
By Sebastian Kügler
Tim Berners-Lee, the creator of the World Wide Web, wrote in 1999, "I have a dream for the Web [in which computers] become capable of analyzing all the data on the web - the content, links, and transactions between people and computer." Now, at just more than 10 years later, this goal of a web based on meaning still hasn't been realized, but ambitious efforts like the Nepomuk project are bringing the dream a little closer.
The Nepomuk [1] research project, initiated by the European Union, is devoted to the goal of unifying user data. The original idea of Nepomuk was to use a personal data source to form a structure based on concepts more intuitive to the user. At the same time, Nepomuk was intended to support topical links between data sources (e.g., files).
Nepomuk developers are working on an initial implementation of the semantic desktop as part of the KDE Software Compilation (SC) [2]. The first pieces were released with the KDE 4.0 developer platform, although this version didn't provide many end-user features.
Since the KDE 4.0 release, Nepomuk has continued to develop, and KDE programs have begun to make use of Nepomuk functionality. Early versions of Nepomuk in KDE used the Redland or Sesame2 databases. Unfortunately, neither of these alternatives provided adequate performance for production settings. In KDE SC 4.4, the team led by Sebastian Trüg, the main KDE developer for Nepomuk, supplied a new storage back end based on the RDF database Virtuoso [3]. Virtuoso solves licensing and packetizing issues while boosting performance. This new release has freed the path for the continued implementation of technologies in the context of the semantic desktop. The result is some interesting new features for KDE 4.4 users. This article takes a look at how the KDE project is integrating Nepomuk technology into the Linux desktop.
To assign semantic meaning to data, you have to provides clues that describe what that data means. In other words, you have to associate other data with the data. Life on the semantic desktop is all about metadata - that is, information glued onto files. In the full realization of the semantic ideal, ontologies will provide a common framework for assigning meaning to data. (See the box labeled "What are Ontologies?") Nepomuk's semantic framework offers a rich environment that users (and applications) can use for associating metadata with files [4].
| What Are Ontologies? |
|
To handle documents at the level of abstraction required for a semantic desktop, users and applications need to agree on specific definitions to support and exchange data and content links. An ontology is a pre-defined representation of concepts and relationships within a domain of knowledge. The Nepomuk ontologies define concepts such as person, message, and task, along with the relationships among these components. To represent a person, Nepomuk uses the NCO ontology, which maps address book entries, as well as chat buddies and contacts on social networks. Applications that use this ontology can thus share knowledge of a person with other applications that support the same ontology. |
Metadata can consist of a comment, an assessment, or a keyword. In the case of a digital photo, the metadata could include the time at which the photo was taken, resolution, exposure time, aperture, and much more. Additionally, you can attach metadata to artifacts other than files, such as URLs, projects, personal data, and so on.
The principal component of the Nepomuk framework in KDE is the application programming interface (API), which allows developers to find specific entries in the Nepomuk database and to create new objects, which can then be extended by adding metadata.
Internally, the Nepomuk API in KDE abstracts access to and searches for metadata. Various back ends let users manage or completely replace the storage method. Nepomuk uses the Soprano library, thus standardizing the storage interface and serving it up in a format that Qt developers will recognize.
Index files are a kind of metadata, and Nepomuk is designed to standardize them. In the KDE framework, libstreams from the Strigi project handles indexing. This library, which was developed in C++, includes a memory-friendly indexing tool that can search nested files. That is, if you store a PDF document in a ZIP container, Strigi will index it exactly as if it were in unpacked storage on the filesystem. This ability to delve into files softens the borders between file formats, leading to a more general concept of data.
Soprano, libstreams, and the Nepomuk libraries use a separate indexing daemon in the scope of the Plasma desktop to collect data. The daemon provides the Virtuoso database and proceeds to index the files on the desktop. The Nepomuk process running in the background does its best not to be obtrusive, but to make its services available transparently for the most part. If the system reports that the user is currently working, it postpones the CPU-intensive task of indexing data on disk. The system also waits instead of indexing changed files when the system is running on battery power to avoid using up the battery.
