
By Tim Schürmann
Brad Fitzpatrick was frustrated: Although the LiveJournal.com blogger platform that he had founded - and for which he had done most of the development work - was up and running on more than 70 powerful machines, its performance still left much to be desired. Not even the database server cache size of up to 8GB seemed to help. Something had to be done, and quickly. The typical measures in scenarios like this are to generate some content up front or to cache pages that have been served up previously. Of course, these remedies require redundant storage of any elements that occur on multiple pages - a sure-fire way of bloating the cache with junk. If the systems ran out of RAM, things could be swapped out to disk, of course, but again this would be fairly slow.
In Fitzpatrick's opinion, the solution had to be a new and special kind of cache system - one that would store the individual objects on a page separately, thus avoiding slow disk access. Soon, he gave up searching for a suitable solution and designed his own cache. The servers that he wanted to use for this task had enough free RAM. At the same time, all the machines needed to access the cache simultaneously, and modified content had to be available to any user without any delay. These considerations finally led to memcached, which reduced the load on the LiveJournal database by an amazing 90 percent, while time accelerating page delivery speeds for users and improving the resource utilization on the individual machines.
Memcached [1] is a high-performance, distributed caching system. Although it is designed to be application-neutral for the most part, memcached is typically used to cache time-consuming database access in dynamic web applications.
Now major players such as Slashdot, Fotolog.com, and, of course, its creator LiveJournal.com rely on memcached for faster web performance. Since the initial development, LiveJournal.com has been acquired and sold various times, and memcached, which is available under a BSD open source license, is now the responsibility of Danga Interactive.
Setting up a distributed cache with memcached is easy. You need to launch the memcached daemon on every server with RAM to spare for the shared cache. If necessary, you can enable multiple cache areas on a single machine. This option is particularly useful with operating systems that only give a process access to part of the total available RAM. In this case, you need to start multiple daemons that each grab as much memory as the operating system will give them, thus using the maximum available free memory space for the cache.
A special client library provides an interface to the server application. It accepts the data to be stored and stores it on one of the existing servers using a freely selectable keyword (Figure 1). The client library applies a sophisticated mathematical method to choose which of the memcached daemons is handed the data and asked to park it in its RAM.
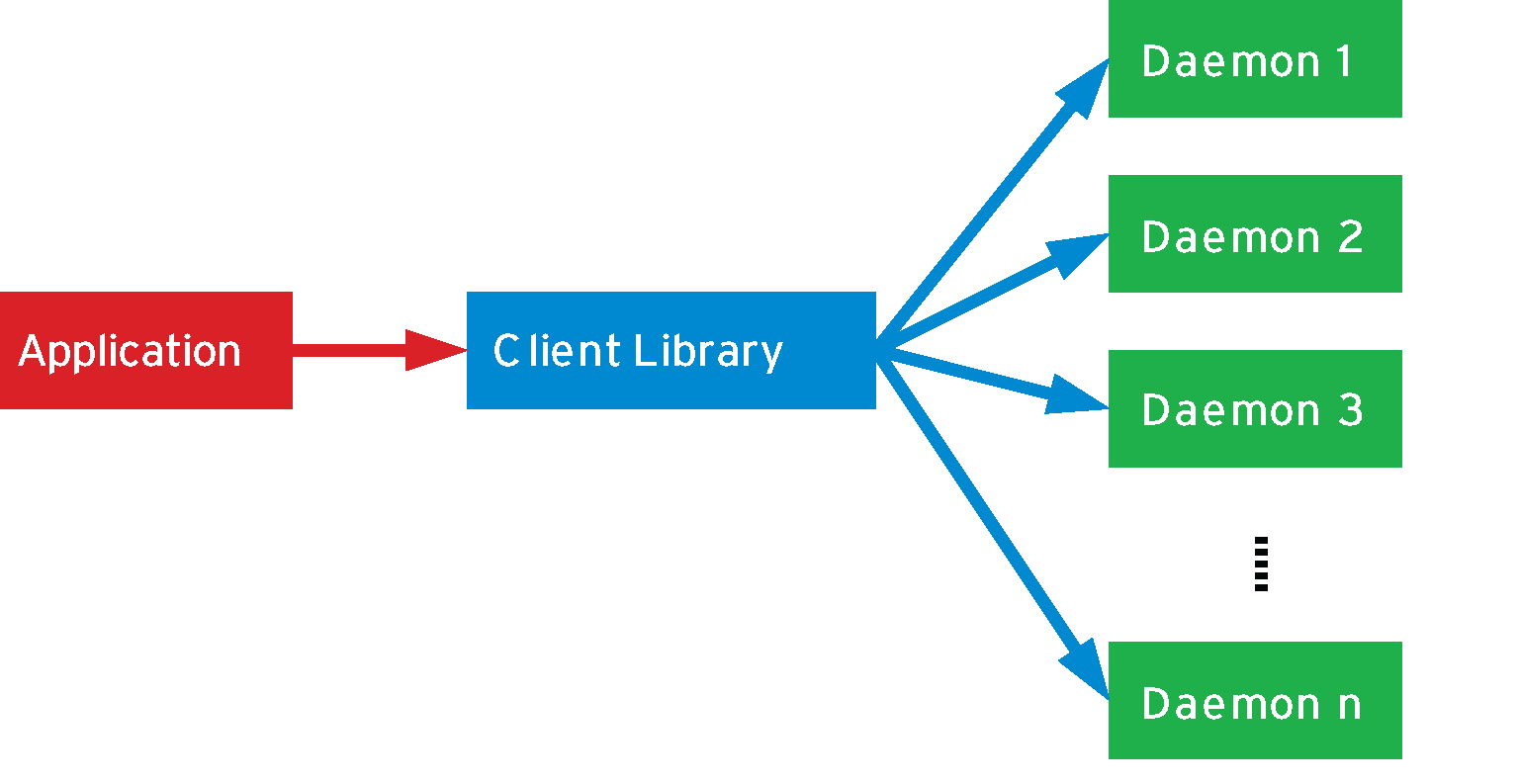
