
By Ben Martin
Creating a software RAID using the Linux kernel is becoming easier and easier. With a call to mdadm and pvcreate, you can be well on your way to using LVM on top of a RAID 5 or RAID 10 device. In fact, the procedure for setting up a RAID system has gotten so simple that many users routinely click through the commands without too much consideration for how the various settings might affect performance.
When it comes to RAID, however, the default settings aren't always a prescription for optimum performance. As you will learn in this article, tailoring your filesystem parameters to the details of the RAID system can improve performance by up to 20%.
| Details |
|
For this article, I focus on the XFS and the venerable ext3 filesystems. I have no particular connection to either filesystem and use them both in different circumstances. My tests used a RAID 5 across 4,500GB disks. To be exact, I used three Samsung HD501LJ 500GB drives and a single Samsung HD642JJ 640GB drive. One of the joys of Linux software RAID is that you can spread your RAID over disks of different sizes, as long as the partition you use on the larger disk is the same size as on the smaller. The RAID used 343,525,896 blocks on each disk, resulting in a usable filesystem size of just under 1TB when created on the RAID. Testing was performed on an Intel Q6600 running on a P35 motherboard. The Linux kernel allows its filesystems to use barriers to protect one sequence of write commands from the next. When the filesystem requests a barrier, the kernel will ensure that everything the filesystem has written up to that point is physically on disk. This is a very slow operation because of complications like flushing the entire disk cache, in many cases, and similar actions. By default, ext4 and XFS use filesystem barriers if they can. Because ext3 does not use barriers, I disabled barriers in the XFS tests so that I would be closer to comparing apples to apples. Another reason I disabled barriers is that LVM does not support them, so I needed to remove barriers to compare XFS performance accurately with and without LVM. |
Filesystems are deceptively complex pieces of software. At first, a filesystem might appear rather simple: Save a file and make sure you can get it back again. Unfortunately, even writing a small file presents issues, because the system caches data in many places along the way to the disk platter. The kernel maintains caches, your disk controller might have a small memory cache, and the drive itself has many megabytes of volatile cache. So, when a filesystem wants to make sure 100KB is really on the disk, a fairly complex and often slow operation takes place.
When you use a RAID 5 system on four disks, the Linux kernel writes three blocks of real information to three different disks and then puts the parity information for those three blocks on the fourth. This way, you can lose any one of the four disks (from disk crash) and still have enough information to work out what the original three blocks of information were. Because filesystems and disk devices use "blocks," RAID experts call these three data blocks "chunks" to avoid confusion.
With four disks, you have three data chunks and one parity chunk. So the stripe size is three chunks and the parity stripe size is one chunk. The stripe size is very important, because the filesystem should try to write all the chunks in a stripe at the same time so that the parity chunk can be calculated from the three chunks that are already in RAM and written disk. You might be wondering what happens if a program only updates a single chunk out of the three data chunks.
To begin, I'll call the chunk being written chunk-X and the parity for that stripe chunk-P. One option is to read the other data chunks for the stripe, write out chunk-X, calculate a new parity chunk-P, and write the new chunk-P to disk. The other option is for the RAID to read chunk-P and the existing, old, chunk-X value off the disk and work out a way to change chunk-P to reflect the changes made to chunk-X.
As you can see, things become a little bit more complicated for the RAID when you are not just sequentially writing a large contiguous range of data to disk. Now consider that the filesystem itself has to keep metadata on the "disk" on which you create it. For example, when you create or delete a file, the metadata has to change, which means that some little pieces of data have to be written to disk.
Depending on how the filesystem is designed, reading a directory also calls for reading many little pieces of data from disk. Therefore, if the filesystem knows about your chunk size and stripe size, it can try to arrange the metadata into chunks that will make life easier for the RAID and thus result in improved performance.
The key to aligning the parameters of your filesystem and RAID device is to set the stripe and chunk size correctly to begin with when creating the filesystem with the mkfs command. If you are using XFS and creating the filesystem directly on the RAID device, then mkfs.xfs takes care of that step for you. Unfortunately, if you use LVM on top of your RAID and then create an XFS filesystem on an LVM logical volume, mkfs.xfs does not align the parameters for optimum performance.
| RAID 5 |
|
For this article, I assume you have some familiarity with the concepts of RAID and RAID configuration in Linux. If you are new to Linux RAID, you'll find several useful discussions online [1]. Redundant Array of Inexpensive Disks (RAID) is a collection of techniques for fault-tolerant data storage. The term first appeared in the 1988 landmark paper "A Case for Redundant Arrays of Inexpensive Disks," which was written by David Patterson, Garth Gibson, and Randy Katz [2]. Fault-tolerant data storage systems provide a means for preserving data in the case of a hard disk failure. The easiest way to protect the system from a disk failure (at least conceptually) is simply to write all the data twice to two different disks. This approach is roughly equivalent to what is often called disk mirroring, and it is known within the RAID system as RAID 1. Although disk mirroring certainly solves the fault tolerance problem, it isn't particularly elegant or efficient. Fifty percent of the available disk space is devoted to storing redundant information. The original paper by Patterson, Gibson, and Katz (as well as later innovations and scholarship) explored alternative techniques for offering more efficient fault tolerance. A favorite fault-tolerance method used throughout the computer industry is Disk Striping with Parity, which is also called RAID 5. RAID 5 requires an array of three or more disks. For an array of N disks, data is written across N - 1 of the disks, and the final disk holds parity information that will be used to restore the original data in case one of the disks fails. The amount of disks in the array devoted to redundant information is thus 1/N, and as the number of disks in the array increases, the penalty associated with providing fault tolerance diminishes. |
The command below creates a RAID device. The default chunk size of 64KB was used in a RAID 5 configuration on four disks. Creating the RAID with the links in /dev/disk/by-id leaves a little less room for the error of accidentally using the wrong disk.