KDE's Solid hardware interface helps determine whether the machine needs to save power - that is, whether it is better to do without the disk and CPU activity the indexing process involves. Additionally, the indexer only works in the background while the user is not busy on the machine. If the indexer does rear its head at an inconvenient moment, you can use the Nepomuk icon in the panel's notification area to suspend file indexing temporarily.
| xmlindexer |
|
You can use the xmlindexer command-line tool provided by the Strigi project to see what metadata Strigi (and thus Nepomuk) can identify. The tool scans file and folder content and outputs the metadata in XML format. A command of xmlindexer myphoto.jpg will extract the known metadata from the photo and bind it to the Nepomuk ontologies. As you can see in Listing 1, xmlindexer finds various useful pieces of metadata when indexing not only the photo, the abstract photo type, and the image/jpeg data type (which is needed for processing by applications), but also the camera settings used to take the photo. If you allow xmlindexer to scan a whole directory, you will see several file sections with metadata in them sorted by ontology. You can experiment with delving into a file by pointing xmlindexer at a ZIP file; the individual files in the archive occur separately in the XML results. |
| Listing 1: Finding Metadata |
01 nonumber 02 luna.sebas(~/Pictures)$ <b>xmlindexer meinphoto.jpg<b> 03 <?xml version='1.0' encoding='UTF-8'?> 04 <metadata> 05 [...] 06 <file uri='myphoto.jpg' mtime='1266193792'> 07 <value name='http://www.semanticdesktop.org/ontologies/2007/01/19/nie#url'>myphoto.jpg</value> 08 <value name='http://www.w3.org/1999/02/22-rdf-syntax- 09 ns#type'>http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#Photo</value> 10 [...] 11 <value name='http://www.semanticdesktop.org/ontologies/2007/01/19/nie#mimeType'>image/jpeg</value> 12 <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#isoSpeedRatings'>200</value> 13 <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#orientation'>1</value> 14 <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#flash'>16</value> 15 <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#model'>Canon EOS 450D</value> 16 <value name='http://www.semanticdesktop.org/ontologies/2007/03/22/nfo#height'>4272</value> 17 <value name='http://www.semanticdesktop.org/ontologies/2007/03/22/nfo#width'>2848</value> 18 <value name='http://www.semanticdesktop.org/ontologies/2007/01/19/nie#contentCreated'>2009:08:30 19 14:58:33</value> 20 [...] 21 </file> 22 </metadata> |
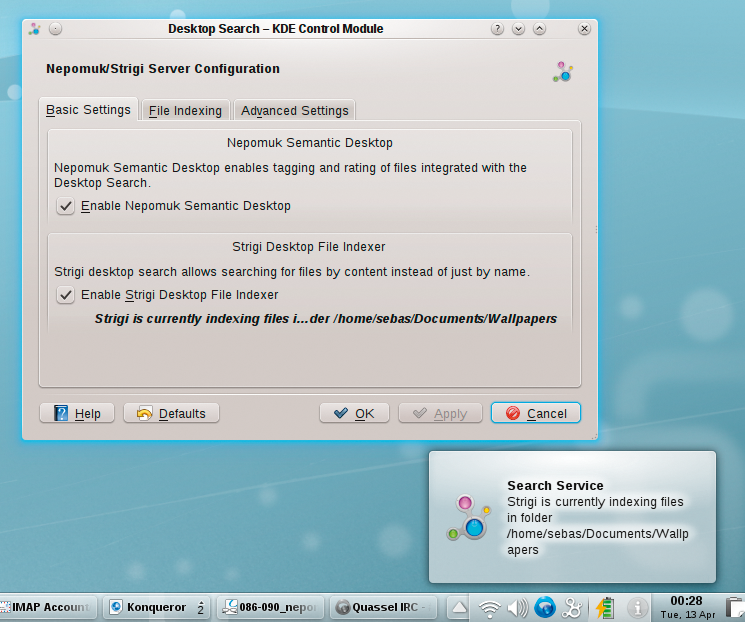
KDE 4.4's Advanced Settings tab in the Desktop Search dialog provides settings for desktop searching and semantic functionality (Figure 1). If you enable the Strigi [5] file indexer, it will also index the data on your disk. The File Indexing tab shows the paths that Strigi covers. If you disable disk indexing, you can still access the Nepomuk database. However, the file index is no longer available as a data source with current data in the desktop search results.
