
By Bruce Byfield
GNU/Linux is designed to be a hands-on operating system. For that reason, most of its configuration files and system logs are written in plain text, making them easy to read from the command line. If you want to alter these files while logged in as the root user, you'll want to use a file editor such as vi, emacs, or nano. But often you won't want to make changes, you'll just want to look quickly to gather information or to see whether the system is operating the way it should.
To help you view information, GNU/Linux includes a number of view commands. For a glimpse into short files, cat might be enough for you. However, for most purposes, you'll want to try more or, preferably, less. If you are especially interested in the start or end of a file, then head or tail might be the tool to use. The basics of all these commands are easy to learn, all the more so because many use similar options, or at least use similar features.
Its name tells the story of the original purpose of the cat command, which is short for "concatenate." In other words, the command is designed to join files. Although concatenating is still listed in numerous summaries as the main purpose, I suspect that most people use the command today solely for its secondary purpose of reading short files.
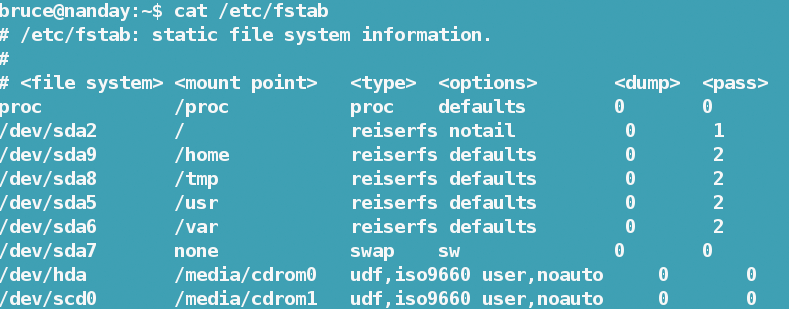
Perhaps the main reason cat is so popular is that the syntax is so easy (Figure 1). To view a file, all you need to do is enter the command followed by the file you want to view. For example, if I want to view the list of mounted devices on my system, I type cat /etc/fstab.
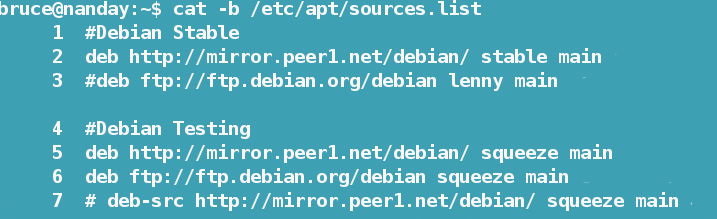
Still, cat does offer a few more options. If you have just edited your list of repositories in Debian or Ubuntu and received a message of an error in a particular line, you could manually count lines from the top, or - assuming you know how - open /etc/apt/sources.list in vi with the lines numbered. Instead, you could just use the command cat -b /etc/apt/sources.list (Figure 2). This command numbers only the lines with content and ignores blank lines. If the blank lines matter, you can replace -b with -n.Other options for cat mark the formatting characters for tabs, line endings, and non-printing characters. Additionally, you have options to show various combinations of these characters, but most of the time, the only option you likely need is -A, which shows all of them.
Although cat is easy to use, its main disadvantage is that it is not convenient for files that have more lines than your terminal can display in a single screen. Any longer, and you have to scroll. More importantly, if a file has more lines than the history of your virtual terminal, you might miss the top of the file. Because of these disadvantages, many people prefer to use one of the other viewing options.
The more command is a slightly more sophisticated view than cat and is better suited to files of more than 20 lines. Its main virtue is that it displays information a screen at a time and eliminates the chance that you will miss information the way you could with cat.
The simplest way to use more is to view a file directly. For example, a user called allan could view his system mail by entering more /var/mail/allan.
Just as often, you see another command with a pipe that redirects the output of the command through more. One of the most common examples of this is a search command like find or grep, when you know you are likely to have a large number of results. For instance, if I want to locate a large number of PNG graphics in the current directory and have the results piped through more, I would type find ".png" | more.
When the results fill the screen, the highlighted message --More - appears at the bottom of the list. To go to the next screen of results, I would press Enter. If this basic message is not enough for you, you can use the -d option to expand it (Figure 3). Other useful options include +<number>, in which you replace <number> with the number of the line from which to start displaying, and +/<number>"<string>"<number>, which shows only lines in which "<string>" occurs.
