
Need a personal firewall, an enterprise Internet gateway or something in between? iptables does it all!
The Linux kernel includes some of the most powerful and flexible firewall code in any general-purpose operating system. This code is called Netfilter, though most of us refer to it by the name of its user-space command, iptables. Netfilter/iptables allows your Linux kernel to inspect all network traffic that passes through your system, deciding what to do with that traffic based on a very rich set of criteria.
Building Linux firewalls with iptables is a big topic—entire books have been written about it (see Resources). In fact, firewall engineering is a profession unto itself (my profession, in fact). So, alas, nobody can tell you everything you need to know about building firewalls with iptables in one magazine article.
I can, however, provide an overview of the things iptables can do, some sound principles for Linux firewall design, descriptions of some handy tools for building different types of Linux firewalls and pointers to more detailed information on Linux firewalls.
Firewalling, or more precisely, packet filtering, can be used for many things. It can be used locally on individual servers and desktop systems for host-level protection from network-based attacks. It can be used at the network infrastructure level to protect entire networks from other networks, and it can be used to redirect, or even alter, network packets in various ways.
A Linux firewall can be a dedicated hardware appliance based on Linux, a PC with multiple network interfaces, or it even can be an ordinary, single-interfaced workstation or server. Many commercial firewall appliances are Linux/iptables-based. Contrary to what you might think, PC-based Linux firewalls can perform and scale quite well, if deployed on sufficiently powerful hardware.
Those are the form factors Linux firewalls take, and they serve in two different roles. Firewall appliances and multi-interface PC-based firewalls are used as what I call network firewalls. They serve as dedicated network devices, logically equivalent to IP routers that regulate traffic between different networks. (Technically, firewalls are routers; they're just fussier about what they route than ordinary routers.) Network firewalls also often perform Network Address Translation (NAT), typically to allow hosts with non-Internet-routable IP addresses to communicate with the Internet.
Then, there are what I call local firewalls—workstations or servers whose primary function isn't firewalling at all, but the need to protect themselves. In my opinion, any computer connected to the Internet, whether server or workstation, should run a local firewall policy. In the case of Linux systems, we have no excuse for not taking advantage of Linux's built-in Netfilter/iptables functionality. Furthermore, this is the easiest type of firewall script to create, as I show later in this article.
Before we discuss Linux firewall tools, we should cover some general firewall design principles. Most of these principles are (or should be) equally valid whether you're using iptables to protect a single host or entire networks.
First, here are some terms:
Packet filtering: the practice of inspecting individual network packets, comparing against a set of rules and processing them accordingly.
Firewall policy: either a specific set of iptables commands or a higher-level set of design goals that your iptables commands enforce.
Firewall rules or packet-filtering rules: the individual components of a firewall policy—that is, individual iptables command iterations.
The first step in building any set of packet-filtering rules is to decide precisely what you want your firewall to do—that is, to formulate your high-level firewall policy. For example, if I'm creating a local firewall script for a workstation, my logical policy might look like this:
Allow outbound DNS queries, Web surfing via HTTP and HTTPS, e-mail retrieval via IMAP, outbound SSH and outbound FTP transactions from the local system to the entire outside world.
Allow inbound SSH connections to this system from the other workstation in my basement.
Block everything else.
Skipping this crucial step of defining your high-level policy is akin to writing a software application without first defining requirements. You run the risk of wasting time on rules you don't need and of overlooking rules that you do need.
I further recommend that whatever policy you decide on, you make it as restrictive as is feasible. Marcus Ranum very succinctly stated the guiding principle for firewall design many years ago: “that which is not expressly permitted is forbidden”. The reason for this is quite simple; just because you can't think of how an allowed but unnecessary network transaction can't be abused, doesn't mean some attacker can't abuse it nonetheless.
Every firewall policy, therefore, must logically end with a rule that blocks everything not specified earlier.
This is true not only for network/enterprise firewall policies, but also of personal/local firewall policies. A common blunder on personal firewalls is to allow all “outbound” transactions, on the assumption that all local processes are “trusted”. If your system is infected with a worm, trojan or virus, however, this assumption breaks down.
In the event of such an infection, you probably don't want the malware to be able to use your system to send spam, participate in distributed denial-of-service attacks and so forth. Therefore, it's preferable to restrict not only “inbound” (externally originated) network transactions, but also outbound (internally/locally originated) transactions, even on the local firewall policies of desktop systems and servers.