Also, you can opt to disable Nepomuk services, but in that case, you lose features such as annotation, rating, and tagging in the Plasma environment.
A new feature in KDE SC 4.4 is the ability to index data on removable media. You can automatically scan documents on a USB stick to add them to the desktop search as possible results. These files only appear in the results if the medium is available. The desktop decides whether or not this is the case on the basis of an identification string for the medium. Internally, KDE's Solid [6] hardware framework helps out. If you use Nepomuk for larger volumes of data, it makes sense to allocate slightly more memory to Nepomuk.
Indexing is a fairly quick process, even if you have a large volume of data. How long it will take depends to a great extent on the number and types of files you want to add to the search index. When the indexer is running, the system tray area of the taskbar displays the Nepomuk icon; it automatically disappears again when the indexer is done. If the indexer happens to be in your way, you can use the drop-down menu to disable it.
When you launch the Dolphin file manager on KDE SC 4.4, you will notice a new search bar in the top-right corner. This extended input line helps you define search tasks. If you type a key, you are given various options, such as searching for a tag, for example. The entry is autocompleted to include existing keywords while you type. For example, you can just type wall to find images you tagged previously as Wallpaper (Figure 2).
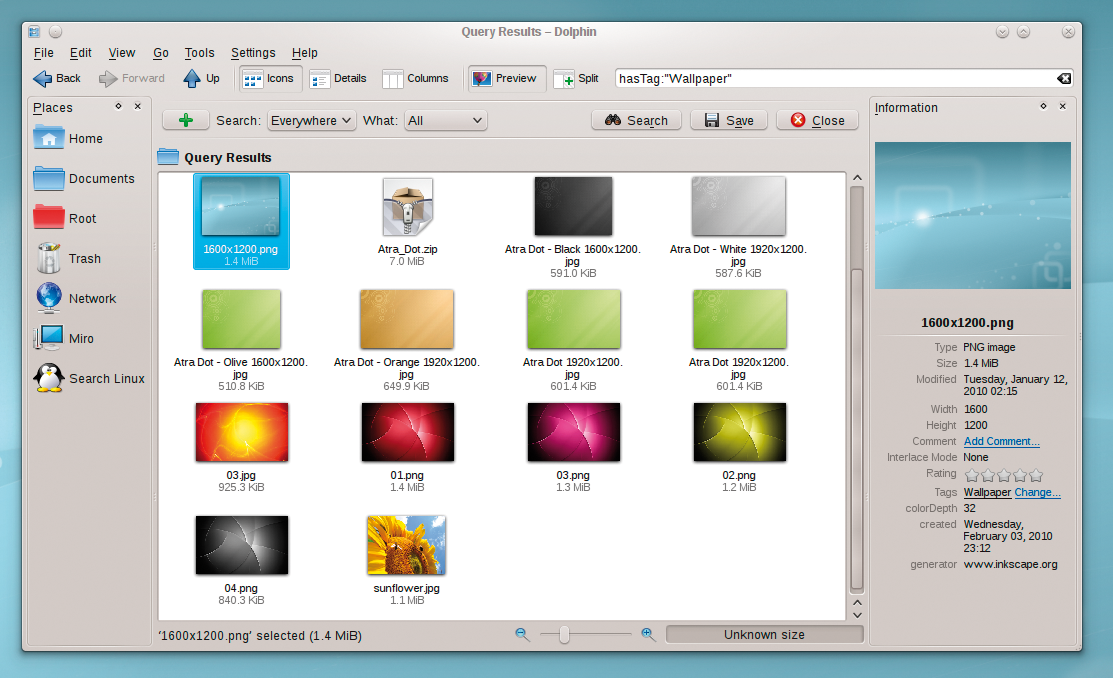
If you enter a key and then press Enter to confirm, Dolphin will search for files that contain the key. If you enabled full-text searching in the system settings, the search will also include file content. You can fine tune the search by clicking the button with the plus sign; this tells Nepomuk to show you some more search criteria. If you set the type to Text, the search will not only find plain/text type files, but also ODF and PDF documents.
