
With a variety of clustering services on the market, the ability to determine how well options meet your specific business needs is necessary.
In today's competitive environment, the adage “time is money” takes on literal meaning. Keeping your business' data on-line and accessible is the foundation of overall system uptime. Whether it be database back ends, web servers or network file systems (NFS) used as e-mail and user directories, outages in your data storage tier can be catastrophic.
The most cost-effective approach to increasing your site's overall reliability is to implement a fail-over cluster. Fail-over clusters involve pooling together multiple computers, each of which is a candidate server for your file systems, databases or applications. Each of these systems monitors the health of other systems in the cluster. In the event of failure in one of the cluster members, the others take over the services of the failed node. The takeover is typically performed in such a way as to make it transparent to the client systems that are accessing the data.
A typical fail-over cluster implementation consists of multiple systems attached to a set of shared storage units, such as disks, connected to a shared SCSI or FibreChannel bus. Each of the cluster members usually monitors the health of others via network (e.g., Ethernet) and/or point-to-point serial connections. Historically, enterprise-quality cluster offerings were the domain of proprietary vendors such as Digital, HP or IBM. Recently, viable Linux-based cluster offerings that run on commodity hardware have become available.
A quick perusal on the Web will uncover a range of Linux-based clustering alternatives. The majority of them look great on paper. They will tout amazingly quick fail-over times for large number of services on clusters consisting of any number of nodes. It is easy to fall into the trap of purchasing the wrong cluster product. The truth is that not all high-availability clustering alternatives safely increase the reliability and availability of your data. Rather, choosing the wrong type of product can leave your valuable file systems and databases vulnerable to corruption. Some products neglect to mention this fact; others only will state this fact if you dig deep under the hood in related white papers.
Being in the UNIX/Linux high-availability business for more than seven years, I have seen cluster products come and go. It's unnerving to see cluster products promoted for jobs they are ill-equipped to perform. Risking end-user data to corruption gives the whole cluster scene a bad name. I have culled through years of investigation to create a simple four-point checklist that serves as a guide for evaluating whether a high-availability cluster product matches your needs. In fact, these points are not particular to UNIX or Linux; they apply across any hardware and operating system implementation. So before dedicating any money (and your company's data) to a high-availability cluster solution, be sure you know how the solution protects you from the following four failure scenarios:
Planned maintenance and shutdown
System crash
Communication failure
System hang
We will be discussing each of these points in detail and pointing out typical pitfalls. But before getting into the analysis of these four points, it is crucial to have an understanding of what data integrity is all about. The fundamental point of data integrity is knowing that your data is accurate and up-to-date. Sounds simple enough. In a cluster environment, preserving the integrity of the data is of paramount importance and supersedes even data availability.
Using examples helps to illustrate the point. The diagram in Figure 1 depicts a two-node cluster (I am using a two-node cluster for simplicity, the concepts apply to clusters composed of more than two nodes as well) with cluster members A and B connected to a shared SCSI bus with Disk 1.
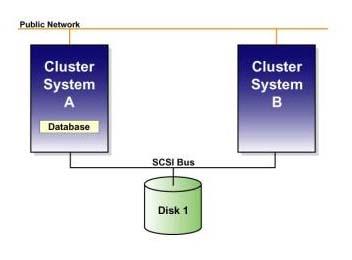
Figure 1. Two Node Cluster with a Shared SCSI Bus
Typical operating systems provide access to disk-based storage via file systems that, in turn, access disk storage. Commonly, the file system mounts the disk volume and then accommodates user access. In the interests of performance, file system implementations typically cache recent copies of file system data in memory. Consequently, the most up-to-date version of your data (being served by node A) is actually the combination of what is cached in system A's memory plus the on-disk data.
Now extend this example to the other cluster member (node B). If node B were to mount the same file system and access it, the true contents of your file system would now consist of the data being cached on node A's memory, plus the data being cached in node B's memory, plus the on-disk data. Making this work correctly requires implementing a file system that coordinates the in-memory cached data of multiple systems in addition to the on-disk data. Such a model, where all cluster members can concurrently mount the same file system, is referred to as a cluster file system. Few UNIX offerings implement a cluster file system and no Linux variants implement a production-ready cluster file system today (although efforts are underway, see the GFS project http://www.gfs.lcse.umn.edu/).