![]()
Once more is running, you have several navigation options via the keyboard. To search for a text string, use /"<string>", or you can press the Space bar to display the next screen of text. As you browse, you can press Enter to advance one line at a time or enter z<number> to specify the number of lines to jump forward, as well as set a new default for the number of lines to advance (if you press just z, the default is 1 unless you've changed it). When you are finished viewing, pressing q will return you to the command prompt.
The options to the more command make cat look simplistic by comparison. However, as you use more, you will find it has one considerable disadvantage: You cannot scroll back, so a screen is gone once it's cleared the top of the monitor, unless you exit more and restart it. The truth is, more is little used today. The latest date on its man page is June 29, 1988, and even that refers to more as "primitive." Nowadays, the file viewing command that most people use is the more sophisticated less.
The less command's name is a geeky joke. According to some theories, "less is more" - that is, simplicity is often more elegant than complexity. The command's name refers to this catchphrase - and, really, what better way to indicate that it was written as a replacement for more? In fact, if either one is defined in your environment (which is a topic for another day), there is even a LESS_IS_MORE variable that causes any attempt to use more to use less instead.
The name becomes even more appropriate when you learn that less is an improvement on more in several ways. Although it uses the same command format as more, unlike more, less allows you to scroll back. Additionally, it offers more options, and because it does not read the entire input file before displaying anything, it is faster to start, too.
Both less and more have some common functions but do not always use the same options to access them. Just as with more, you can use both +<number> and +/"<string>" with less (see above), but the results of +/"<string>" are highlighted in the output.
The less command has an overwhelming number of other options as well. Some useful ones for the average user include -I, which ignores the difference between lower and upper case when you are searching for a specific string, and -V, which underlines tabs, line endings, and non-printing characters. The -w option highlights the first line after the text is advanced if you have moved forward a single line, and -W highlights the first line when you move forward more than one line. Be warned, though, that not all these options are enabled in any particular version of Bash.
The navigation commands are a similar mixture of new and strange for veterans of more. Both commands use the Space bar to move forward one screen, but less allows you to scroll forward half a screen as well by pressing d. Additionally, you can use b with less to scroll back one complete screen, or u to scroll back half a screen. Similarly, you can use z<number> to specify the number of lines to move forward, or y<number> for the number of lines to scroll back. The Up and Down arrow keys navigate backward and forward, and the Left and Right arrow keys move from one end of a long line to another.
Adding /"<string>" searches for results, just as more does, but adding Ctrl+k to the start of the string highlights all instances of the string (Figure 4). If necessary, you can use Esc+u to remove the highlighting.

Yet another handy feature in less is the ability to work with multiple files. If you do, then you can navigate between them with :n and :p. Then, just as with more, you can use q to close the command.
Although less can be powerful, sometimes it - and even more or cat - can be imprecise or overkill for what you want. In many circumstances, you might want to turn to head or tail instead.
As the name implies, head looks at the first 10 lines of a file by default. Probably its greatest use is to let you identify a file quickly. For instance, if you were logged in as the root user and unsure what information /var/log/scrollkeeper.log contained, head might be just enough for you to find that answer.
In contrast, tail looks at the last 10 lines of a file and often writes them to the command line. This glimpse is useful because system log files generally write the latest information at the bottom of the file, and it is ideal for ongoing monitoring for troubleshooting. All you need to do is open a terminal on an unused virtual desktop and continue your work on another, glancing occasionally at the output from tail to see what is happening.
If 10 lines are not enough, use -<number> to change the number of lines displayed in either head or tail. If you want to see the file header, which can contain such information as the name of the file or information that identifies its format, then use the -v (verbose) option (Figure 5). Alternatively, you can suppress the head with -q (quiet).

Additionally, tail has several commands to help you to manipulate troubleshooting information. If you add -f, information will be added to the output as it becomes available. Should the monitored file be inaccessible or become so, you can use --retry to ensure that you keep monitoring it (or, conversely, to ensure that the reason you haven't received new data isn't that something has happened to the file). To control how often the file is scanned and reduce the amount of system resources used by tail, add -s<SECONDS>.
Still another useful feature is --pid<PID>, which stops tail from running if the system process with the specified ID stops running. Most likely, you will need to run the top or ps commands as the root user to find the PID of the process you want to monitor.
These options are not the only ones you can use with the viewing commands. In particular, less has dozens more, some of which you are unlikely to use unless you have advanced skills in system administration and troubleshooting. Still, the ones mentioned here should help you use the commands efficiently without getting bogged down in too much memorization. Take a look at the man page for the command of your choice. The view commands are not complicated - even if the way options are described in their man pages sometimes are.