
By Khurram Shiraz
Nowadays, a large number of commercial applications, especially in the areas of engineering, data mining, scientific/medical research, and oil exploration, are based on the capabilities of parallel computing. In most cases, programmers must design or customize these parallel applications to benefit from the possibilities of the parallel architecture. Message-Passing Interface (MPI) is a set of API functions that pass messages between processes (even between processes that are running on different physical servers) so a program can operate in a completely parallel fashion. MPI has now become a standard in the parallel programming world.
LAM/MPI [1] is an open source implementation of the MPI standard maintained by students and faculty at Indiana University. The LAM/MPI system has been around for 20 years, and it is considered a stable and mature tool. According to the website, LAM/MPI is now in "maintenance mode," with most of the new development work occurring instead on the alternative next-generation Open MPI implementation. However, LAM/MPI is still receiving critical patches and bug fixes, and the large install base of LAM/MPI systems around the world means that developers who specialize in parallel programming are still quite likely to encounter it.
In addition to offering the necessary libraries and files to implement the mandated MPI API functions, LAM/MPI also provides the LAM run-time environment. This run-time environment is based on a user-level daemon that provides many of the services required for MPI programs.
The major components of the LAM/MPI package are well integrated and designed as an extensible component framework with a number of small modules. These modules are selectable and configurable at run time. This component framework is known as the System Services Interface (SSI).
LAM/MPI provides high performance on a variety of platforms, from small off-the-shelf single-CPU clusters to large SMP machines with high-speed networks. In addition to high performance, LAM/MPI comes with a number of usability features that help with developing large-scale MPI applications.
In this article, I take a look at how to get started with parallel programming in LAM/MPI.
The cluster used in this article is based on an Intel blade center with five Intel blades. Each blade had two processors, two Ethernet cards, one FC card, and 8GB of memory. I used Red Hat Linux Enterprise Edition v4 as the operating system for this High-Performance Computing (HPC) example.
For low-cost implementations, you can used SCSI or SAN-based storage (for the master node only) and then make it available to all client nodes through NFS. Another possibility is to use NAS instead of SAN. A cluster filesystem such as GFS, GPFS, or Veritas can provide additional performance improvements; however, note that almost 95% of cluster computing implementations work well with a simple NAS or SAN.
Each blade system should have at least two Ethernet interfaces. You might even consider having additional Ethernet cards on your client or master nodes and then using Ethernet bonding on public network or private network interfaces to improve performance and availability.
On my network, the addressing for intra-cluster communications uses a private, non-routable address space (e.g., 10.100.10.xx/24). Slave nodes use only a 1GB Ethernet port (eth0) with an address in the private network. The master node (eth0) address is used as the gateway for the slave nodes.
SELinux is enabled by default on RHEL 4 systems, but if this enhanced security functionality is not necessary, consider turning it off. The iptables firewall is also enabled by default. If the cluster is on a completely trusted network, you can disable the firewall. If not, the firewall should be enabled on the master node only with SSH access enabled.
If your cluster contains a large number of nodes, you will also want some form of administration tool for central management of the cluster. I'll use the C3 open source cluster management toolset for this example. (See the box titled "Setting up C3.")
| Setting Up C3 |
|
Several open source distributed shell tools provide cluster management capabilities, but I decided to rely on C3 [2] - an excellent, fast, and efficient tool for centralized cluster management. The C3 suite provides a number of tools for managing files and processes on the cluster. You can download the C3 RPM from the project website [3] and install it as root. The installer will set up the package in the /opt/c3-4 directory for the current version. Then add the following symbolic links: ln -s /opt/c3-4/cexec /usr/bin/cexec ln -s /opt/c3-4/cpush /usr/bin/cpush The next step is to specify the cluster nodes in the /etc/c3.conf file, as shown in Listing 1. (The example in Listing 1 assumes all cluster nodes are able to resolve hostnames with their /etc/hosts files.) Now you can test functionality of the C3 tools. For instance, the cexec tool executes a command on each cluster node. The command: #/home/root> cexec df outputs the filesystem layout on all client nodes. |
| Listing 1: Example /etc.c3.conf file |
01 cluster local {
02 alpha:alpha1 # public and private hostname on master node
03 bravo[2-5] # compact notation to specify the slave nodes
04 }
|
Before you start up the LAM run time, create a non-root user to own the LAM daemons. On master node, execute:
/home/root> useradd -d lamuser /home/root> passwd lamuser (enter lamuser passwd at prompt)
To synchronize security information related to lamuser from the master node to all client nodes, use cpush:
/home/root> cpush /etc/passwd cpush /etc/shadow cpush /etc/group cpush /etc/gshadow
Also, you need to set up an SSH passwordless configuration for the lamuser account.