You could compare this procedure with the cloakroom in a theater: You hand your coat to the attendant behind the counter and call out a number. The attendant takes your coat, locates the right stand, and hangs up your coat on the peg with your chosen number. At the end of the performance, the whole process is repeated in reverse: you tell the cloakroom attendant - I mean, the client library - the number again, and the client runs off to the corresponding daemon, takes the data off the peg, and delivers the data to your application.
The whole model is very much reminiscent of a distributed database, or a distributed filesystem. But when you are working with memcached, you should always remember that it is just a cache. In other words, the cloakroom attendant is not reliable and has trouble remembering things. If the space is insufficient for new elements, one of the daemons will dump the least-requested data to free up some space. A similar thing happens if a memcached daemon fails - in this case, any information it had in storage just disappears. In other words, you wouldn't get your coat back at the end of the performance, and the application is forced to talk to the database again. The memcached system does not do redundancy, but there is no need for it: After all, it's just a cache, and its job is to store information temporarily and hand it out as quickly as it can. In line with this philosophy, it is impossible to iterate against all the elements on the cache or to dump the whole content of the cache trivially onto disk.
Danga Interactive posts the memcached daemon on its homepage for users to download [1]. The only dependencies it has are the libevent library and the corresponding developer package. The daemon is easily built with the normal three-step procedure:
configure make sudo make install
Some of the major distributions have pre-built, but typically obsolete, memcached packages in their repositories. After completing the installation, the following command - or similar - launches the daemon:
memcached -d -m 2048 -l 192.168.1.111 -p 11211 -u USERNAME
This command launches memcached in daemon (-d) mode, telling it to use 2048MB of RAM for the distributed cache on this machine (-m 2048). The daemon listens for client requests directed to port 11211 at IP address 192.168.1.111. The daemon also needs to know the account it should use, although you can omit the -u option to run the daemon with the account of the user logged in.
Security experts are probably frothing at the mouth: By default, any user on a Linux system can launch their own memcached daemon. To prevent this, you need to take steps, such as withdrawing access privileges - just one of multiple security issues that memcached deliberately avoids (more of that later).
After lining up all the daemons, you need to choose one of the numerous client libraries, which are now available for many programming and scripting languages: In some cases you even have a choice of packages [2]. If you prefer to create your own client, you will find a detailed description of the underlying protocol in the memcached wiki at the Google Code site [3].