cd /dev/disk/by-id mdadm --create --auto=md --verbose --chunk=64 --level=5 --raid-devices=4 /dev/md/md-alignment-test ata-SAMSUNG_HD501LJ_S0MUxxx-part4 ata-SAMSUNG_HD501LJ_S0MUxxx-part4 ata-SAMSUNG_HD501LJ_S0MUxxx-part4 ata-SAMSUNG_HD642JJ_S1AFxxx-part7
For both ext3 and XFS, I ran two tests: one with a fairly routine mkfs command and one with which I tried to get the filesystem to align itself properly to the RAID. These four filesystems are ext3, ext3 aligned to the RAID (ext3align), XFS (xfs), and XFS aligned to the RAID (xfsalign), all created with and without explicit alignment of the stripe and chunk size. The only extra option to mkfs.xfs I used for the XFS filesystem was lazy-count=1, which relieves some contention on the filesystem superblock under load and is highly recommended as a default option.
The mkfs command to create the aligned ext3 filesystem is shown below. I have used environment variables to illustrate what each calculation is achieving. The stride parameter tells ext3 how large each RAID chunk is in 4KB disk blocks. The stripe-width parameter tells ext3 how large a single stripe is in data blocks, which effectively becomes three times stride for the four-disk RAID 5 configuration.
export RAID_DEVICE=/dev/md/md-alignment-test export CHUNK_SZ_KB=64 export PARITY_DRIVE_COUNT=1 export NON_PARITY_DRIVE_COUNT=3 mkfs.ext3 -E stripe-width=$((NON_PARITY_DRIVE_COUNT*CHUNK_SZ_KB/4)),stride=$((CHUNK_SZ_KB/4) $RAID_DEVICE
The command to create the aligned XFS filesystem is shown in the code below. To begin with, notice that the sunit and swidth parameters closely mirror stride and stripe-width of the ext3 case, although for XFS, you specify the values in terms of 512-byte blocks instead of the 4KB disk blocks of ext3.
mkfs.xfs -f -l lazy-count=1 -d sunit=$(($CHUNK_SZ_KB*2)),swidth=$(($CHUNK_SZ_KB*2*$NON_PARITY_DRIVE_COUNT)) $RAID_DEVICE
I used both bonnie++ and IOzone for benchmarking. Many folks will already be familiar with bonnie++, which provides benchmarks for per-char and per-block read/write as well as rewrite, seek, and file metadata operations like creation and deletion.
IOzone performs many tests with different sizes for data read and write and different file sizes, then it shows the effect of file size and read/write size on performance in the form of three-dimensional graphs.
Looking first at bonnie++ results, Figure 1 shows the block read and write performance. Note that because mkfs.xfs can detect the RAID configuration properly when you create it directly on the RAID device, the performance of xfs and xfsalign are the same, so only xfs is shown.
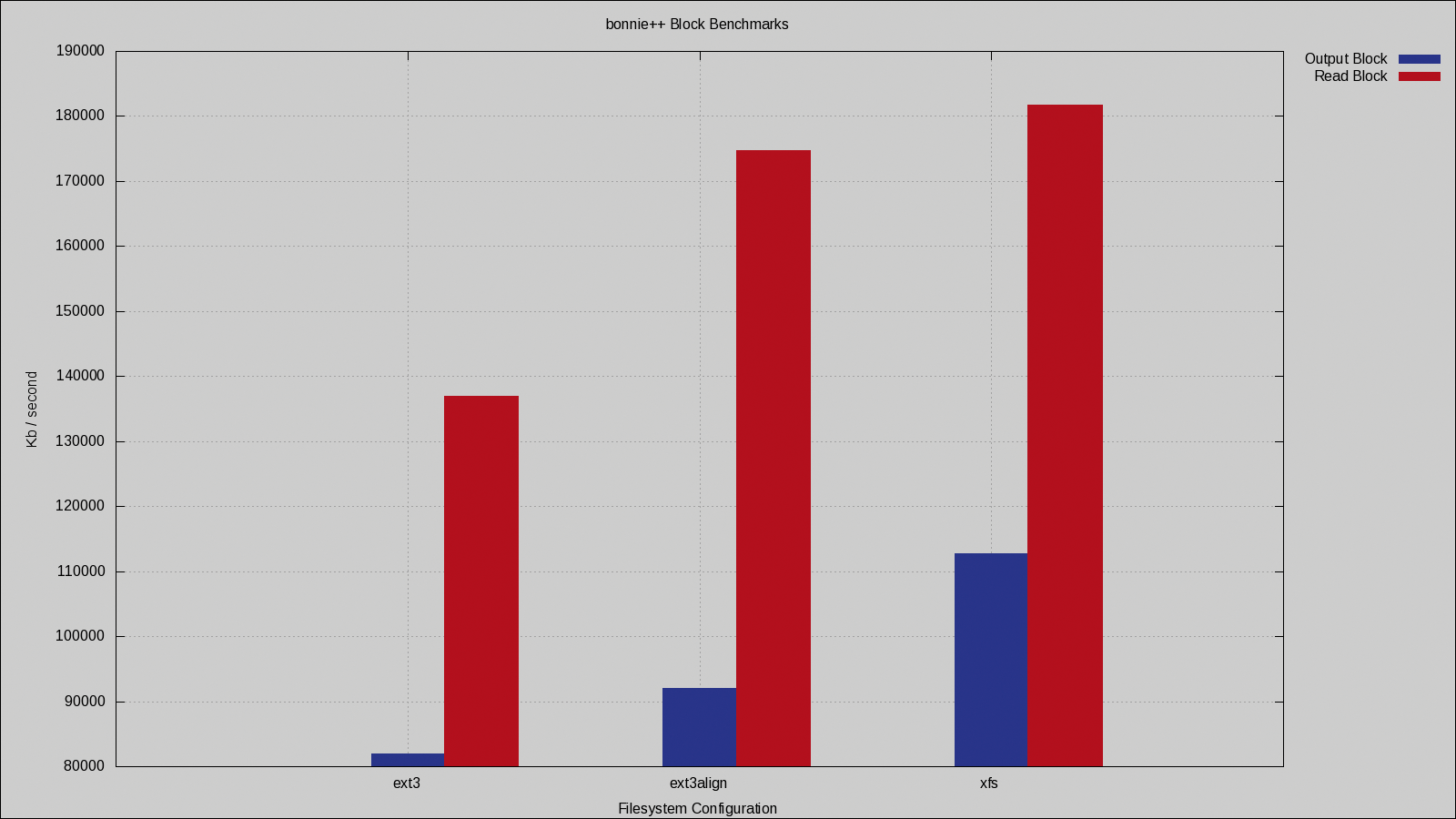
As you can see, setting the proper parameters for ext3 RAID alignment (see the ext3align column in Figure 1) provides a huge performance boost. An extra 10MB/sec block write performance for free is surely something you would like to have.