Conceptually, using LAM/MPI for parallel computation is very easy. First, you have to launch the LAM run-time environment (or daemon) on all master and client nodes before compiling or executing any parallel code. Then you can compile the MPI programs and run them in the parallel environment provided by the LAM daemon. When you are finished, you can shut down the LAM daemons on the nodes participating in the computation.
Start by installing LAM/MPI on all nodes in the cluster. Red Hat RPM packages, along with source code, are at the LAM/MPI project website [4]. Debian packages are also available [5].
Before you install LAM/MPI, make sure you have the MPI-ready C compilers and the libaio library. The C3 tool suite described earlier is a convenient aid for installing the LAM/MPI RPM on all the files of the cluster. For example, the combination of the cpush, cexec, and rpm commands can install LAM binaries simultaneously on all cluster nodes.
cd /tmp/lam cpush lam-7.10.14.rpm cexec rpm -i lam-7.10.14.rpm
After successful installation of LAM/MPI, you have to set up the PATH environment variable. In this case, the user owning the LAM daemons is lamuser and the default shell is Bash, so I edit /home/lamuser/.bashrc to modify the PATH variable definition so it contains the path to the LAM binaries:
export PATH=/usr/local/lam/bin:$PATH
If you are using the C shell, add the following line to the /home/lamuser/.cshrc file:
set path = (/usr/local/lam/bin $path)
Note that this path might be different depending upon your distribution of Linux and the version of LAM/MPI.
To transfer the modified .bashrc or .cshrc file to all client nodes, use the C3 cpush command.
Now you are ready to define the LAM/MPI cluster nodes that will participate in your parallel computing cluster. The easiest way to define the nodes is to create a file named lamhosts in /etc/lam on the master node and then use cpush to send this file to all of the client nodes.
The lamhosts file should contain resolvable names of all nodes. A lamhosts file for my high-performance computing cluster is shown in Listing 2.
| Listing 2: /etc/lam/lamhosts |
01 bravo1.cluster.com 02 bravo2.cluster.com cpu=2 03 bravo3.cluster.com cpu=2 04 bravo4.cluster.com |
The cpu setting in the lamhosts file takes an integer value and indicates how many CPUs are available for LAM to use on a specific node. If this setting is not present, the value of 1 is assumed. Notably, this number does not need to reflect the physical number of CPUs - it can be smaller than, equal to, or greater than the number of physical CPUs in the machine. It is used solely as a shorthand notation for the LAM/MPI mpirun command's C option, which means "launch one process per CPU as specified in the boot schema file."
Once the lamhosts file is complete, you can use the lamboot command to start the LAM run-time environment on all cluster nodes:
/home/lamuser> lamboot -v /etc/lam/lamhosts
The output of the preceding command is shown in Listing 3.
| Listing 3: lamboot Output |
01 LAM 7.0.6/MPI 2 C++/ROMIO - Indiana University 02 03 n0<1234> ssi:boot:base:linear: booting n0 (bravo1.cluster.com) 04 n0<1234> ssi:boot:base:linear: booting n1 (bravo2.cluster.com) 05 n0<1234> ssi:boot:base:linear: booting n2 (bravo3.cluster.com) 06 n0<1234> ssi:boot:base:linear: booting n3 (bravo4.cluster.com) 07 n0<1234> ssi:boot:base:linear: finished |
If you have any problems with lamboot, the -d option will output enormous amounts of debugging information.
The recon tool (see an example of some output from this command in Figure 1) verifies that the cluster is bootable. Although recon does not boot the LAM run-time environment, and it definitively does not guarantee that lamboot will succeed, it is a good tool for testing your configuration.

