has full clustering support.
Ronnie Sahlberg is now the CTDB project maintainer. His CTDB Git branch [7] is the crystallization point for the official CTDB code. More recent CTDB versions support persistent TDBs and database transactions at the API level, making CTDB usable for any TDB-related tasks. Additionally, the developers have extended CTDB by adding a plethora of monitoring and high-availability features. The full CTDB history is on the Samba wiki [8].
Samba runs on all the nodes, and all the Samba instances appear as a single Samba server from the client's viewpoint. The Samba instances are configured identically and serve up the same file areas from the shared filesystem as shares. Thus, the CTDB model is basically a load-balancing cluster with high-availability functionality.
Behind the scenes, the CTDB daemon, ctdbd, runs on every node. The daemons negotiate the cluster TDB database metadata. Each CTDB daemon has a local copy (LTDB) of the TDB database that it maintains for CTDB; this copy does not reside on the cluster filesystem, but in fast local memory. Access to the data is handled by the local TDBs.
Samba uses TDB databases for various purposes. The database for locking, messaging, connections, and sessions only contains volatile data, but it is data that Samba reads and writes frequently. Other databases contain non-volatile information. Samba does not need write access to this persistent data very often, but read access is all the more critical. The data integrity requirements are thus stricter for the persistent databases than for the volatile ones. On the other hand, performance is more critical for volatile databases.
Samba uses two completely different approaches for managing volatile and persistent databases: In the case of the persistent databases, each node always has a complete and up-to-date copy. Read access is local. If a node wants to write, it locks the whole database in the scope of a transaction and completes its read and write operations within this transaction. Committing the transaction distributes all the changes to all other CTDB nodes.
For volatile data, on the other hand, each node just keeps the records it has already accessed in its local storage. This means that only one node, the data master, has the current data for a record. If a node wants to write or read a record, it first checks to see if it is the data master for the record and, if so, it accesses the LTDB directly. If not, it first picks up the current record data from the ctdbd, assumes the data master role, and then writes locally.
Because the data master always writes directly to the local TDBs, a single CTDB node is not slower than an unclustered Samba. The secret behind CTDB's excellent scalability is that the record data is only sent to a single node, instead of all nodes, for the volatile databases. After all, it's perfectly okay to lose the changes that one node makes to a volatile database if the node leaves the cluster. The information only relates to client connections on the node that has failed. The other nodes can't do anything with this data.
Performance tests on a cluster [9] confirm that the design is solid. An Smbtorture NBENCH test running on 32 clients is shown in Table 1. A single connection to a cluster node share achieves a transfer rate of 1.7GBps.

If a node fails, the volatile database is likely to lose its data master for a couple of records. The recovery process restores a consistent database status: One node is the recovery master that collects the records from all the other nodes. If it finds a record without a data master, it looks for the node with the newest copy. To allow this to happen, CTDB maintains a record sequence number in an extra header field, compared with the standard TDB; the number is incremented whenever the record is transferred to another node. At the end of the recovery process, the recovery master is the data master for every record in every TDB.
The recovery master is chosen by an election process, which uses what is known as a recovery lock. This recovery lock feature requires CTDB to support Posix fcntl() locks. Other, more complex election processes could potentially remove this requirement, but on the other hand, an intact cluster filesystem solves the error-prone split brain problem in CTDB.