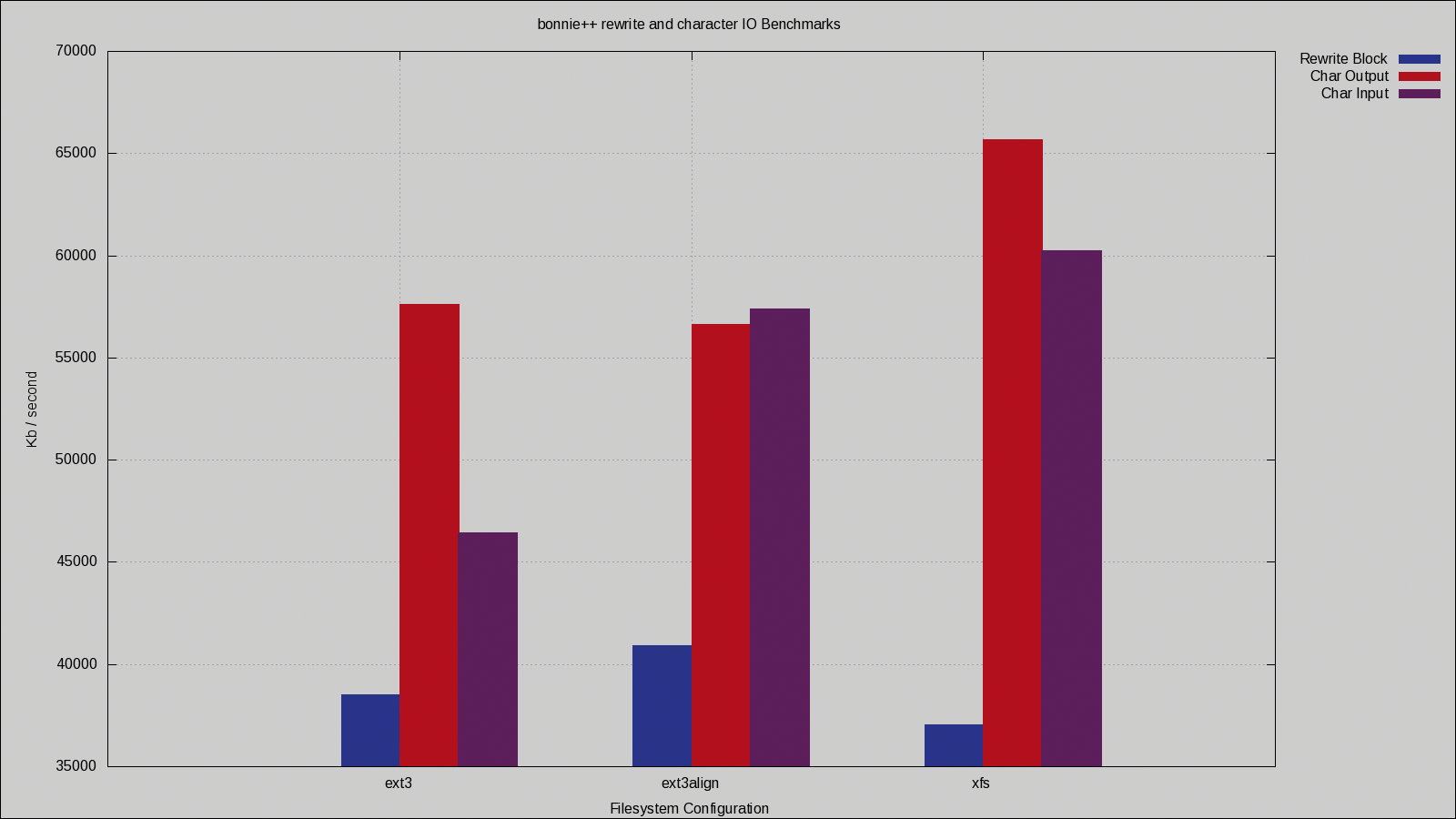
The bonnie++ rewrite performance is a very important metric if you are looking to run a database server on the filesystem. Although many desktop operations, such as saving a file, will replace the entire file in one operation, databases also tend to overwrite information in place to update records.
The rewrite performance is shown in Figure 2. Although the results for character I/O are less important than for block I/O, the additional performance for block rewrite gained by aligning the ext3 filesystem properly amounts to a 2MB/sec difference, or 6% additional performance for free.