Because memcached is often used to accelerate web applications, most people are likely to opt for a PHP client. For more information on using memcached with C and C++, see the box titled "libmemcached."
| libmemcached |
|
The most popular memcached client library for C and C++ applications right now is libmemcached [4] - which should not be confused with its now discontinued predecessor libmemcache (without a "d" at the end). Even if you are not a C or C++ programmer, you might want to take a look at the package; it contains a couple of interesting (server) diagnostic command-line tools. For example, memcat retrieves the data for a key from the cache and outputs the results at the console, memstat queries the current status of one or multiple servers. To build libmemcached, you need both a C and a C++ compiler on your system; apart from that, it's business as usual: ./configure; make; make install. A simple cache query is shown in Listing 2. |
| Listing 2: A Simple Cache Query |
01 #include <memcached.h>
02 #include <string.h>
03 #include <stdio.h>
04
05 main()
06 {
07 /* create memcached_st structure (containing all the basic information for the memcached servers) */
08 memcached_st *mcd = memcached_create(NULL);
09
10 /* add a server: */
11 memcached_server_add(mcd, "127.0.0.1", 11211);
12
13 /* Push object into cache: */
14
15 char *key = "key";
16 size_t keylength = strlen(key);
17 char *value = "information";
18 size_t valuelength = strlen(value);
19 time_t expiration = 0;
20 uint32_t flags = 0;
21
22 memcached_add(mcd, key, keylength, value, valuelength, expiration,flags);
23
24 /* Retrieve object from cache: */
25
26 memcached_return errovariable;
27
28 char *result = memcached_get(mcd, key, keylength, &valuelength, &flags, &errovariable);
29
30 /* Print object: */
31 printf("Cache: %s\n", result);
32
33 /* Flush: */
34 memcached_free(mcd);
35 }
|
The basic approach is the same for any language: After locating and installing the correct client library, the developer needs to include it in their own program. The following line creates a new Memcached object using PHP and the memcache client from the PECL repository, as included in the Ubuntu PHP5-memcache package:
$memcached = new Memcached;
Following this, a function call tells the library on which servers memcached daemons are listening:
$memcache->connect('192.168.2.1', 11211) or die ('No connection to memcached server');
From now on, you can use more function calls to populate the cache with your own content:
$memcache->set('key', 'test', false, 10);
This instruction writes the test string to the cache, with key as the key, and keeps the entry for 10 seconds. Key lengths are currently restricted to 250 characters - this restriction is imposed by the memcached daemon.
To retrieve the data, you need to pass the key in to the client library and accept the results passed back to you:
$result = memcache->get('key');
Listing 1 shows the complete PHP script.
| Listing 1: Simple Cache Query in PHP |
01 <?php
02 $memcache = new Memcache;
03 $memcache->connect('localhost', 11211) or die ('No connection to memcached server');
04
05 $memcache->set('key', 'datum', false, 10);
06
07 $result = $memcache->get('key');
08
09 var_dump($result);
10 ?>
|
The option of writing multiple sets of data to the cache while retrieving them is interesting. The client library automatically parallelizes your request to the memcached servers. Unfortunately, some client libraries do not provide this function; this PHP example
$multiple = array( 'key1' => 'wert1', 'key2' => 'wert2', 'key3' => 'wert3' ); $memcache->setMulti($multiple);
is only supported by the memcached client (with a "d" at the end).
For existing web applications, the question is always where you can best deploy and use memcached. Profiling gives you the answer: Database queries that really stress the server are best routed via the cache. Listings 3 and 4 show you what this looks like in real life: Before querying the database, the code checks to see whether the requested information is available in memcached. A query only occurs if the information isn't found.
| Listing 3: Database Query Without memcached ... |
01 function get_user($userid)
02 {
03 $result = mysql_query ("SELECT * FROM users WHERE userid = '%s'", $userid);
04 return $result;
05 }
|
| Listing 4: ... and After Introducing memcached |
01 $memcache = new Memcache;
02 $memcache->connect('servername', 11211) or die ('No connection to memcached server');
03 ...
04 function get_user($userid)
05 {
06 $result = memcache-> get("user" + $userid);
07 if(!$result)
08 {
09 $result = mysql_query ("SELECT * FROM users WHERE userid = '%s'", $userid);
10 memcache->add("user" + $userid, $result);
11 }
12 return $result;
13 }
|
To avoid the need for another query, the results are stored in the cache. To keep the cache up to date, the information from each write operation is also cached. In Listing 4, the keys are built by combining the word user with the ID for the user account - this is a common strategy for generating unique keys.