In many cases, you might want to reuse a search. To do so, click Save and save the search in your Places. This mechanism provides a simple approach to opening files from other programs. All the searches you saved as places will be in the sidebar of the Open Document dialog. The system doesn't save the results, just the search task itself: Now you can repeat the search and receive up-to-date results every time you use it.
The KIO (KDE input/output) virtual filesystem runs the search independently of the calling program. The desktop stores your search task in your Places as a nepomuksearch:/ URL, which in turn points to a query that uses the RDF query language and accompanying semantic web protocol SPARQL. An internal notification mechanism updates the search task while returning the results. Just type nepomuksearch://linux/ in the Dolphin address bar and see what happens (Figure 3).
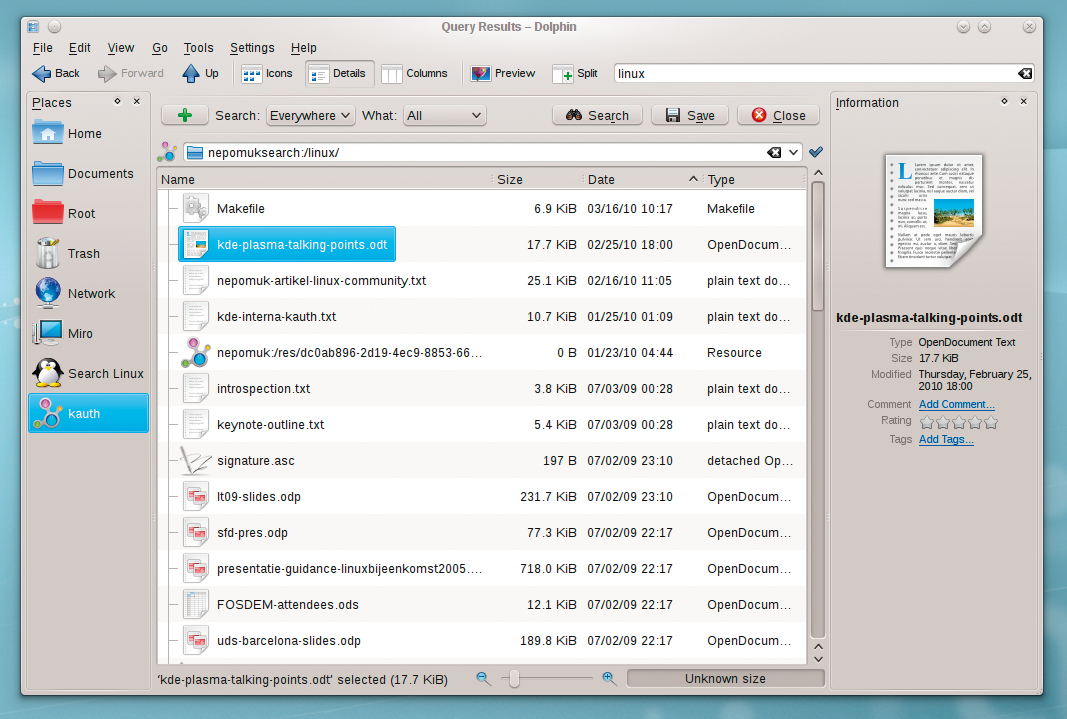
Integrating desktop searching at the file management level turns out to be extremely flexible if you need to search for specific documents in a large directory tree. You can use Dolphin to browse your data and launch a search directly from within the application. The Search drop-down menu lets you restrict the search to the current directory tree position if necessary, and you can add more search criteria, such as the file type, by clicking the button with the plus icon. Also, you can specify the last modification date more precisely as a way to remove files that have not been modified recently from your search results. Additionally, you can restrict the search to results that comply with a minimum rating.