Another important LAM tool is tping, which verifies the functionality of a LAM universe by sending a ping message between the LAM daemons that constitute the LAM environment.
tping commonly takes two arguments: the set of nodes to ping (in N notation) and how many times to ping them. If the number of times to ping is not specified, tping will continue until it is stopped (usually by hitting Ctrl+C). The command in Figure 2 pings all nodes in the LAM universe once.
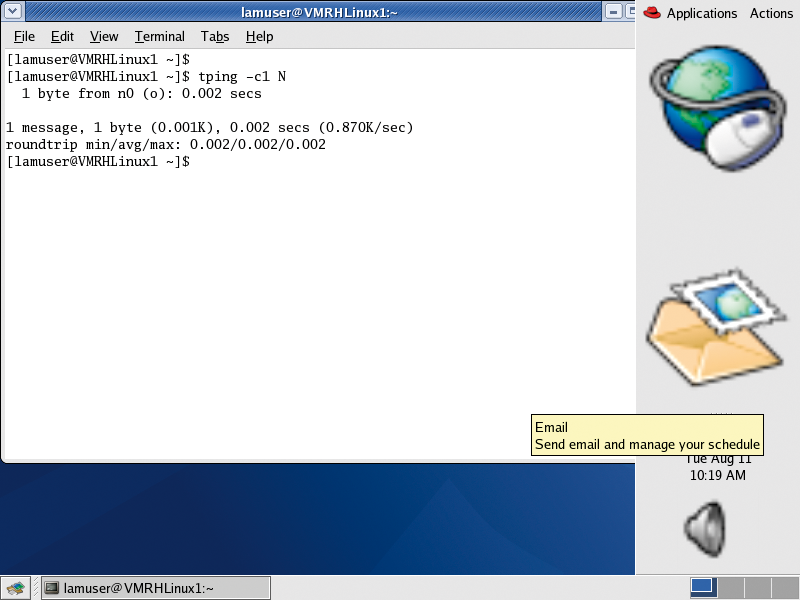
Once your LAM universe and all nodes are up and running, you are ready to start your parallel computation journey. Although it is possible to compile MPI programs without booting LAM, administrators commonly boot LAM services first before compiling.
One of the basic rules of LAM/MPI is that the same compilers that were used to compile LAM should be used to compile and link user MPI programs. However, this requirement is largely invisible to administrators because each LAM universe provides specific wrapper compilers to perform compilation tasks.
Some examples of the wrapper compilers are mpicc, mpic++/mpiCC, and mpif77, which are provided to compile C, C++, and Fortran LAM/MPI programs, respectively, in a LAM/MPI environment.
With the following commands, you can compile C and FORTRAN MPI programs, respectively:
/home/lamuser> mpicc foo1.c -o foo1 /home/lamuser> mpif77 -O test1.f -o test1
Note, too, that any other compiler/linker flags can be passed through the wrapper compilers (such as -g and -O); they will then pass to the back-end compiler.
Wrapper compilers only add all the LAM/MPI-specific flags when a command-line argument that does not begin with a dash (-) is present. For example, when you execute the mpicc command without any arguments, it will invoke a back-end compiler (which is nothing more than the GCC compiler):
/home/lamuser> mpicc gcc: no input files
Now the resulting executables (test1 and foo1 in preceding examples) are ready to run in the LAM run-time environment.
You have to copy the executable to all of client nodes and assure that execution permissions are available for lamuser on that executable.
Now you are ready to start parallel execution. You can run all the processes of your parallel application on a single machine or more than one machine (master/client nodes in LAM/MPI cluster). In fact, LAM/MPI also lets you launch multiple processes on a single machine as well, regardless of how many CPUs are actually present on the machine.
Alternatively, you can use the -np option of the mpirun command to specify the number of processes to launch.
For example, you can start the LAM/MPI cluster on all nodes by using lamboot and then compiled the sample C program cpi.c (see Listing 4), which is available for download from the LAM/MPI website.
| Listing 4: cpi.c |
001 ------------------------------------
002 Sample MPI enabled C program "cpi.c"
003 ------------------------------------
004
005 /*
006 * Copyright (c) 2001-2002 The Trustees of Indiana University.
