
By Andreas Klein
The new C++ standard, which is informally known as C++0x, is still in the process of being hashed out, but many features of the next generation C++ have already made their way into the GNU compiler (GCC) versions 4.3 and 4.4. You can enable these features by entering the -std=c++0x option.
Many of these new features are mature enough to use without worries. Users of the influential Boost libraries [1] will be familiar with most of the changes because a fair share of the new standard is based on Boost. The technical details are available in the draft version of the C++ standard [2] and in the "Draft Technical Report on C++ Library Extensions" (TR1) [3]. Read on for a look at some of the most important changes in recent versions of GCC.
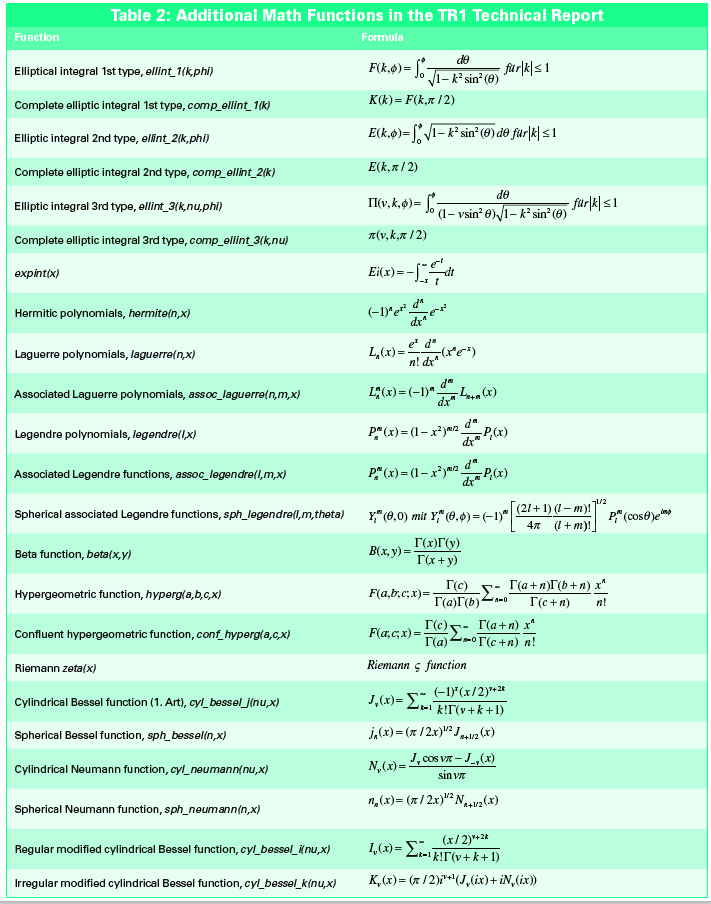
The C99 standard substantially raised the number of mathematical functions available. It stands to reason that all of these C functions should be available in C++. The cmath library under the new C++ standard incorporates the full set of C99 functions (Table 1), while defining many additional mathematical functions (Table 2). The new C++ standard also mandates that new C libraries, such as stdint.h (fixed-size integers) or fenv.h (direct access to the floating point unit), must be available in C++. The C++ names for these libraries are cstdint, cfenv, and so on. The definitions are all bundled in the std namespace.

Several new containers also inhabit the new standard, starting with the hash-based variants of the associative containers set, multiset, and map. These containers were originally planned for the older standard, but the developers dropped them for want of time. The new standard includes the unordered_set and unordered_map libraries, which define the hash-based containers unordered_set, unordered_multiset, and unordered_map. The unordered name component indicates that a comparative operator is not needed in order to use these containers. The unordered_set class definition is as follows:
template<class Value,
class Hash=hash<Value>,
class Pred=std::equal_to<Value>,
class Alloc=std::allocator<Value> >
class unorderd_set {
...
}
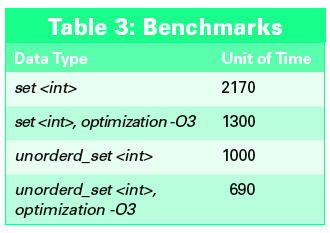
With the template parameters, you can select the allocator (as with any standard container), specify the comparative predicate (this defaults to ==), and specify the hash function. If no specific information concerning the data is available, the default settings are a useful choice. Hash-based containers are faster than their tree-based counterparts (Table 3). The array (a lightweight class for a C array) and forward_list (a singly linked list) classes are also new.
The current C++ standard includes auto_ptr, a pointer that deletes an object automatically when it loses its value. The auto_ptr class has many restrictions. Each object can have only one owner, and strange things can happen in copying operations. More specifically, you cannot store an auto_ptr in a standard container. Effectively, auto_ptr causes more problems than it solves. The new C++ standard gets rid of auto_ptr and introduces improved, intelligent pointers. The new intelligent pointers are:
The intelligent pointer collection should lead to more efficient programming as developers learn the nuances of the various new options.
Most extensions to the new C++ standards only relate to the libraries; however, a number of changes affect the core of the language. Most of these changes are cosmetic. For example, the parser can now handle angled brackets in nested template definitions, such as vector<vector<int>> (previously, developers had to put a space between the final ">>" to avoid confusion with the left shift >> operator).