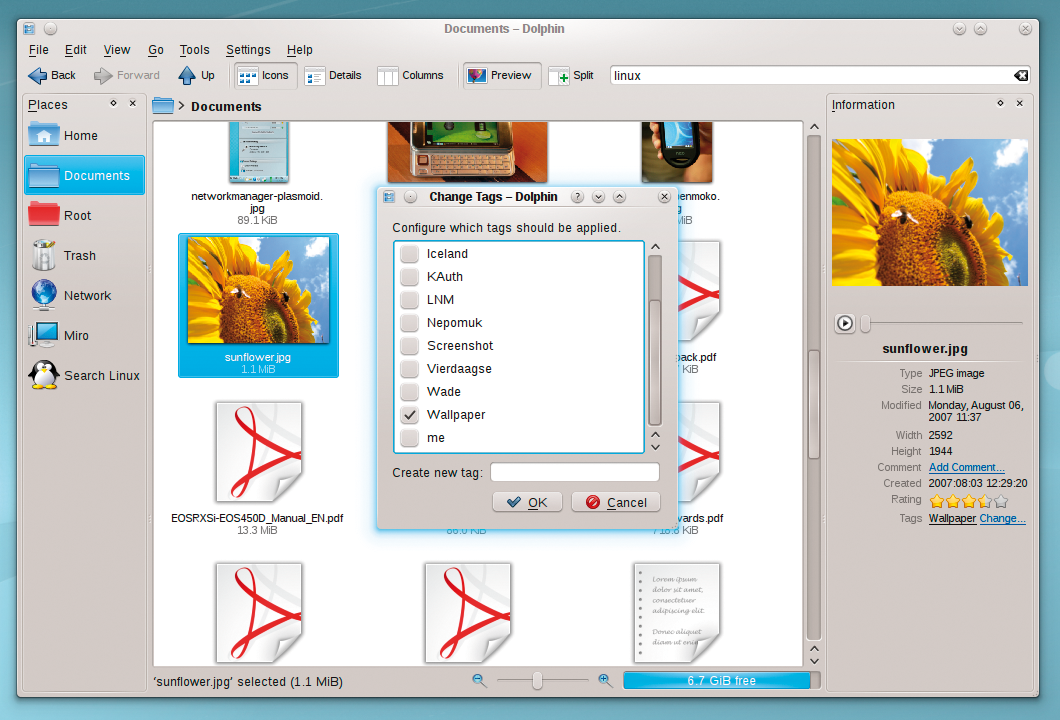
In the Dolphin sidebar, which you can display by pressing F11, you will find some of the metadata for the file. Also, you can add a keyword or a comment here for one or multiple files (Figure 4). To modify the rating, click the row of five stars. You can even give half points. Nepomuk stores the value internally as a number between 1 and 10.
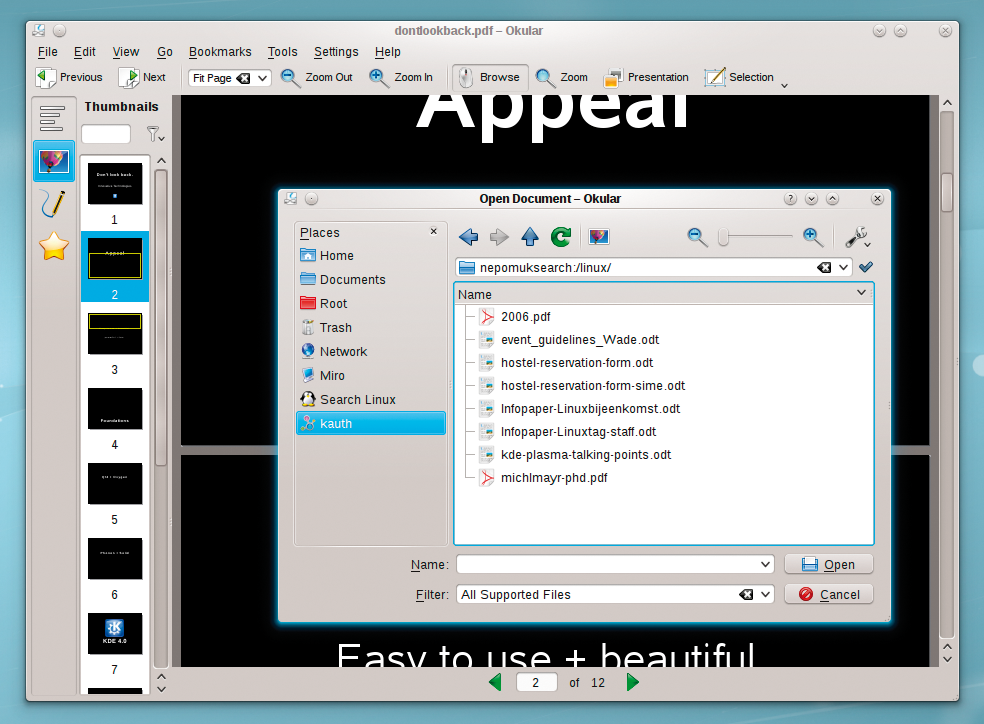
Rapid access to the search results is a practical feature to include with the Open Document dialog. The places - and thus the stored searches - are available in the sidebar. Instead of painstakingly working your way through the directory trees to find specific files, you can use predefined searches (Figure 5). These searches are a convenient way to open multiple contiguous files, even if they reside in different directories. (Once you are used to this feature, you won't want to do without it.)