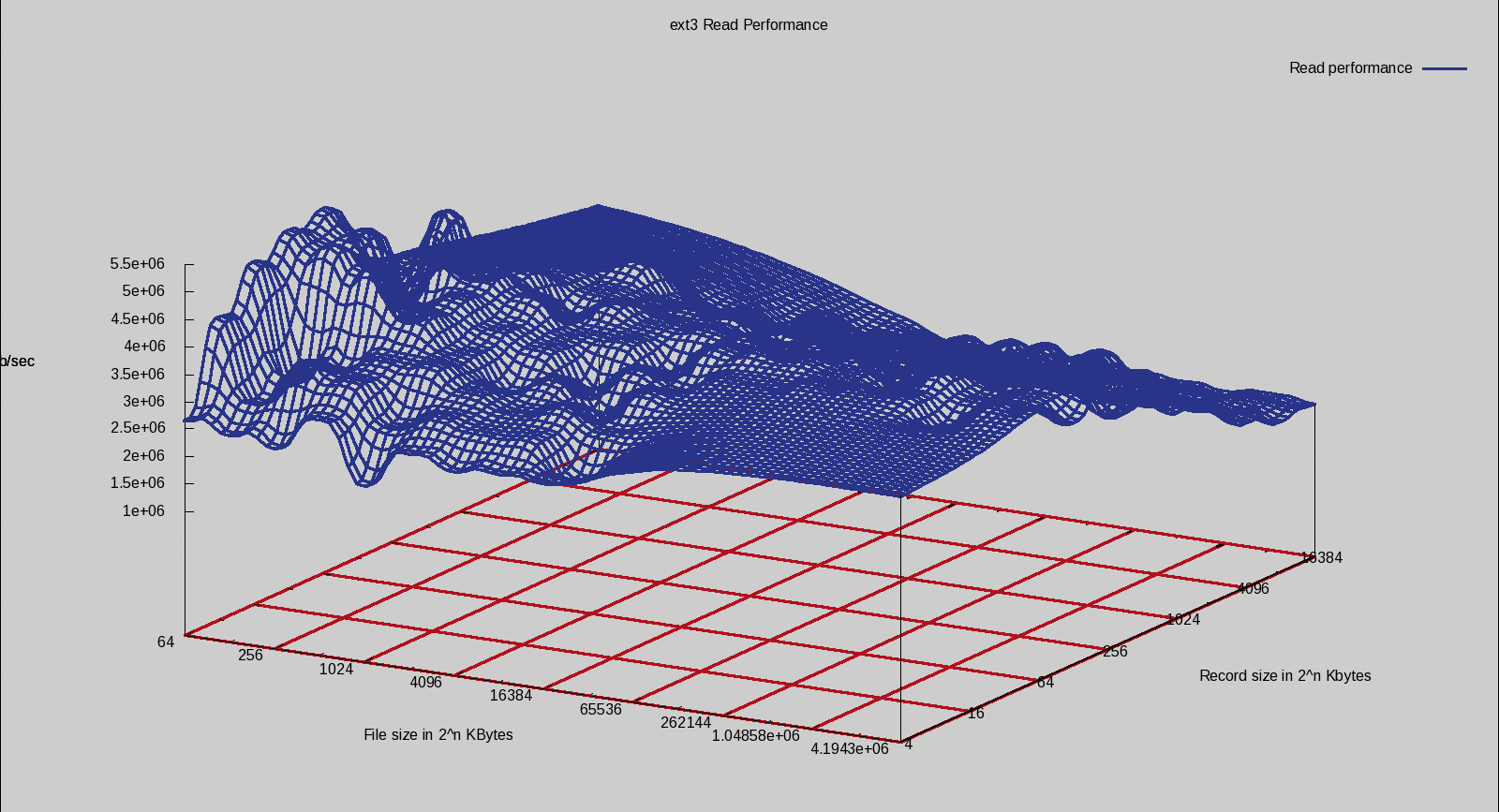
Although the IOzone results for ext3 and ext3aligned are very similar, a few anomalies are worth reporting. The read performance is shown in Figure 3 and Figure 4. Notice that ext3align does a better job reading small chunks from smaller files than ext3 does. Strangely, performance drops for ext3align with 16MB files.

When you create an XFS filesystem directly on a software RAID device, mkfs.xfs is smart enough to work out the chunk and stripe sizes for you and configure the XFS filesystem optimally. Unfortunately, if you are using a hardware RAID card or using LVM between XFS and the software RAID, it is up to you to make sure the filesystem is created optimally.
I created both a hand-aligned XFS and a XFS filesystem with default parameters to test what difference, if any, this made to performance. Many folks use LVM on top of a RAID device for improved system management and flexibility. Being able to store many filesystems on a single RAID device is very convenient. I retested the ext3 configurations to see whether using the extra LVM layer sapped much performance.
Figure 5 shows the performance of ext3 and XFS on the same RAID device. For the "raw" configuration, the filesystem is created directly on the RAID device. In the "lvm" configuration, an LVM physical volume is created on the RAID device, and an LVM logical volume is created on the LVM physical volume. The filesystem is then created on the LVM logical volume.
