
Where everyone meets OSCAR, becomes a Scyld administrator and builds a cluster that rocks.
So you want to build a Linux cluster? Yeah, you and everybody else it seems lately. However, the term Linux cluster is a popular one that doesn't mean the same thing to everybody. When asked, many people would associate Linux clusters with the high-availability, failover, redundancy and load-balancing infrastructure of some e-commerce web site or application server—your typical web farm. Others would associate Linux clusters with those parallel-processing, computational juggernauts, also known as Beowulf clusters. They would all be correct. If you think that's confusing, you should try to wrap your head around the term bioinformatics. Right now, Linux clusters and bioinformatics are two of the hottest technological trends, yet these terms couldn't be more vague. I should know, they're my job—well, more of an adventure really. Yep, that's me, Linux Prophet: clandestine cluster consultant, Beowulf Bad Boy, boon to bioinformatics and alliterative arse.
But enough about me—and more about Beowulf. The brainchild of Donald Becker and Thomas Sterling while working for a NASA contractor in 1994, Beowulf has grown into the poster child for open-source, clustered computing. The Beowulf concept is all about using standard vanilla boxes and open-source software to cluster a group of computers together into a virtual supercomputer. “What would you do with your own supercomputer?” you ask. Heck, what can't you do? For example, you can rip MP3s or assemble the human genome. These two applications take advantage of multiple processors in slightly different ways. When ripping MP3s on a Beowulf, you are essentially spreading all MP3 creation, typically an MP3 per CPU, over the cluster. In this way you are parallelizing several serial jobs by starting them all at once, each on a different CPU. Each MP3 job is an entity unto itself and doesn't need to exchange information with any other MP3 job while running. So, theoretically, one thousand MP3s (of equal size) can be completed by one thousand processors (of equal speed) in the same time that one MP3 can be completed by one processor. That's life in a perfect world. We won't really see linear speed increase when launching 1,000 MP3 jobs due to network latency and bandwidth overheads related to scaling up to 1,000 processors.
Most programs that run on Linux can be made to run on a Beowulf similar to the MP3 example with minimal effort to achieve vastly increased throughput. However, most experimental data sets, like those found in weather prediction or DNA sequence comparison, cannot be broken up similar to MP3s because the results from crunching one part of the data set affect the calculations on other parts. The computing that needs to be done in these cases is analogous to ripping one massive MP3 with multiple processors. You can imagine that if the work required to rip one MP3 were divided among multiple processors, the processors would need to communicate with each other to synchronize and coordinate its completion. Programs of this type utilize message-passing programming libraries so that results from one part of the program's computations can be communicated and synchronized with other parts running on different processors.
There are two common parallel-programming models: one utilizes a message-passing interface (MPI) library and the other a PVM, which stands for parallel virtual machine. Simple in theory but difficult to execute efficiently, parallel programming is a complex endeavor. The intricacies of high-performance computing are frustrating enough without having to work with the codes on expensive, temperamental, custom mainframes. The difficult-to-use, proprietary hardware typically associated with high-performance computing in the past is going the way of the dinosaur as more and more people use COTS (commodity-off-the-shelf) computer components and Linux to build Beowulf clusters that provide unbeatable price/performance ratios and fun on open, standardized platforms.
As cool as it sounds, practicing Beowulfery in the early days—like the rest of high-performance computing—was anything but straightforward and more akin to dabbling in witchcraft. Creating a Beowulf cluster required the downloading and installation of additional software tools, utilities and programming libraries to each Linux workstation in a typically heterogeneous network. Each Beowulf was a unique clustered hardware and software universe unto itself and was considered a work-in-progress. Cluster administration and maintenance required carnal knowledge of both resident hardware and software. The problems were many. But as with many open-source success stories, a community was formed that forged ahead.
Since 1994, a great deal of community and commercial development has resulted in significant advances in Beowulf computing and second-generation Beowulf software distributions. That's right, distributions—on CDs. It's no longer necessary to cobble together disparate tools, software and drivers resident in far-flung corners of the Internet to build a Beowulf. Sound too good to be true? Well read on, because I'm going to discuss the different Beowulf software distributions, where to get them and how to get your own Beowulf cluster up and running sooner than you can say schweeeeet.
Physically, every Beowulf has a few things in common that make it a Beowulf and not just an ordinary network of workstations (NOW). Unlike a NOW, not every Beowulf node is created equal—it's a class struggle. Each Beowulf has a master, or head node, and multiple slave, or compute nodes.