In the absence of a cluster file system, what happens if multiple cluster members concurrently access the same file system? Possible outcomes include:
Inaccurate data—suppose your trip to Las Vegas went particularly well, and you have $100 to deposit into your bank account. Consider that the deposit transaction was handled by node A, and it added the $100 to your prior balance of $25 resulting in a grand total of $125; node A then keeps your most recent balance in its memory resident cache. You then take a flight home and realize you need to withdraw $50 to get your car out of the parking garage. This transaction is now being handled by node B, which goes to the disk and retrieves your balance of $25 and bounces you out for insufficient funds! All this transpired because the true balance of $125 is cached in node A's memory. When it comes to a cluster implementation you need to answer this question: How damaging would it be to your company if the wrong data were supplied?
System crash—in addition to storing user data, such as an account balance, file systems also store their own metadata on disk that describes how user data is organized (consider it an index or table of contents). For performance reasons, metadata is also cached in memory. File systems get particularly confused and upset if their metadata becomes scrambled and often resort to temper tantrums (better known as system crashes or panics). In the absence of a true cluster file system, if you ever have more than one cluster member concurrently mounting the same file system, it will result in each node having a differing idea of what the metadata represents, usually resulting in a system crash.
When a file system's data or metadata becomes scrambled, data corruption ensues. To correct a data corruption problem typically means restoring from a tape backup (you do this regularly, right?). The problem here is that since the backup frequency is low in relation to transaction rate, the time it takes to recover from data corruption is often measured in days rather than the small number of minutes or seconds you expected from deploying a high-availability cluster.
The above concepts about requiring cluster members to synchronize their access to file system data to protect against data corruption also apply to databases. Most database implementations do not allow multiple cluster members to concurrently serve the same underlying disk data. Notable exceptions to this include Oracle Parallel Server (currently being ported to Linux) and Informix Extended Parallel Server.
The upshot of all this is that the cluster implementation you choose must ensure that an individual file system or database can only be served by a single cluster member at any point in time—pretty simple, if you can find a cluster product that does this in all cases. Now, let us proceed to how this holds up under the four scenarios mentioned earlier.
One of the greatest benefits of a high-availability cluster, which is ironically overlooked, is the ability to cleanly migrate services off a cluster member so you can perform routine maintenance without disrupting service to client systems. For example, this allows you to upgrade your software to the latest release or add memory to your system while keeping your site operational. Virtually all high-availability cluster offerings accommodate planned maintenance.
If you believe that a particular operating system is crash proof, give me a call and I'll sell you the Brooklyn Bridge to go along with that OS. Let's face it, system crashes are facts of life; it is merely a matter of minimizing their frequency. In response to a system crash, the other cluster members will conclude that a server has become nonresponsive and commence a take over of the services formerly provided by the failed node.
In the event of a system crash, virtually all fail-over cluster implementations will correctly takeover the services of a failed node. So far so good—it looks like just about any fail-over cluster product will suit you. Not so fast; the following points separate the credible offerings from the not so credible.
Typical high-availability cluster implementations consist of a set of cluster members, each monitoring the other's health over a variety of “cluster interconnects”. Historically, many proprietary cluster vendors have depended on custom hardware for their cluster interconnects. While this provides a solid cluster implementation, by nature it tends to be very expensive and locks you into a single vendor. To provide a cost-effective alternative, other cluster implementations monitor system health over commonly available network interconnects (commonly Ethernet) and serial port connections. In these configurations, the cluster members periodically exchange messages, and based on the response (or lack thereof) conclude whether the other members are up or down. This exchange of system health-monitoring messages is commonly referred to as a “heartbeat”.
A common problem with “heartbeat” based clusters is communication partitions. This is when cluster members (or a set of members) are up but are unable to communicate with one another. Take, for example, the diagram in Figure 2 depicting a two-node cluster with an Ethernet and Serial connection between the nodes over which heartbeat messages are exchanged.