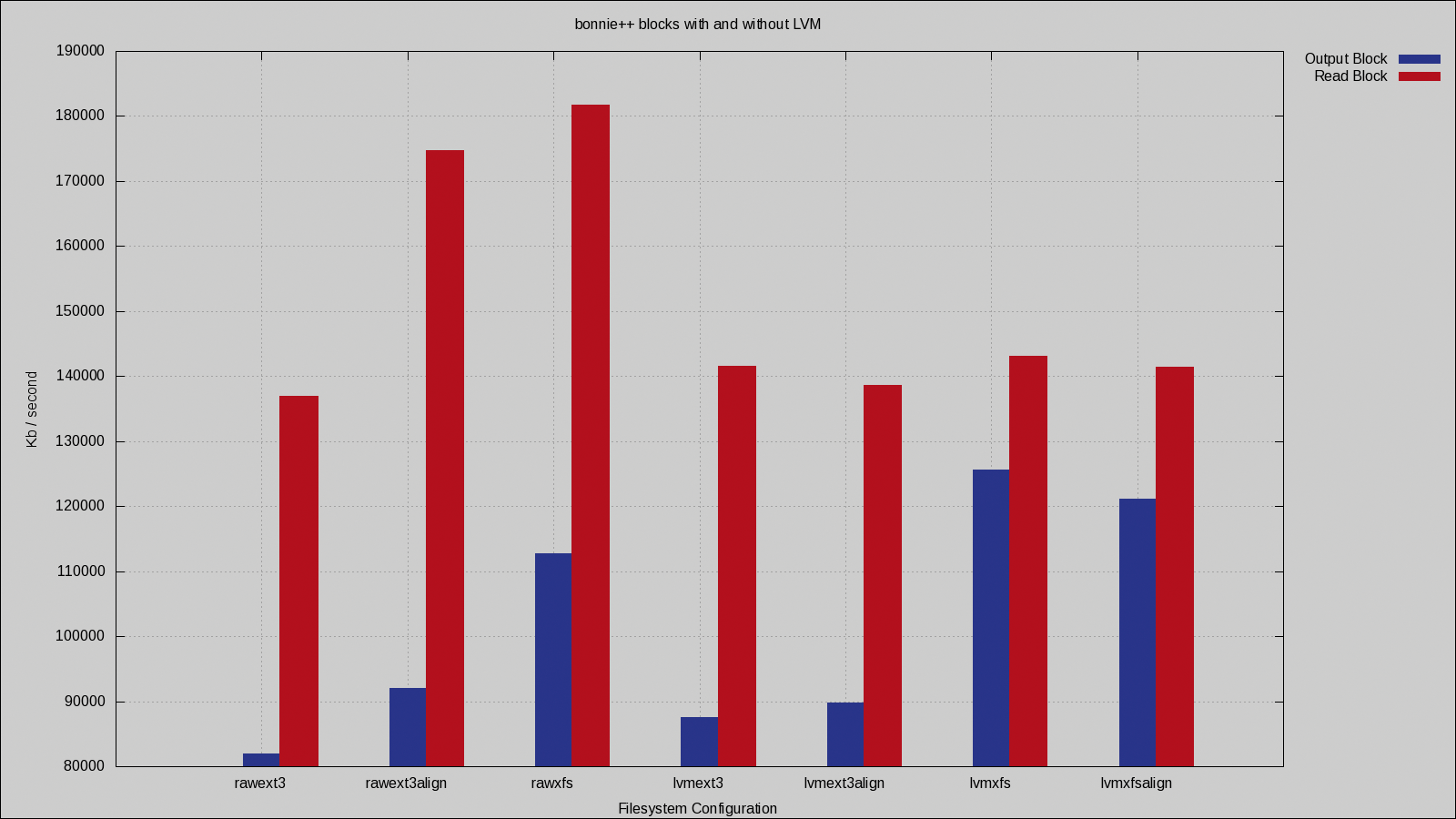
Notice that the gains in read performance resulting from alignment of the ext3 filesystem are gone and that read performance across all filesystems is identical. Aligning the stripe on the XFS filesystem actually made write performance worse than with no alignment attempt. LVM itself appears to be limiting block read performance, so attempts to align the filesystem are not resulting in any performance differences.
Interestingly, though, block output for XFS was greatly improved by using LVM. XFS attempts to delay writes to files for as long as possible. The delayed writes might be the reason that XFS is faster at writing with the use of LVM - if LVM maintains a write cache of its own, then perhaps data can be streamed out to disk from that cache more effectively when it is presented in large chunks by the filesystem. Notice that the read performance is significantly reduced when LVM is used.
Figure 6 shows the block rewrite bonnie++ benchmark. Here you can see that the gains in correctly aligning the ext3 filesystem have been preserved to some degree, with the aligned ext3 filesystem being almost 1MB/sec faster than the unaligned ext3 on LVM. The differences for correct alignment of ext3 are less when using LVM, however: 1MB/sec for LVM compared with about 2.5MB/sec on raw RAID.