Sporting a full-Linux installation, the master node is the command center of the Beowulf and runs the communicative dæmons necessary to transform LOBOS (lots of boxes on shelves) into a cohesive cluster. The master node is where the brains of the outfit (yes, you) wield supreme executive power over the compute nodes via installation and configuration of their software, the mounting of filesystems, job monitoring, resource allocation and access to the outside world.
The compute nodes, on the other hand, are there to do the master's computational bidding and are on a need-to-know basis as far as the master is concerned. Compute node intelligence can range from very dumb (containing very little code) to relatively smart (possessing a full-Linux installation). However, compute nodes having full-Linux installations still lack certain capabilities, provided by the master node, that keep them subservient to the master. For example, filesystems exported via NFS to the compute nodes (like users' home directories) typically reside on the master node. As a matter of fact, since all the Beowulf distributions we will cover embrace this approach by default, the cluster we build in this article will mimic this approach for simplicity's sake. But keep in mind that in reality, some I/O services can be distributed throughout the cluster, and files can be read and written, to and from, a variety of locations to accommodate data flow. But when starting out, it's often easiest to equip the master node with all of the cluster services and data needed by the compute nodes.
In a Beowulf, the master and slave nodes are networked together and communicate over a private LAN isolated from ordinary network traffic. The networking hardware is usually dictated by one's budget and ranges from 10Mbps Ethernet to very high-speed (greater than 1Gbps) proprietary hardware like Myrinet. The least expensive networks are achieved using Ethernet network cards, hubs and category 5 cable. And unless you want all users to be physically located at the master node when using the cluster, having your Beowulf command center connected to an outside network via a second network interface is highly recommended. With this setup, the master functions as a gateway straddling both the private Beowulf LAN and the public network of your organization. Users can log in remotely to the master over the public network in order to access the cluster's resources via the second network interface but cannot sidestep the master node and access compute nodes directly. Treating your Beowulf as a separate computational entity within your organization as I've outlined here provides many performance, administrative and security benefits. No wonder it's the design configuration supported by the current Beowulf software. Take a look at the physical layout of a typical Beowulf in Figure 1.
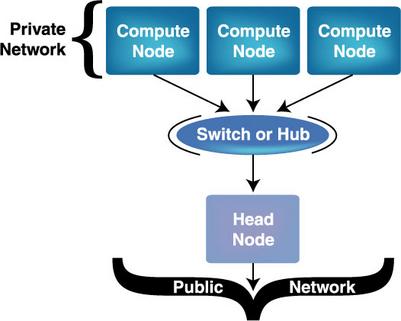
Figure 1. The Physical Layout of a Typical Beowulf
There are essentially two philosophies regarding the Beowulf operating system environment. Let me emphasize that both are good, just different. The two designs cater to different sorts of needs with regard to the cluster's purpose. That is, among other things, the cluster's functional role, the kinds of users, how many users, as well as the application(s) that will run on the cluster, strongly determine how cluster software and access should be configured and controlled. Not taking these things into consideration from the start will come back to haunt you later, so let's cover the two cluster design philosophies.
In the original Beowulf configuration, each node possessed a full-Linux installation, and user accounts were required on each node for an application to run. This configuration incurred a lot of overhead on each node to run any sort of application, and managing misbehaving processes was a rather draconian matter. Since then, rolling out this type of cluster has improved quite a bit. The use of DHCP, Red Hat's Kickstart, SSH, MPI, HTTP and MySQL have really improved cluster installation and administration. But once logged in to the master node, compute nodes still can be accessed by users and told to think for themselves. Compute node access and control is a feature that may be desirable for your particular cluster and its users, and thus represents an important administrative decision. Two cluster distributions built on this model are NPACI's Rocks and the Open Cluster Group's OSCAR (Open Source Cluster and Application Resource).
Driven by the creator of Beowulf, a second cluster paradigm has evolved that embraces a hive-mind approach to the master-compute nodes' relationship. The master node is the queen bee and possesses a full set of chromosomes, the ability to think for herself and control of the hive's actions. Having only a half a set of chromosomes, the compute nodes are the hive's drones and are as dumb as a bag of wet mice. The compute nodes cannot be logged in to remotely and therefore simply do the master's bidding. Despite my cool arthropod analogy, this configuration has been dubbed the single system image (SSI), and its flagship is the Scyld Beowulf distribution. The SSI represents the other extreme in compute node ideology and certainly has its advantages.