This approach makes it easy to integrate memcached with your own applications, but you need to be aware of the pitfalls, which do not become apparent until you look under the hood.
Experienced programmers will probably already have noticed that memcached uses a dictionary internally; some programming languages call this an associative array. Like a real dictionary, this data structure stores each value under a specific key(word). The memcached system implements its dictionary in the form of two subsequent hash tables [5]. First, the client library accepts the key and runs a sophisticated mathematical function against it to create a number or hash. The number tells the library which memcached daemon it needs to talk to. After receiving the data, the daemon uses its own hash function to assign a memory allocation for storing the data. The mathematical functions are designed to return exactly the same number for a specific key. This approach guarantees extremely short search and response times. To retrieve information from the cache, the memcached system simply needs to evaluate the two mathematical functions. Data transmission across the network accounts for most of the response time.
Because the client library decides which daemon stores which data, all of the machines involved need to have the same versions of the same libraries. A mix of versions can cause clients to use different hash functions and thus store the same information on different servers, which would cause inconsistency and mess up the data. If you use the libmemcached C and C++ library, you need to pay special attention to this because it offers a choice of several hash functions.
On top of this, each client uses a different serialization method. For example, Java uses Hibernate, whereas PHP uses serialize. In other words, if you are not just storing strings, but also objects, in the cache, shared use based on different languages is impossible - even if all the clients use the same hash function. The libraries are also allowed to choose their compression methods.
The cache handles parallel requests without losing speed. In a theater, several attendants could walk through the aisles at the same time, hanging up coats, or handing them back to people, without people having to wait in line. The same principle applies to memcached: Each client ascertains which daemon it needs to talk to, and in an ideal world, each attendant would walk down a different aisle: of course, nothing can stop the attendants from following one another down the same aisle. If you retrieve data from the cache, manipulate the data, and write it back to the cache, there is no guarantee that a separate instance has not modified the data in the meantime. The gets and cas commands introduced in version 1.2.5 offer a solution: Users can issue a gets command to retrieve data and receive a unique identifier, which they can then send back to the server, along with the modified data, with a cas command. The daemon then refers to the ID to check to see whether the data has changed since the last query and overwrites using the new value if this is the case.
The way memcached handles a server failure also depends on the client. By default, memcached will simply act as if the requested information is not, or is no longer, in the cache. Because of this, it is a good idea to permanently monitor the cache servers. Thanks to the modular design, a daemon is easily replaced. All you need to do is de-register the previous IPs and register the new IP addresses with the clients. But note that some libraries will consider the whole cache to be invalid in this case.
To prevent RAM fragmentation, the daemon uses a slab allocator [6] for memory management. This method specializes in repeatedly reserving and releasing small chunks of memory. In the case of memcached, small means a maximum of 1MB; the daemon will not accept anything bigger than this. If you want to store more, you need to distribute the data over multiple keys or use a different caching system.
Memcached does not concern itself with security. Clients do not need to authenticate against the daemon. Anybody who can access the network can access the cache without reserve. An attacker who knows the usernames behind the keys can systematically ask all the daemons for these names. Cryptic keys can help provide some rudimentary protection. To generate them, you need to hash the usernames in the scope of your own application and then use the results as keys. All account data should be deleted from the cache after use. Also, it is a good idea to define a limited lifetime for the data and to add more layers of security, starting with a firewall to protect the server farm against outside attacks.
Memcached is easy to set up and integrate with existing applications, but this convenience comes at the price of a number of worrisome vulnerabilities. If you manage to address these issues, you get a very fast, distributed cache that will not fail you - even in extreme conditions. The system demonstrates its value day after day on LiveJournal and Slashdot. At the same time, the system is extremely frugal. Because memcached mainly generates hashes, CPU power is not at a premium, and you can even use older computers as cache providers.
| INFO |
|
[1] Memcached: http://www.danga.com/memcached
[2] Overview of client libraries: http://code.google.com/p/memcached/wiki/Clients [3] Inside the protocol: http://code.google.com/p/memcached/wiki/MemcacheBinaryProtocol [4] Libmemcached: http://tangent.org/552/libmemcached.html [5] How a hash table works: http://en.wikipedia.org/wiki/Hash_table [6] How a slab allocator works: http://en.wikipedia.org/wiki/Slab_allocator |