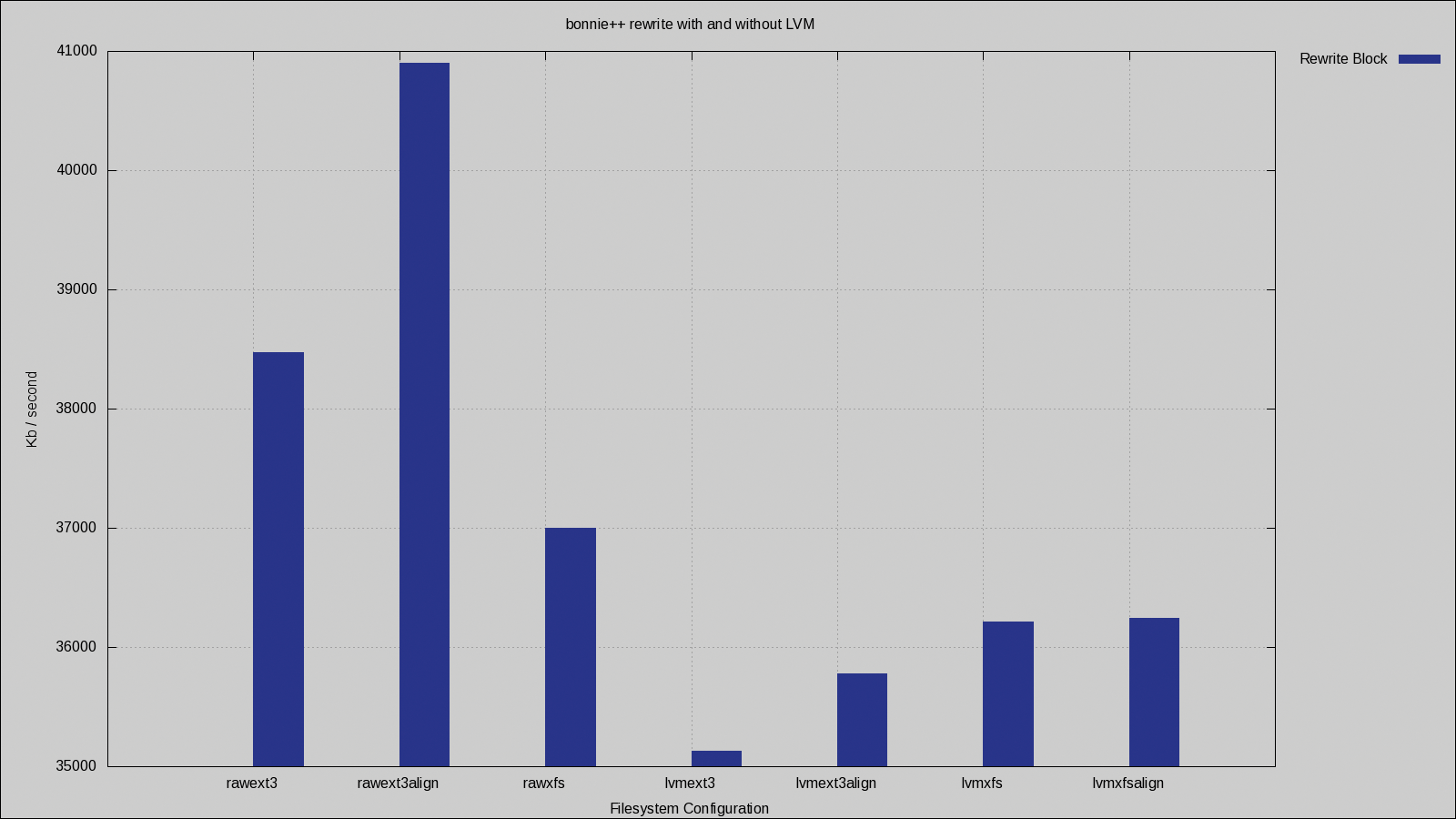
Although differences of a megabyte per second might not seem so important, in the worst case, this means the aligned ext3 on raw RAID would be more than 15% faster than unaligned ext3 on LVM. When you consider that this is running on the same machine and same disks, 15% free performance is something you might like to have.
Because it can be somewhat difficult to compare two three-dimensional graphs by eye, I decided to graph not the two original datasets, but the difference between the aligned and non-aligned datasets. In Figure 7, I'm showing you the (ext3aligned - ext3) IOzone random read performance for LVM. Although it is not completely in favor of the ext3aligned filesystem, you can see significant performance peaks where the ext3aligned filesystem is much faster in the 256 to 4,096KB file size range (to the left of the figure).
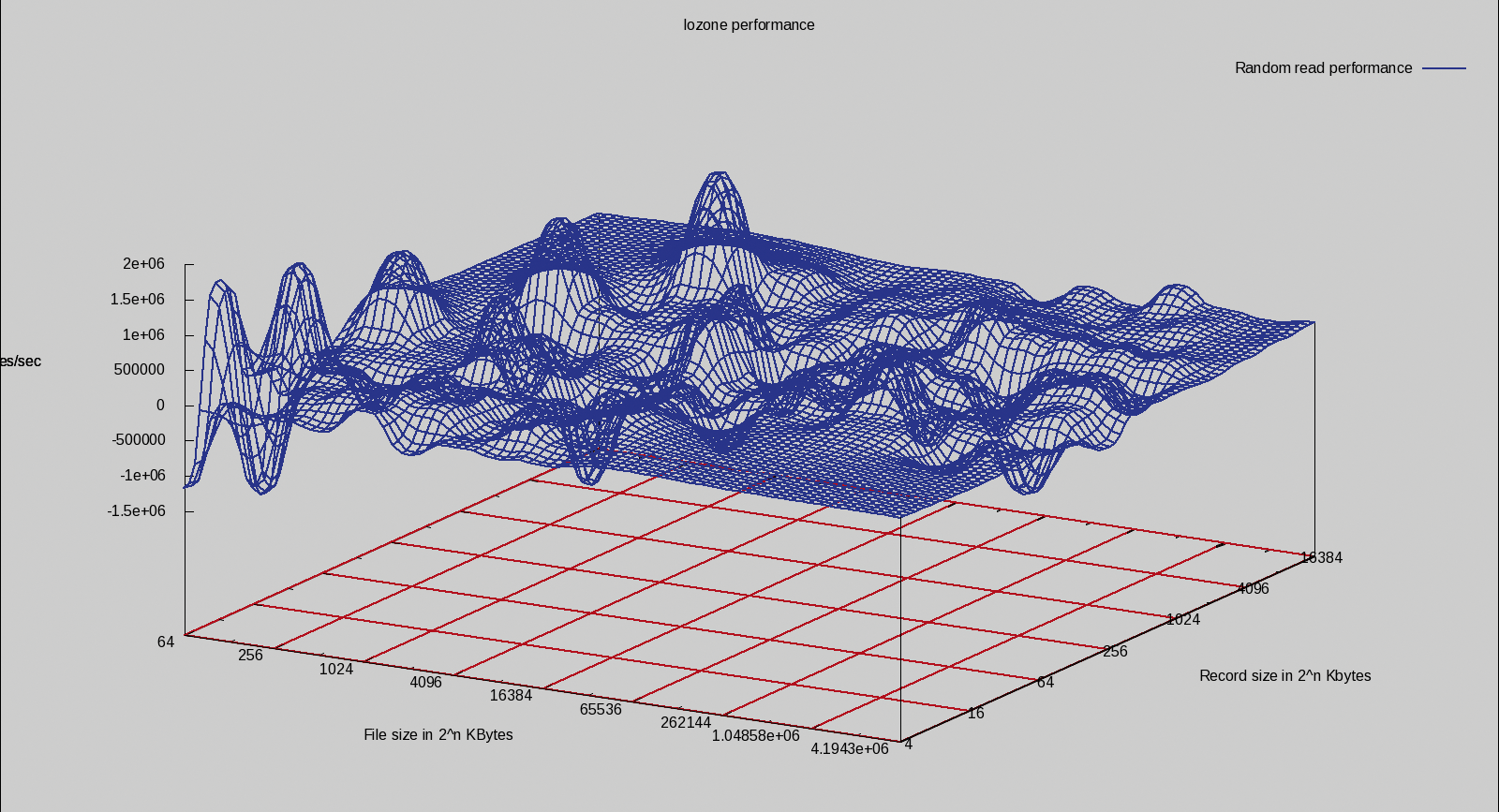
Figure 8 shows the difference of random write performance for ext3 with and without alignment on LVM. Notice that the peaks and troughs are in the same places, although the extremes are not as pronounced. The dips in performance for the ext3align filesystem are almost eradicated.