| Plasma Creativity |
|
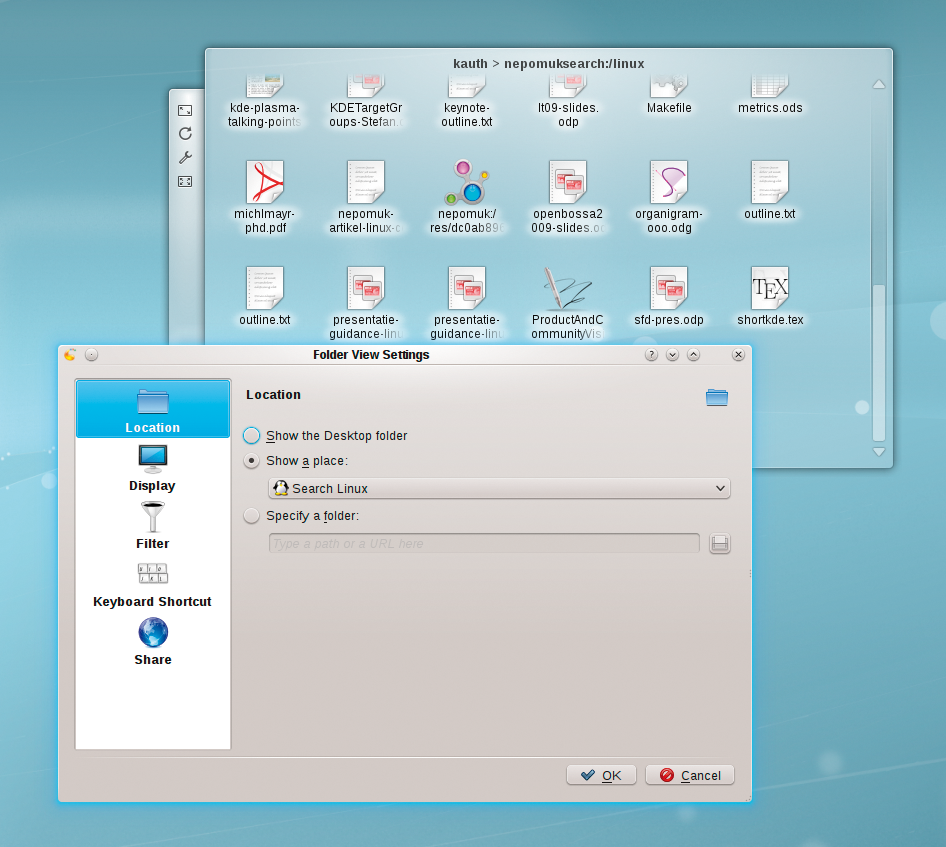
The low-level integration of the semantic desktop allows users to be more creative in handling files. Just create a folder view widget on your desktop and point it to a nepomuksearch:/ URL - or point it directly at the location for your stored searches (Figure 6). In Plasma 4.4, the KDE developers dipped into their bag of tricks and extended the dragging and dropping of data on the desktop. In KDE 4.3, you could drag local links onto the desktop and drop them there to create a folder view widget or drop a text file onto the desktop to create a note with the text in the file. This mechanism allows for extremely intuitive use of the desktop. |
The switch from Kontact to Akonadi [7], which is planned for KDE SC 4.5 this summer, will bring semantic features to the world of PIM. Akonadi will play the role of the personal information broker in the KDE environment. KMail hackers can then use Nepomuk technologies to index email and email attachments. Because the libstreams doing the indexing also supports searching in embedded documents, it will investigate documents contained in zipped archives attached to email as well. The system stores the metadata extracted from messages with links to allow the semantic structure to be dropped on top of the mailbox. This accelerates the search for certain messages and also allows email to be output in the context of other data.