Another important firewall design principle is, whenever possible, to group similar risks together. In other words, systems and networks with different levels of trust and different levels of exposure to risk should be isolated from each other by network firewalls.
The classic example of this principle in action is the DMZ or de-militarized zone, which is a network containing all of an organization's Internet-accessible systems. Figure 1 shows the relationship between such a DMZ: the “internal” network containing an organization's workgroups and other non-public-facing network resources and the Internet.
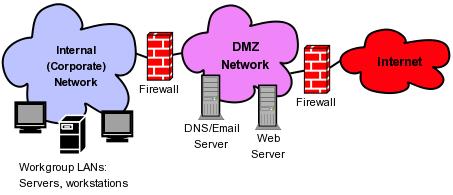
Figure 1. A DMZ Network
With firewalls separating the DMZ network from both the Internet and the internal (trusted) network, you can write rules that specify, in a very granular way, how hosts in these three zones can interact with each other. In formulating such rules, you should assume that, being exposed to a nearly infinite range of possible attackers (via the Internet), the hosts in your DMZ should be treated as semi-trusted at best—that is, you should assume that any host in the DMZ may be compromised at some point. Accordingly, you should allow as few transactions as possible to be initiated from the DMZ to the internal network.
You also should take into consideration the threat a compromised DMZ host could pose to the outside world. If an Internet-based attacker compromises your DNS server, for example, even if the attacker's attempts to hack into your internal network are blocked by firewall rules, that attacker can still cause your organization embarrassment or even legal problems if the compromised server is able to connect arbitrarily (that is, attack) to other systems on the Internet. I can't state this often or strongly enough: firewall policies should allow only the bare minimum set of network transactions necessary for your users and systems to do their jobs. Unnecessary dataflows can and will be abused, sooner or later.
You probably noticed that in Figure 1, two firewalls are used. This is the classic firewall sandwich DMZ architecture, but many organizations opt instead for a more economical multi-homed-firewall DMZ architecture (Figure 2), in which a single firewall with multiple network interfaces interconnects and restricts traffic between different networks. Although the sandwich topology provides greater protection against, for example, the external firewall itself being compromised in some way (assuming the other firewall isn't subject to the exact same vulnerability), the multi-homed-firewall approach can be equally effective, so long as you write your rules carefully enough.
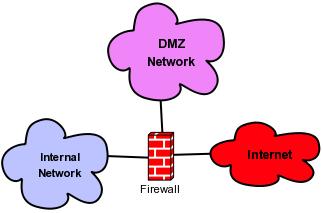
Figure 2. A DMZ and a Multi-Homed Firewall
Also, regardless of whether you use a single multi-homed firewall or pairs of firewalls, it's extremely important that each network zone (inside, outside/Internet and DMZ) be connected to a dedicated physical network interface on a firewall. Yes, this does make your firewall a potential single point of failure. However, if it's possible for hosts in one network zone to route packets to other network zones without traversing the firewall, your firewall will have little practical value!
The last general firewall design principle I mention for now applies only to multi-interface firewalls (that is, not to local/personal firewalls): always use anti-spoofing rules.
Consider the Internet-facing firewall in Figure 1. It has two network interfaces: inside (which faces the DMZ) and outside (which faces the Internet). Suppose that the internal network in Figure 1 uses IP addresses in the Class C network space 192.168.55.0/24, and the DMZ uses 192.168.77.0/24.
This firewall therefore can and should drop any packets arriving on its Internet interface having source IP addresses from either of those two private IP ranges. Such packets safely can be assumed to be forged (spoofed). Attackers sometimes forge the source IP addresses of their packets, attempting to pass them through firewalls or to defeat other source-IP-based authentication mechanisms (TCPwrappers, hosts.equiv and so on).
In fact, any Internet-facing network interface on any firewall should drop packets with source IP addresses from any non-Internet-routable IP range, specifically those specified in RFC 1918: 10.0.0.0/8, 172.16.0.0/12 and 192.168.0.0/16. (If these numbers, which are ranges of IP addresses expressed in CIDR notation, confuse you, don't panic! Some of the iptables tools discussed later in this article assume no particular networking expertise.)
To express this important firewall design principle even more generally: you should configure your firewall to drop any packet bearing an impossible source IP address.
Those are some things all firewalls should do. Now, how do we make them do those things?