007 * All rights reserved.
008 * Copyright (c) 1998-2001 University of Notre Dame.
009 * All rights reserved.
010 * Copyright (c) 1994-1998 The Ohio State University.
011 * All rights reserved.
012 *
013 * This file is part of the LAM/MPI software package. For license
014 * information, see the LICENSE file in the top level directory of the
015 * LAM/MPI source distribution.
016 *
017 * $HEADER$
018 *
019 * $Id: cpi.c,v 1.4 2002/11/23 04:06:58 jsquyres Exp $
020 *
021 * Portions taken from the MPICH distribution example cpi.c.
022 *
023 * Example program to calculate the value of pi by integrating f(x) =
024 * 4 / (1 + x^2).
025 */
026
027 #include <stdio.h>
028 #include <math.h>
029 #include <mpi.h>
030
031
032 /* Constant for how many values we'll estimate */
033
034 #define NUM_ITERS 1000
035
036
037 /* Prototype the function that we'll use below. */
038
039 static double f(double);
040
041
042 int
043 main(int argc, char *argv[])
044 {
045 int iter, rank, size, i;
046 double PI25DT = 3.141592653589793238462643;
047 double mypi, pi, h, sum, x;
048 double startwtime = 0.0, endwtime;
049 int namelen;
050 char processor_name[MPI_MAX_PROCESSOR_NAME];
051
052 /* Normal MPI startup */
053
054 MPI_Init(&argc, &argv);
055 MPI_Comm_size(MPI_COMM_WORLD, &size);
056 MPI_Comm_rank(MPI_COMM_WORLD, &rank);
057 MPI_Get_processor_name(processor_name, &namelen);
058
059 printf("Process %d of %d on %s\n", rank, size, processor_name);
060
061 /* Do approximations for 1 to 100 points */
062
063 for (iter = 2; iter < NUM_ITERS; ++iter) {
064 h = 1.0 / (double) iter;
065 sum = 0.0;
066
067 /* A slightly better approach starts from large i and works back */
068
069 if (rank == 0)
070 startwtime = MPI_Wtime();
071
072 for (i = rank + 1; i <= iter; i += size) {
073 x = h * ((double) i - 0.5);
074 sum += f(x);
075 }
076 mypi = h * sum;
077
078 MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
079
080 if (rank == 0) {
081 printf("%d points: pi is approximately %.16f, error = %.16f\n",
082 iter, pi, fabs(pi - PI25DT));
083 endwtime = MPI_Wtime();
084 printf("wall clock time = %f\n", endwtime - startwtime);
085 fflush(stdout);
086 }
087 }
088
089 /* All done */
090
091 MPI_Finalize();
092 return 0;
093 }
094
095
096 static double
097 f(double a)
098 {
099 return (4.0 / (1.0 + a * a));
100 }
|
To compile the program with the mpicc wrapper compiler, enter the following:
/home/lamuser> mpicc cpi.c -o cpi
I executed this executable cpi with six parallel processes on a five-node LAM/MPI cluster.
/home/lamuser> mpirun -np 6 cpi
According to the lamhosts file defined previously, this command starts one copy of cpi on the n0 and n3 nodes, whereas two copies will start on n1 and n2.
The use of the C option with the mpirun command will launch one copy of the cpi program on every CPU that was listed in the boot schema (the lamhosts file):
/home/lamuser> mpirun -C cpi
The C option therefore serves as a convenient shorthand notation for launching a set of processes across a group of SMPs.
On the other hand, the use of the N option with mpirun will launch exactly one copy of the cpi program on every node in the LAM universe. Consequently, the use of N with the mpirun command tells LAMP to disregard the CPU count.