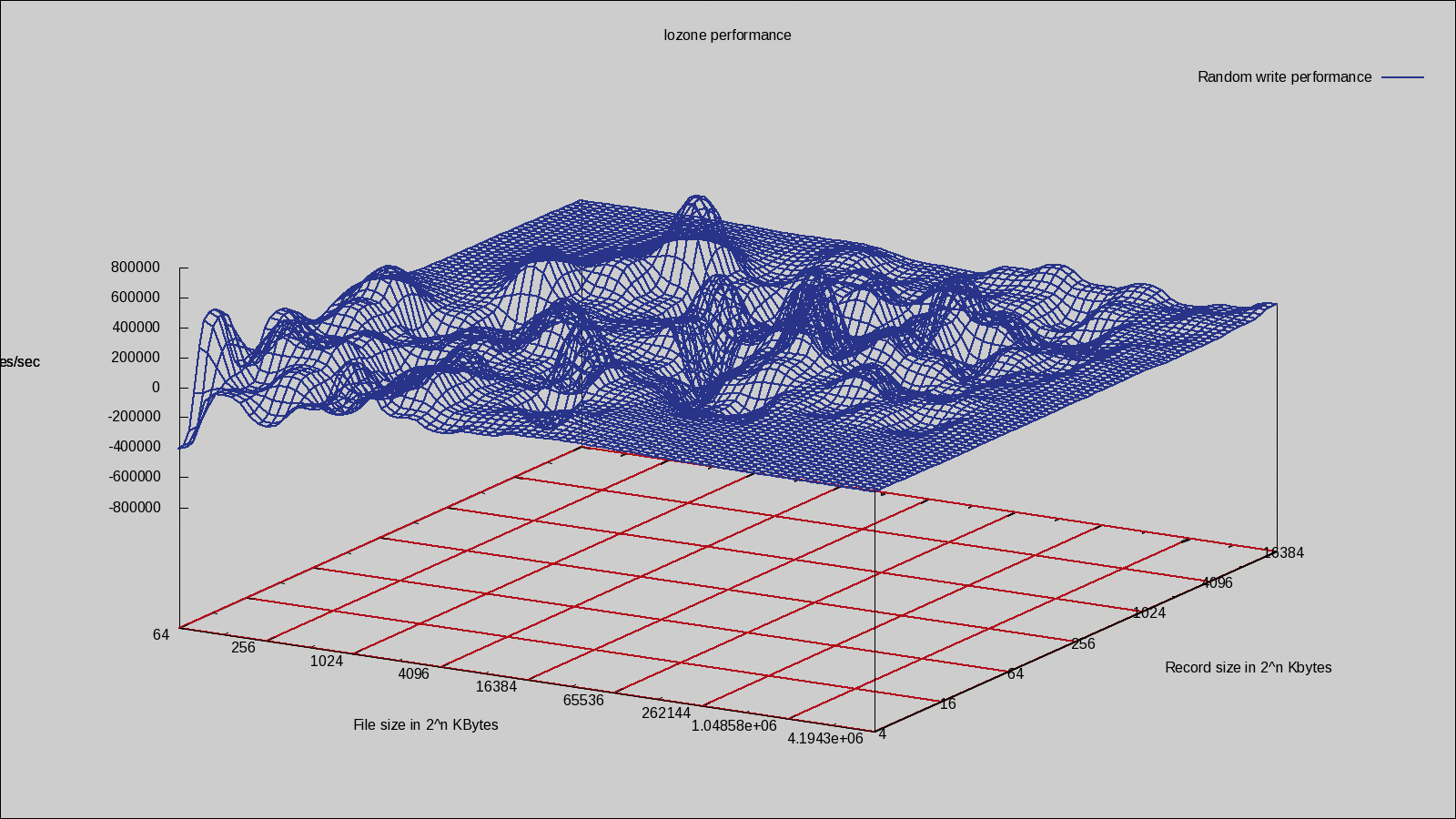
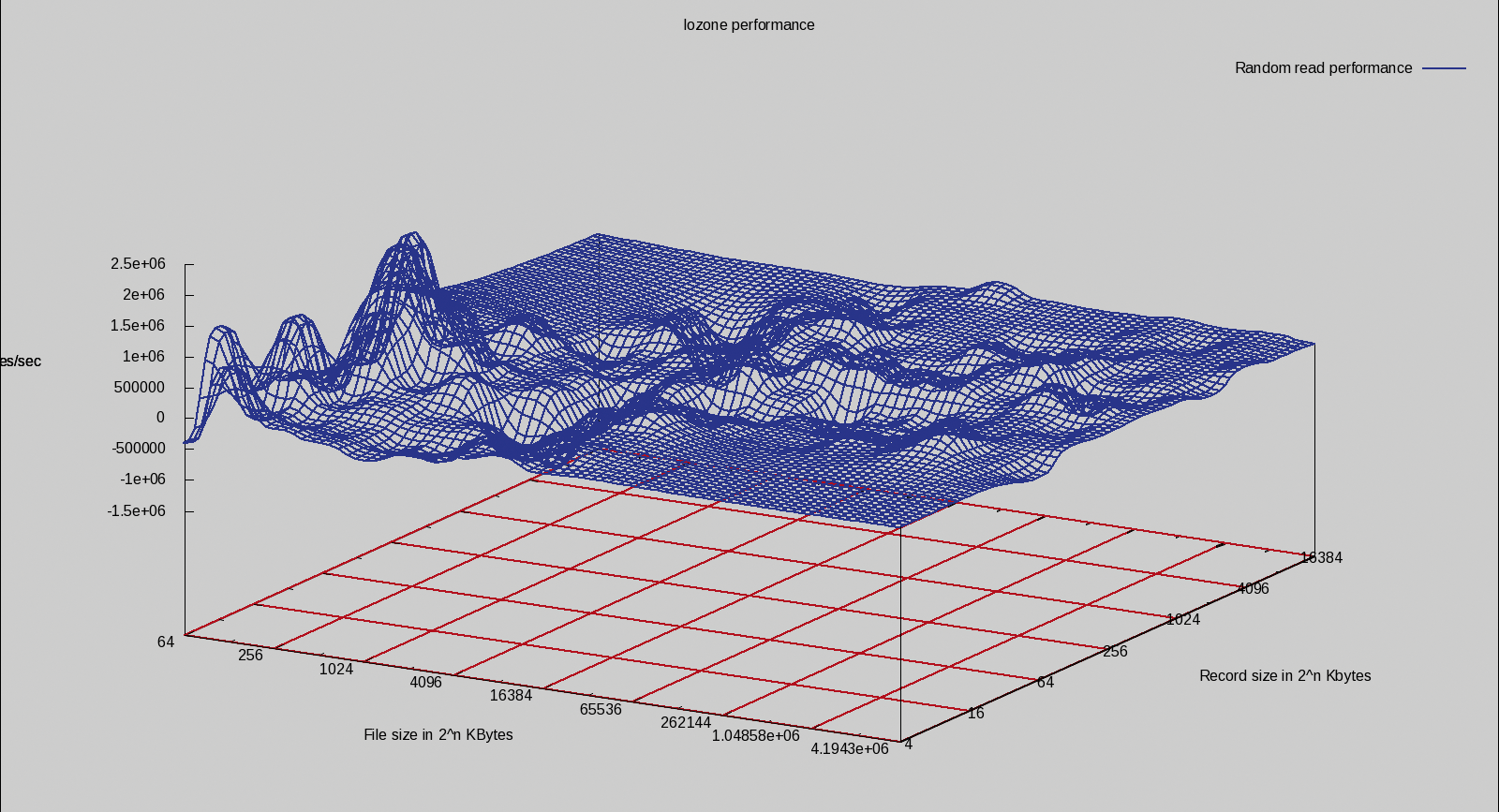
Figure 9 shows XFS with alignment and without alignment when created on LVM for random read. Notice that the graph is much less busy for XFS compared with ext3 (shown in Figure 7). Random reads of smaller files are much faster on a properly aligned XFS filesystem, as the peaks on the left side of Figure 9 show. For smaller writes to 4MB files, an aligned XFS filesystem is slightly slower than an XFS filesystem created with the default mkfs.xfs arguments (difference graph not shown). The aligned XFS is faster for the larger writes to files of 16 to 256MB.
| Digging a Deeper Hole |
|
The Linux kernel has supported the ext4 filesystem since v2.6.28. Performance improvements over its successor, ext3, include 48-bit block addressing. One downside of specifying the RAID stripe size at mkfs time is what happens when you add an extra disk to an existing RAID. All of a sudden, you have four data disks on your RAID 5 instead of three, and the stripe alignment that the filesystem is using is incorrect. Luckily, ext4 has a mount option to allow you to set the stripe size at mount time, so if you add a disk to a RAID or extend an LVM volume, you can tell ext4 what you've done so the filesystem can optimize future activity to fit the modified disk configuration. Unfortunately, specifying the sunit and swidth options when mounting an XFS filesystem is only effective when the filesystem is created directly on a RAID device. So if you