| Tests |
|
If you run CTDB, you need a clustering filesystem that is mounted on all nodes, supports Posix fcntl() locking semantics, and guarantees consistent locking across all nodes. Which filesystem this is, or whether the storage capacity is provided by a SAN using Fibre Channel from a storage node attached via I-SCSI, or even from local disk partitions, is not important. CTDB is happy as long as it can mount the same filesystem on all nodes and can apply byte range locks to it. As a minimal case, a single machine with a local ext 3 partition would suffice. The ping-pong test shows whether a cluster filesystem is suitable for CTDB. The ping_pong.c code [15] creates a program that tests to see whether a clustering filesystem supports coherent byte-range locking. At the same time, it measures the locking performance, ascertains the integrity of simultaneous write access, and gauges memory mapping (mmap()) performance. Details of the ping-pong test are available from the Samba wiki [16]. The filesystem that performs best with CTDB in tests is IBM's proprietary GPFS [17]; CTDB and Samba Clustering owe much of their development to sponsoring by IBM. Red Hat's Global File System (GFS) Version 2 [18] also performed well. Watch out for CTDB packages in the next version of Fedora. Additionally, reports of deployment with the GNU Cluster File System (GlusterFS) [19] and Suns Lustre [20] are positive. The Oracle Cluster File System (OCFS2) [21] should be suitable when the Posix fcntl() locking implementation has been completed [22]. |
For a CTDB setup, the Samba developers recommend (at least) two - preferably physically separated - networks: a public network from which the clients will access the available services (Samba, NFS, ftp, ...) and a private network, which CTDB uses to handle internal communications within the cluster.
The network for the cluster filesystem can be a separate network, or it can be the same network that CTDB uses internally. A separate management network can turn out to be a good thing for, say, SSH logins on the nodes. Figure 1 shows the basic configuration of a CTDB cluster.
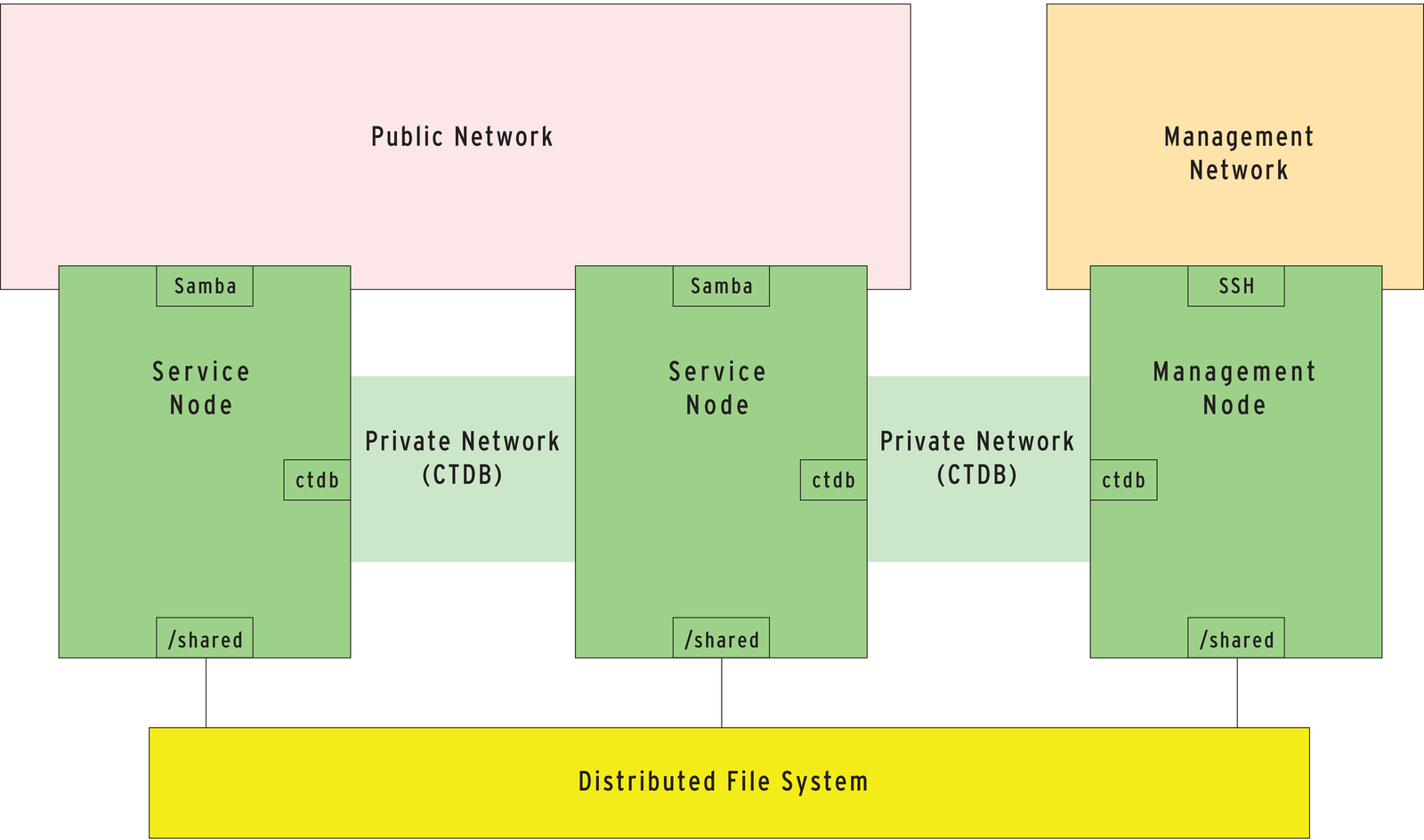
See the box titled "Downloading and Compiling CTDB" for information on how to add CTDB to your own Samba implementation. CTDB's central configuration file is /etc/sysconfig/ctdb. The really important thing is to specify the recovery lock file via the CTDB_RECOVERY_LOCK variable. On top of this, the admin user has to populate the /etc/ctdb/nodes file with the IP addresses of all the CTDB nodes on the private network (Listing 1). This file also has to be identical on all nodes.