Templates with a variable number of parameters are probably the biggest change to the core. One possible application of this concept is that of implementing a typecast tuple class, as shown in the following example:
template<typename... REST>
struct tuple;
template<>
struct tuple<>{};
template<typename T>
struct tuple<T>{ T car;};
template<typename T, typename... REST>
struct tuple<T,REST...> { T car; tuple<REST...> cdr;};
int main() {
tuple<int, char> t;
t.car = 1;
t.cdr.car = 'a';
}
The new standard library tuple provides a far more sophisticated tuple class.
The random generator taken from C was designed for very simple simulations. The new rand library has far more extensive capabilities. For example, you can choose from several methods of generating pseudo-random numbers. All parameters are freely selectable, but if you are not an expert in the random generator field, you are probably better off using one of the many preset methods. Besides the methods for generating pseudo-random numbers, you will also find a large selection of distribution methods (uniform distribution, Gaussian distribution, etc.).
The GCC implementation of rand is still not perfect; however, the differences between it and the C++ standard to come are more or less cosmetic and likely to disappear in future versions. For example, the std::uniform_real_distribution class is still called std::uniform_real, and it still lacks a default_random_engine.
If you make heavy use of templates, you are likely to encounter the following problem sooner or later: You want to write a template class or function, but the code only works if the type has additional properties. The type_traits library gives you an elegant approach to testing for this issue:
template<typename T> T f(T a) {
static_assert(std::is_floating_point<T>::value == true, "f needs a floating point argument!");
...
}
The static_assert command is also new. static_assert defines an assertion at build time. The standard copy command is a complex application of type traits. A naive implementation always calls the copy constructor of the objects. A more sophisticated implementation uses the faster memcpy for simple types.
An implementation of copy is shown in Listing 1, although it is still somewhat simplified. If you have access to the internal structure of the standard container, you can and should handle vector iterators separately.
| Listing 1: Implementation of copy |
01 template<typename I1, typename I2, bool b>
02 I2 copy_imp(I1 first, I1 last, I2 out, const integral_constant<bool, b>&)
03 {
04 while(first != last)
05 *(out++) = *(first++);
06 return out;
07 }
08 template<typename T>
09 T* copy_imp(const T* first, const T* last, T* out, const true_type&)
10 {
11 memcpy(out, first, (last-first)*sizeof(T));
12 return out+(last-first);
13 }
14 template<typename I1, typename I2>
15 inline I2 copy(I1 first, I1 last, I2 out)
16 {
17 typedef typename iterator_traits<I1>::value_type value_type;
18 return copy_imp(first, last, out, has_trivial_assign<value_type>());
19 }
|
All of the features mentioned thus far are available in version 4.3 of GCC, which is included by most distributions. The features that follow were added to the latest 4.4 version. The most important change here is improved multithreading support. The thread class from the thread library provides thread management methods.
Listing 2 shows how to start new threads and how a parent thread waits for a child thread to terminate.
| Listing 2: Starting Threads |
01 vector<thread *> active_threads(thread_num);
02 // Starte threads
03 for(unsigned int tn=0; tn<thread_num; tn++)
04 active_threads[tn] = new thread(worker,tn);
05 // Wait for child threads
06 for(unsigned int tn=0; tn<thread_num; tn++)
07 {
08 active_threads[tn]->join();
09 delete active_threads[tn];
10 }
|
The mutex library defines locking mechanisms. A simple example of the use of mutex is shown in Listing 3.
| Listing 3: Example of mutex |
01 mutex access_the_file; // Globale Variable
02 void a_function_that_runs_in_several_threads()
03 {
04 ...
05 access_the_file.lock();
06 // This area is not simultaneously accessible by multiple threads
07 ...
08 access_the_file.unlock();
09 ...
10 }
|
Additionally, support for the OpenMP parallel programming API is improved. The previous OpenMP specification required loop variables in a parallelized for loop to be of the int type. This restriction made it difficult to use OpenMP with STL containers. Version 3.0 of the OpenMP standard lifts this restriction; now, loops with STL iterators can be parallelized, as well as loops with int type loop variables, for example:
std::vector<int> vec(128);
#pragma omp parallel for default(none) shared(vec)
for (std::vector<int>::iterator it = vec.begin(); it < vec.end(); it++)
{
// work with iterator it
}
STL containers previously had the disadvantage of not supporting initialization in C array style, as in int a[] ={1,2,3}. The new C++ standard changes this, as in std::vector<int> a{1,2,3}; the inializer_list class is used to implement this new syntax.
The development of the new C++ standard is not complete, and GCC is still catching up with some key new features of the standard. New regular expression components are not implemented in GCC 4.4.0; however, development is making rapid progress.
The part of the standard that governs atomic functions still seems to be under active development. Many function names were changed last year, and others were added.
| INFO |
|
[1] Boost C++ Libraries: http://www.boost.org
[2] "Working Draft, Standard for Programming Language C++": http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2009/n2857.pdf [3] "Draft Technical Report on C++ Library Extensions": http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2005/n1836.pdf |