All Linux firewalls work the same way. A series of iptables commands are executed in sequence to load firewall rules into kernel memory space. All packets entering all network interfaces are then evaluated by the kernel based on these rules and handled accordingly. These rules are organized in tables (formerly, and still occasionally, called chains). Rules can be inserted, appended, changed and deleted from any table at any time via the iptables command and take effect immediately.
The most direct way to create a Linux firewall policy is to write an iptables startup script from scratch and then manage it like any other startup script in init.d. This is how I manage my own Linux firewalls, and it works fine if you understand networking, you're comfortable with the iptables command, and you don't have many different firewalls to manage or more than a couple of different policies on any given firewall.
To learn how to roll your own iptables scripts, refer to the Resources for this article. As I said previously, I simply can't do that topic justice here. (Note that different Linux distributions handle startup scripts differently.) If you want to harness the full power of iptables, including NAT, custom chains and packet-mangling, this really is the best way to go.
Assuming you can't, or don't, want to write iptables scripts directly, here are some pointers to tools that can help.
The first category of iptables tools I dicuss here probably already exists on your system. Nowadays, nearly all Linux distributions include a firewall wizard in their installation utilities. Nearly always, this wizard is intended for creating a local firewall policy—that is, a personal firewall script, which protects only the local host.
These wizards all work the same way. They ask you which local services you want to allow external hosts to reach, if any. For example, if I'm installing Linux on an SMTP e-mail server, I would allow inbound connections only to TCP port 25 (SMTP), though possibly also to TCP port 22 (Secure Shell, which I may need for remote administration).
Based on your response, the wizard then creates a startup script containing iptables commands that allow incoming requests to the services/ports you specified, block all other inbound (externally originating) transactions and allow all outbound (locally originating) network transactions.
But wait! That third command violates Ranum's principle (deny all that is not explicitly permitted), doesn't it? Yes, it does. That's why I write my own iptables scripts even for local firewall policies. You need to decide for yourself in any given situation whether you can live with the “allow some inbound, allow all outbound” compromise, which is undeniably the simplest approach to local firewalls, or whether you're worried enough about the threat of malware mischief to write a more restrictive script, either manually or using a more sophisticated firewall tool than your Linux distribution's installer.
Note that as with other functions of Linux installers, these firewall wizards usually can be run again later, for example, in SUSE via YaST's Security and Users→Firewall module.
We've discussed the hard way (writing your own iptables startup script) and the easy way (letting your Linux installer generate a local firewall script). There are, however, many other tools for generating and managing sophisticated firewall scripts. Two of the most popular are Shorewall and Firewall Builder (see Resources).
Shorewall is, essentially, a script/macro environment that lets you create firewall policies in the form of text files, which are then “compiled” into iptables scripts. Shorewall's strengths are its flexibility, its ability to insulate users from needing to learn iptables syntax and its convenience in automatically generating startup scripts. If you understand networking, however, learning to use Shorewall isn't necessarily that much less time consuming than learning iptables.
For this reason, I've personally not used Shorewall very much. Friends of mine, however, who know less than me about networking but more about system administration, swear by it.
Firewall Builder, which I covered several years ago in the May and June 2003 issues of Linux Journal, is something else altogether. It's the firewall equivalent of an Integrated Development Environment—that is, a graphical, object-oriented interface for generating iptables scripts (among other firewall types).
Conceptually, Firewall Builder is very similar to the policy editor in Check Point firewalls. You create “objects” for the networks and hosts you want to use in rules, and then you arrange those objects and predefined “service” objects (HTTP, IMAP, FTP and so forth) into graphical rules statements. Firewall Builder not only generates these into iptables scripts, but it also can install them on other systems via SSH.
In my experience, the main strike against Firewall Builder is its somewhat lengthy list of dependencies, chief among them the Qt libraries for GUI development. However, many of the things Firewall Builder needs are now standard Linux packages included on typical distributions, so this is less of a problem than it used to be. See the Firewall Builder home page for detailed installation instructions.
Other graphical iptables utilities include Firestarter and Guarddog (see Resources).
A couple years ago, Linux Journal named iptables its Security Tool of the year. It really is a remarkable achievement. If you're serious about network security, you'll want to explore iptables' power in much greater detail than we've done in this article, starting with the iptables(8) man page and progressing through the how-tos available on the Netfilter home page (see Resources).
Whether you use iptables to protect your laptop or your entire enterprise network, I hope you've found this introduction useful. Be safe!