You might be wondering whether you need to link all this data manually. Thanks to Nepomuk, the KDE developers take this load off your shoulders. Data indexing is only one approach to linking documents.
Another option is to collect metadata automatically. For example, programs can save information on the documents they edit simultaneously and then automatically link these documents. Of course, files are not the only objects of interest. Another important consideration is data stored online.
Online data are the domain of the Akonadi groupware cache, which celebrates its entry into the KDE software compilation with version 4.4 of the KDE address book. The PIM developers are currently working hard on migrating more components from the Kontact package. Release 4.5, which is planned for this summer, will introduce an Akonadi-based version of the KMail application.
In using Akonadi, the PIM developers are relying on applying Nepomuk's full text search capabilities to email and attachments. Akonadi currently uses its own MySQL database; however, the PIM developers are already thinking about using Virtuoso as the storage back end, which would be a good thing for memory usage.
Personal Information Management could then really benefit from semantic functionality because contacts and identities could be standardized in the NCO ontology.
Akonadi plays the role of a data mule: It uses plugins to import and synchronize various data sources. In the simplest of cases, a data source could be a Kontact visiting card on the local hard disk. But other data sources - known as agents - integrate IMAP or groupware servers. Incoming email can thus be indexed directly. This makes it possible to create virtual folders containing preset searches that behave like email folders.
Because Akonadi's capabilities are not restricted to specific data types, other possibilities spring to mind. RSS feeds, information from social networks, or geodetic information are certainly interesting channels.
In the semantic vein, Mandriva already offers the ability to tag websites you visit directly in the web browser. Indexing websites is also conceivable; after all, if you take the time to read a website, you can give your computer a couple of milliseconds to scan the content. Nepomuk provides an approach for integrating semantic information with the Linux desktop - an option that takes the world a step closer to Tim Berners-Lee's dream of a semantic web.