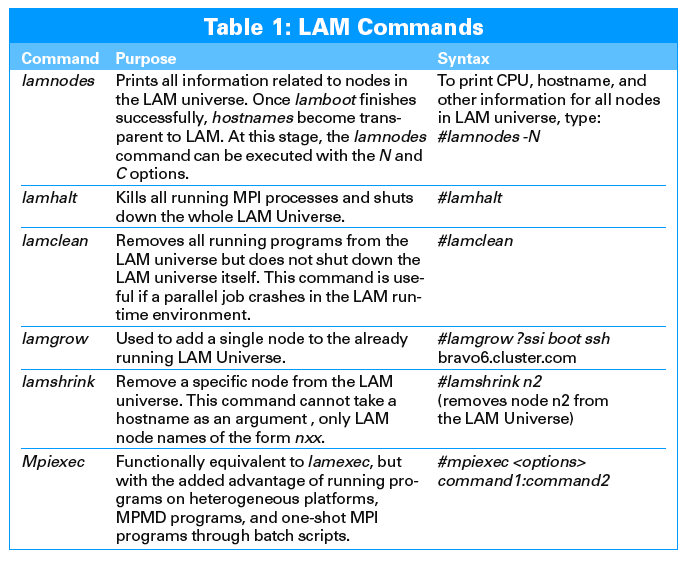
The LAM Universe is easy to manage, but it has no GUI-based management infrastructure, so most of the time administrators have to rely on built-in LAM commands. Some of the important LAM commands are shown in Table 1.
Many applications used in engineering, oil exploration, simulation, and scientific research require the power of parallel computation, and that is why developers continue to use LAM/MPI for building HPC applications.
Although the next-generation Open MPI implementation [6] includes many new features that are not present in LAM/MPI, LAM/MPI has a very large base of users who are quite happy with its reliability, scalability, and performance.
| Improving Performance |
|
In parallel computation scenarios, the main objective is often to reduce the total wall clock execution time rather than simply reduce CPU time. Because so many different factors are present, you cannot expect a linear improvement in performance just by adding more and more nodes. One of the most important factors is the inherent parallelism present in the code (i.e., how well the problem is broken into pieces for parallel execution). From an infrastructure point of view, many additional factors can also contribute to improved performance. In most LAM/MPI cluster implementations, because client nodes have to communicate with each other through the MPI architecture, it is important to have a fast and dedicated network between nodes (e.g., gigabit Ethernet interfaces with bonding). Also, it is a good idea to create a separate VLAN for a private communication network so that no other traffic can contribute to performance degradation. If your application is performing any kind of data mining (which is often the case for commercial implementations of LAM/MPI), disk I/O from master and client nodes also has an effect on performance. However, because of the nature of parallel execution, it is important that source data for data mining (or the executables in simpler implementations) is available to all nodes for simultaneous read and write operations. If you are using SAN-based external disks along with NFS, setting NFS parameters can be beneficial in terms of performance improvement. If you are using NAS storage subsystems and NFS/CIFS protocols to make shared data sources available to all nodes for simultaneous read/write, it is highly recommended that you use a separate VLAN and Ethernet interfaces on each node for disk I/O from the NAS subsystem, so that storage traffic is isolated from MPI traffic. Finally, cluster filesystems (such as GFS, GPFS, and Veritas) can also help speed up disk I/O for large LAM/MPI implementations. |
| INFO |
|
[1] LAM/MPI website: http://www.lam-mpi.org/
[2] C3: http://www.csm.ornl.gov/torc/C3/ [3] C3 download: http://www.csm.ornl.gov/torc/C3/C3softwarepage.shtml [4] LAM/MPI download page: http://www.lam-mpi.org/7.1/download.php [5] LAM run time in Debian:http://packages.debian.org/lenny/lam-runtime [6] Open MPI: http://www.open-mpi.org [7] LAM/MPI User's Guide: http://www.lam-mpi.org/download/files/7.1.4-user.pdf [8] Openshaw, Stan, and Ian Turton. High Performance Computing and the Art of Parallel Programming. ISBN: 0415156920 [9] Lafferty, Edward L., et al. Parallel Computing: An Introduction. ISBN: 0815513291 |
| THE AUTHOR |
|
Khurram Shiraz is a technical consultant at GBM in Kuwait. In his nine years of IT experience, he has worked mainly with high-availability technologies and monitoring products such as HACMP, RHEL Clusters, and ITM . On the storage side, his main experience is with implementations of IBM and EMC SAN/ NAS storage. His area of expertise also includes design and implementation of high-availability parallel computing and DR solutions based on IBM pSeries, Linux, and Windows. You can reach him atkshiraz12@hotmail.com. |