use LVM on your RAID and add a disk, you can't tell XFS about the change at mount time. This is once again a case in which XFS does not play well with LVM. When using LVM, metadata is stored at various abstraction layers. For example, pvcreate has various options for setting the size of metadata and data alignment. So far, I have not found tweaking pvcreate to have the same effect as setting filesystem stripe parameters, but that question is open to further investigation. |
As this study shows, you can get 10% to 20% extra performance if you align your ext3 filesystem to the RAID array chunk and stripe size. Although the differences were not as significant for XFS, proper alignment of XFS can make a large difference to the performance of file creation and deletion.
In summary:
The actual benefits that you reap by taking these steps will vary depending on your configuration, but regardless of the numbers, aligning your filesystem parameters with the RAID system is a good strategy for achieving better performance, especially on ext3 and ext4 filesystems.
| INFO |
|
[1] OSDL's Linux RAID: http://linux-raid.osdl.org/index.php/Linux_Raid
[2] "A Case For Redundant Arrays of Inexpensive Disks (RAID)," by David A. Patterson, Garth Gibson, and Randy H. Katz. http://www-2.cs.cmu.edu/~garth/RAIDpaper/Patterson88.pdf |
| THE AUTHOR |
|
Ben Martin has been working on filesystems for more than 10 years. He completed his PhD and now offers consulting services focused on libferris, filesystems, and search solutions. |