| Scribo, What Else? |
|
The NLP (Natural Language Processing) project, which is co-sponsored by France, focuses on analyzing human language to discover techniques for extracting semantic information from texts. The initial results, which have already found their way into the KDE source code repositories, look promising. The Scribo Shell test application [8] demonstrates how to automate text analysis and generate a list of keywords and topics from the results. Text analysis relies on an algorithm by the DERI institute, a scientific partner of the Nepomuk and NLP projects based in Ireland. The use of web services for text analysis is another possible approach. The OpenCalais interface also demonstrated in Scribo Shell integrates a web service with a large database belonging to the Reuters news agency. Scribo is not restricted to text, however, and has set its sights on images. |
| Applications |
|
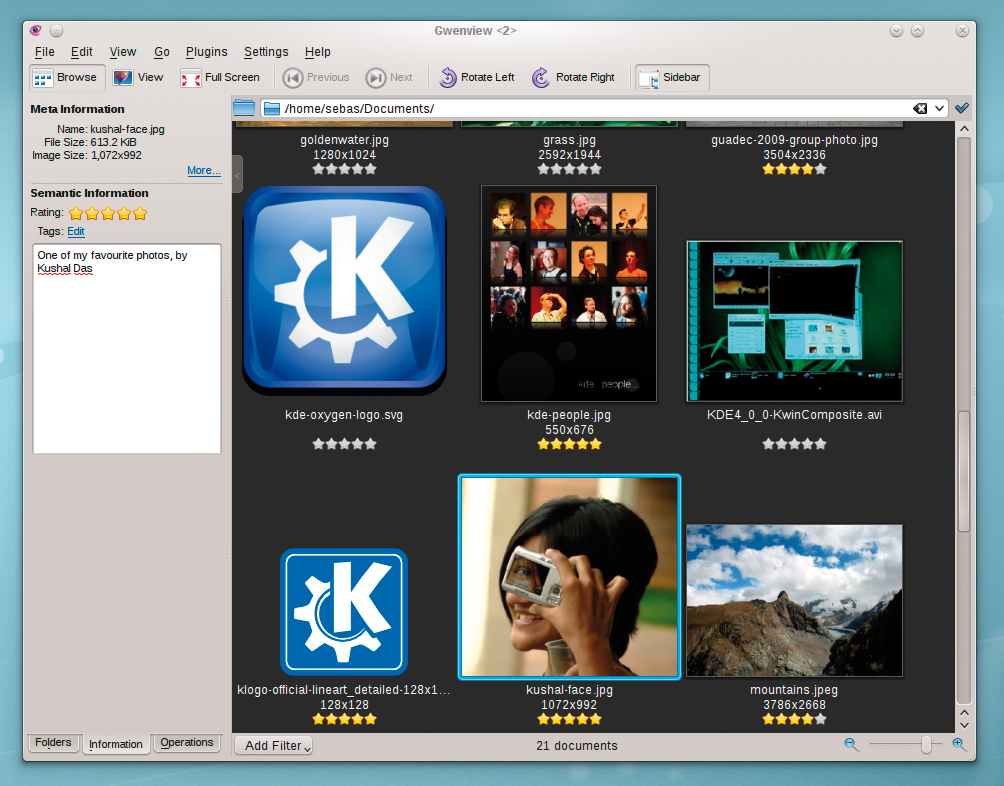
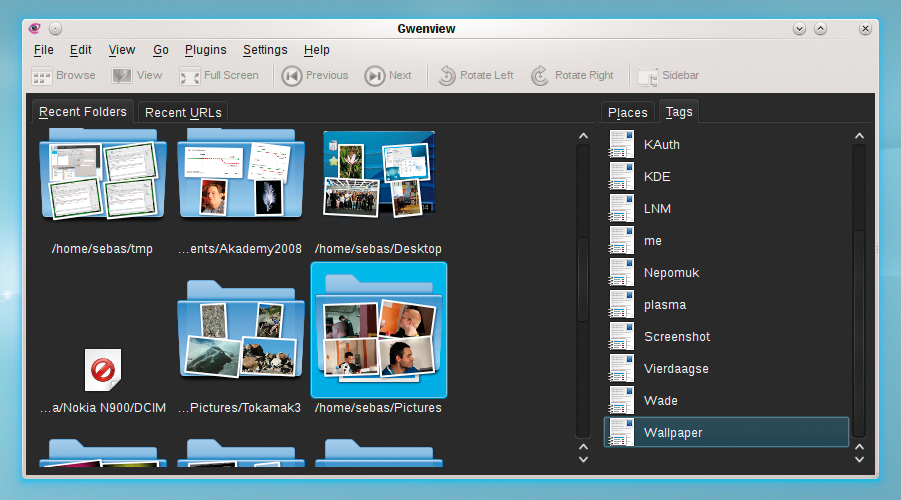
The more applications that use the same index to store their metadata, the more it becomes attractive for other applications to use this repository. The Gwenview image viewer demonstrates that metadata integration can be extended to do more than just open similar files. After enabling rating in the View | Thumbprints item, you can rate images directly in Browse mode (Figure 7). Incidentally, keyboard shortcuts exist for this: if you press a number key from 1 and 5 when viewing an image, the matching rating is applied to the image. This gives you a fast approach to sorting the wheat from the chaff. In Browse mode, the mode in which Gwenview launches, you can also access keywords directly, thus allowing for a "semantic" view (Figure 8). |
| INFO |
|
[1] Nepomuk: http://nepomuk.semanticdesktop.org
[2] Nepomuk in KDE: http://nepomuk.kde.org [3] Virtuoso: http://virtuoso.openlinksw.com [4] Nepomuk ontologies: http://www.semanticdesktop.org/ontologies/ [5] Strigi: http://strigi.sourceforge.net [6] Solid: http://solid.kde.org [7] Akonadi: http://pim.kde.org/akonadi/ [8] Scribo shell: http://www.scribo.ws/ |
| THE AUTHOR |
|
Sebastian Kügler (a.k.a. "sebas") enjoys tinkering with technology - especially in KDE, where he contributes to the development of the Plasma desktop. As a member of the KDE e.V. board, the KDE Release Teams, and the Marketing Working Group, he is responsible for the project's strategic decisions. |