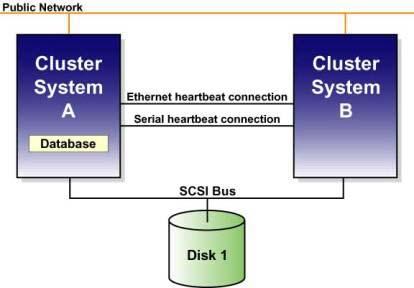
Figure 2. Two-Node Clustet with Ethernet and Serial Connections
Let us suppose you had set up your high-availability cluster and gone off to Las Vegas for the weekend, lulled into complacency with your company's new on-line ordering system deployed in this configuration. Further imagine the cleaning person accidentally knocking out the Ethernet connection with a broom. Now your two cluster members' cluster software running on each node must decide how to respond to this scenario in the interest of preserving high availability. Since the members can't communicate, they have to make the call in isolation. Here's some policy options commonly used by some cluster products:
Pessimistic assumption—Node A knows that it's serving the database but is unaware of node B's state, so node A continues to serve the database. Node B can't communicate with node A and assumes that node A is down. Node B then commences serving the database resulting in two cluster members serving the same database further resulting in database corruption and possibly a system crash. (As weak as this sounds, this policy is employed in some offerings!)
Optimistic assumption—After a site wide power outage, node A and node B both boot up at the same time. Neither node can ascertain the state of the other node and, just to be safe, they each assume that the other node is up so they do not start serving the database (to avoid data corruption). This results in a scenario where neither cluster member is serving the database. So much for spending money for a redundant cluster server! Actually, you're better off having your database unavailable than to have it corrupted. There are other failure scenarios that manifest themselves as a communication failure. For example:
An Ethernet adapter fails
The systems are connected to a common hub or switch that fails
The Ethernet cable fails
To avoid these forms of communication partition, a common clustering practice is to employ multiple communication interconnects. For example, you may have the systems monitor each other's health by heartbeating over multiple Ethernets or a combination of both Ethernet and serial connections. Similarly, you may have each of the network connections go through separate hubs/switches or be point-to-point links.
Most cluster implementations allow you to configure multiple communication interconnects to eliminate the possibility of a communication partition. (If they do not, you should probably quickly move on to another vendor.)
This is the most serious failure scenario that can confront any cluster implementation. If you didn't buy the bridge from me earlier, then perhaps I could interest you in one if you believe that systems never hang. This is another unfortunate fact of life in the computer biz. We've all seen systems mysteriously “lock up” where your only recourse is to reset or power cycle the system to get it responsive again. Fortunately, this is a relatively rare occurrence.
Just as mysteriously as computers can hang, they can also unhang. Surely you've been in scenarios where a system will “lock up” and then after a period of time become responsive again. This can happen on any operating system.
The pivotal question in evaluating cluster products is to understand how a cluster would respond in a hang/unhang scenario. Here's why the question is so important: in a hang scenario, node A becomes completely unresponsive. Suppose you learned your lesson in the prior section describing communication failures, and constructed a cluster with two Ethernet connections and a serial connection so that if any one of them failed, your cluster would still be operational. Well, in response to a system hang it wouldn't matter if you had 50 redundant connections—they all would fail to receive any response to system monitoring heartbeat requests. In response to this, node B would notice that node A has failed to respond to heartbeats over all three channels and conclude that node A has gone down. Following this, node B would mount the file systems or start up the databases formerly served by node A.
At this point, node A could become unhung and commence to update the file system. This results in a situation where two nodes are concurrently mounting and modifying the same file system, creating a data integrity violation.
This is the true litmus test of any cluster implementation. In order to protect against data integrity compromises (i.e., system crashes or invalid data) a cluster member must, before taking over services of a failed node, ensure that the failed node cannot modify the file system or database. This is commonly referred to as I/O Fencing or I/O Barrier.
In order to dodge this scrutiny, some proprietors of cluster products will dismiss the node hang/unhang scenario as an unlikely occurrence. Thankfully, in practice, system hang/unhang scenarios are infrequent. But, before dismissing this criteria entirely, remember it is your data and all the implications of having it corrupted are on the line.
If you care enough about your system's availability to warrant a cluster deployment, then it is crucial that you select a fail-over cluster implementation that ensures data integrity under each of the four failure scenarios. Keep in mind that the most valuable asset of your IT infrastructure is to have valid, accurate data. The cost of failing to ensure that data integrity is maintained is prolonged system downtime or loss of transactions, each of which can be catastrophic.