| Downloading and Compiling CTDB |
|
The Samba project has been using the decentralized Git [10] code management system since late in 2007. The developers maintain Samba and CTDB on the server at git://git.samba.org or on the web front end [11]. The branches for the official Samba versions and the master developer branch are available from the git://git.samba.org/samba.git repository. The mirror [12] will even give you tarball snapshots of every single revision. The official CTDB sources are available from Ronnie Sahlberg's repository [7]. The repository at git://git.samba.org/obnox/samba-ctdb.git contains Samba versions with cluster extensions based on the official release branches - in particular, a production-ready cluster variant of Samba version 3.2 (v3-2-ctdb). As of this writing, the CTDB software will run on Linux and AIX. The normal sequence of commands will build and install the software: cd ctdb/ ./autogen.sh ./configure [options] make make install You don't need any special configure options. The normal --prefix allows the administrator to customize the installation directories. On RPM systems, you can generate a package directly from a Git checkout: cd ctdb/ Prebuilt CTDB and v3-2-ctdb RPMs are available for Red Hat [13] and other distributions [14]. |
| Listing 1: /etc/ctdb/nodes |
01 192.168.46.70 02 192.168.46.71 03 192.168.46.72 |
If you have Samba with cluster support (see the box "How-to Build Your Own Samba"), you will want to configure it with your own smb.conf parameters. The clustering = yes parameter enables clustering at run time. Without this parameter, the Samba clustering version will work like any old version of Samba without cluster support.
Despite what various pages of the Samba wiki say [23], you won't need to locate private dir on the cluster filesystem (well, maybe for a local smbpsswd). This information only applies to earlier versions of CTDB that could not handle persistent TDB databases, such as secrets.tdb and passdb.tdb in private dir. Current versions of CTDB automatically distribute the persistent TDBs over the cluster.
If you need group mappings, you must change the back end from the default of ldb to tdb with groupdb:backend = tdb.