Which model is right for your purposes? Tough question, but it boils down to what you want users to be able to do to the system as a whole. Making an informed decision along these lines will require some tinkering around with the different available default cluster configurations. So, let's start to get a feel for the different clustering software by installing my homeboys' distribution, NPACI Rocks. This small group at the San Diego Supercomputer Center has built a rock-solid, easy-to-use Linux cluster distribution. All you need to build a cluster that Rocks is a network of x86 boxes (IA32 or IA64) similar to that in Figure 1, an internet connection, a CD burner, a CD and a floppy disk.
To begin, cruise over to the Rocks web site by pointing your browser at rocks.npaci.edu. Here you will find a brief introduction to cluster building in general and methods specific to the Rocks' Project madness. One thing that will become apparent when perusing the web site is that the Rocks cluster distribution was built with one goal in mind: to make building and administering Beowulf clusters easy. To achieve this lofty goal, the Rocks group 1) based their distribution on Red Hat Linux, 2) added to Red Hat Linux all the open-source software needed to use and administer a Beowulf cluster out of the box, 3) packaged all the cluster software in RPM format, 4) used Red Hat's Kickstart software to automate the master node and all compute node installs, 5) created a MySQL database on the master node to organize cluster information and 6) provided some software to tie it all together. All great ideas. As far as clustering software goes, the Rocks distribution includes PBS, Maui, SSH, MPICH, PVM, certificate authority software, Myricom's general messaging for Myrinet cards and much more. As if that weren't enough, they also designed some features that allow you to customize and build your own Beowulf distribution by adding your own software to Rocks. How cool is that?
Once you're at the Rocks web site, clicking on the Getting Started link on the left-hand side will link you to the stepwise instructions for building a Rocks cluster. Step 0 briefly describes the basics of physical cluster assembly. Hardware may vary, but the configuration should resemble that depicted in Figure 1.
Step 1 consists of downloading the bootable ISO images from the Rocks FTP site and burning your own CDs. NPACI Rocks is currently based on Red Hat Linux 7.1, so there are two installation CDs, but you only need the first one to build a Rocks cluster.
Step 2 consists of building the kickstart configuration file and installing the master (front end in Rocks parlance) node. Thankfully, the Rocks group has provided a CGI form on their web site that you can fill out to generate this file. Clicking on the link “Build a configuration file” will take you to the form. The form prompts you for the information it needs to generate a kickstart file that will configure the internal and external interfaces of the front end, as well as the administrative, timekeeping and naming services for your cluster. Plenty of advice and default values are provided on the web page to help you fill out the form.
Once you've filled out the form, click the Submit button. After clicking the button, your browser should ask you to save the file. Save the file as ks.cfg, and then copy the file to a DOS-formatted floppy. You now have the software necessary to install a Beowulf cluster—the Rocks CDs and your front-end-specific kickstart floppy. You're ready to Rock! Power on your front-end node-to-be, make sure it is set to boot from the CD-ROM drive, insert CD1 and reset the machine. At the “boot:” prompt, type frontend, insert the floppy and watch the front end install itself. When installation is complete, the machine will eject the CD and reboot itself. Remove the CD and floppy before the machine reboots to avoid re-installation.
Log in to the front end as root. You will be prompted to create your SSH keys. Once your keys have been generated, run insert-ethers from the command line. This program eases Beowulf installation and administration by entering compute node information it parses from compute node DHCP requests into the Rocks MySQL database. Choose Compute from the program's menu, insert CD1 into the first compute node, cycle the power on the node and the compute node will install itself. When installation is complete, the machine will eject the CD. Take the CD, place it into the next compute node and cycle the power. Repeat this process for all the compute nodes.
That's all there is to it. Granted, there's a lot going on behind the scenes that the Rocks guys have made transparent to you, but that was their intention. For a better understanding of the Rocks nuts and bolts, check out the documentation on their site. It's pretty good, and they're adding stuff all the time.
You're now teed up to begin running applications on your Beowulf. For a short tutorial on launching applications that use MPI and/or PBS, check out the information on the Rocks web site under Step 4: Start Computing. One bit of advice, the mpi-launch command is for starting MPI jobs that run over Myrinet, while mpi-run is for running MPI jobs over Ethernet.
That's all for now. Keep your eyes peeled—before you know it, I'll be back with another easy-to-install Beowulf distribution. And then another. And another. And then we'll build a computational grid with them. And then—world domination.

Glen Otero has a PhD in Immunology and Microbiology and runs a consulting company called Linux Prophet in San Diego, California.