Samba uses an identification code to store the locking information: smbd typically creates this code by stat()ing the file's device and inode number. However, the cluster setup needs an ID that is valid for multiple nodes because the device number is not invariable for the file in the cluster. The VFS fileid module provides an alternative approach to forming a file ID that is valid throughout the cluster. The vfs objects = fileid parameter in the corresponding configuration section enables the fileid module either globally or for a share. The value of the fileid:algorithm option in the [global] section configures the method, as in
vfs objects = fileid fileid:algorithm = fsid
| How-to Build Your Own Samba |
|
If you can not, or prefer not to, use prebuilt packages, you can build and install a cluster-capable Samba 3.3 from the source code using the standard sequence of commands: cd samba/source ./autogen.sh ./configure --with-cluster-support --with-ctdb=/usr/include --with-shared-modules=idmap_tdb2 [Options] ./make everything ./make install You only need to call autogen.sh if you are using a Git repository snapshot instead of the release tarball. The --with-ctdb= configure parameter specifies where the CTDB headers are on the system. Samba needs them to compile the code for communications with CTDB. If you have already installed CTDB from a package, /usr/include is normally okay. Building the cluster variant of the standard ID mapping module, idmap_tdb, adds idmap_tdb2 to the list of modules in --with-shared-modules=. The Samba team is currently working on merging idmap_tdb and idmap_tdb2 to support idmap_tdb in the cluster. One of the next Samba versions will probably resolve this issue. The commands cd samba/source ./packaging/RHEL-CTDB/makerpms.sh generate RPMs for Red Hat and SUSE systems directly from a Git checkout. |
To distribute public IP addresses across the cluster nodes you can use any of three options. For example, you can assign addresses statically without involving CTDB. In this case, CTDB can't play its high-availability card. Or, you can use a single IP address as the public cluster address in what is known as LVS mode and let the LVS master node distribute the address to the participating nodes. Setting the CTDB_LVS_PUBLIC_IP and CTDB_PUBLIC_INTERFACE variables in /etc/sysconfig/ctdb enables this mode.
The third method is to allow CTDB to dynamically assign multiple public IP addresses to the nodes. In combination with round-robin DNS upstream, this option adds load balancing and high availability to your CTDB cluster. To allow this to happen, you need to specify a file - typically /etc/ctdb/public_addresses - with the /etc/sysconfig/ctdb CTDB_PUBLIC_ADDRESSES variable on each node; the file contains the address pool with the netmasks and network interfaces that CTDB will assign to the nodes.
The address list does not need to be on every node, and it does not need to be the same on each node. Instead, you can take the network topology of your public network into consideration and create partitions. If a node fails, CTDB transfers its public IP addresses to other cluster nodes, which have these addresses in their public_addresses lists.
It is important to understand that load balancing and client distribution over the client nodes are connection oriented. If an IP address is switched from one node to another, all the connections actively using this IP address are dropped and the clients have to reconnect.
To avoid delays, CTDB uses a trick: When an IP is switched, the new CTDB node "tickles" the client with an illegal TCP ACK packet (tickle ACK) containing an invalid sequence number of 0 and an ACK number of 0. The client responds with a valid ACK packet, allowing the new IP address owner to close the connection with an RST packet, thus forcing the client to reestablish the connection to the new node.
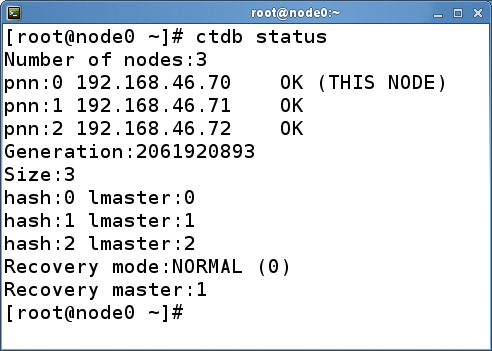
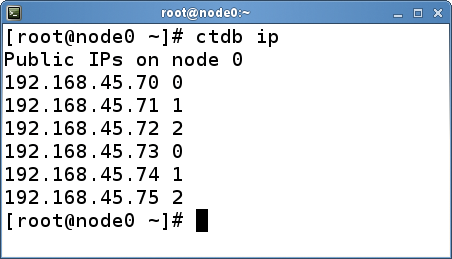
The CTDB package supplies two useful programs, ctdb and onnode, along with the daemon ctdbd. The ctdb tool is the client interface for CTDB cluster management. The most frequently used command is bound to be ctdb status, which outputs the general status of the cluster (Figure 2). The ctdb ip command shows the distribution of public IP addresses over the nodes (Figure 3). ctdb lets the admin trigger actions in the cluster, such as enabling or disabling individual nodes, adding or removing public IPs, forcing a recovery, or applying various tweaks. See the CTDB man page [24] for more information.
The onnode script is a very useful tool that lets you run commands on one or multiple nodes:
onnode node[,node...] Kommando
onnode gleans the node details from the /etc/ctdb/nodes file. The target can be one or multiple node numbers or a numeric range. Also all nodes (all), connected nodes (con), healthy nodes (ok), and the recovery master (rm) have symbolic names. onnode uses SSH to establish connections to the nodes; password-less SSH logins are thus a good idea on the internal CTDB network.
Using onnode, the admin can easily roll out service configuration files on the nodes or install the same software package after storing the data on the cluster filesystem beforehand:
onnode all cp /shared/smb.conf /etc/samba/smb.conf
Because onnode only needs to reference the nodes file, you can use it to launch ctdbd on all or selected nodes:
onnode 0,2-5 service ctdb start
For more, see the onnode man page [25].
To guarantee trouble-free monitoring and failover operations in CTDB, it is important not to use the interfaces or bind interfaces only configuration parameters to restrict the IP addresses or network interfaces you want Samba to listen on. Samba service monitoring requires Samba to listen on the wildcard address, 0.0.0.0, or :: for IPv6.
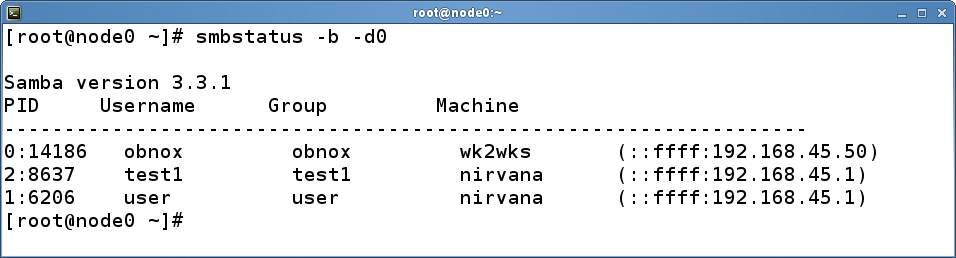
Listing 2 shows an example of a Samba configuration file that the admin would distribute to all the nodes in the cluster. The smbstatus shows the connections for all nodes in the cluster. To do so, it not only lists the process IDs of the smbd processes, but outputs their node number prefixes (Figure 4). Similarly, admins can influence the Samba daemons throughout the cluster using smbcontrol.
| Listing 2: smb.conf for a Cluster |
01 [global] 02 clustering = yes 03 netbios name = cifscluster 04 workgroup = mydomain 05 security = ads 06 passdb backend = tdbsam 07 08 idmap backend = tdb2 09 idmap uid = 1000000-2000000 10 idmap gid = 1000000-2000000 11 12 groupdb:backend = tdb 13 fileid:algorithm = fsname 14 15 [share] 16 path = /storage/share 17 vfs objects = fileid |
When running a Samba cluster, it doesn't make any sense to run the NetBIOS name service, nmbd, on multiple nodes - the broadcast would just suffer from a split personality. Also, the WINS service is not cluster-capable because Samba does not handle the wins.dat database with CTDB.
For the first time, and conditional on a freely available clustering filesystem that passes the ping-pong test, Samba 3.3 in combination with CTDB offers a highly scalable CIFS cluster that is easily installable for production use without the need for patches and workarounds. After the basic setup, registry-based configuration and the onnode script make managing the cluster a pleasant task. Read on for more on Samba's new registry configuration system.