
Harry Wei has volunteered to be the official maintainer for all kernel docs in Chinese. There were a few bumps along the way. Tao Ma, at one point, objected that Harry hadn't demonstrated his qualifications or translated large amounts of documentation. But, oftentimes maintainership is based more on a willingness to put in the time, than on any specific expertise or qualification. Harry said he promised to do his best, and that was that.
This is actually one of the first and greatest innovations Linus Torvalds achieved with Linux. While the GNU folks developed the idea of free software, they limited themselves by sticking with just a tight group of core developers, who largely would ignore suggestions and patches from outside. It was Linus' belief that everyone had something valuable to contribute that led to the style of open-source development that now dominates the world.
Miklos Szeredi has documented the overlay filesystem. The overlay is an example of a “union”-style filesystem, in which two distinct filesystems are silhouetted against each other, so as to appear as a single one. Where their directory structures overlap, files from both filesystems appear to the user to be in the same directories.
It's very cool, and very weird, because of the shenanigans that have to go on behind the scenes to deal with conflict resolution. What do you do if both filesystems have a file called /home/zbrown/todo.txt? When new files are created, on which filesystem are they stored? A variety of such cases have to be handled in ways that make the most intuitive sense to the user as well as the sysadmin maintaining the system.
Rob Landley has automated some kernel documentation at kernel.org/doc, which he hopes to continue to improve. The page now extracts much documentation from the kernel source tree itself, links to various relevant standards, and also links to other external documents, both about the kernel and about other related technologies.
He affirms that there's still a lot of work left to do before the doc pages are really great. In particular, the automated extraction process is dependent on there being no errors in the way docs are housed in the kernel source tree, which is not the case. But hopefully, the existence of the kernel.org/doc pages will serve as a kind of regression test that will help others find and fix all those errors. As they do, the doc pages naturally should improve by reflecting those fixes.
A number of kernel developers have decided to take on the issue of bufferbloat, and John W. Linville recently created the git://git.infradead.org/debloat-testing.git tree, specifically to house patches relating to that issue.
Bufferbloat is a problem that may or may not exist within the whole Internet, caused by hardware engineers at a variety of private companies who created the physical technology underlying the Internet. These engineers may have been tempted by the low cost of RAM to create huge throughput buffers that regulate Internet traffic under times of heavy load. Proponents of the bufferbloat idea also speculate that these engineers did not bother to design their hardware to behave well if these buffers became saturated, because they assumed the buffers would handle all foreseeable situations. So, as the Internet has become more and more saturated over time, with video and other high-data traffic, these invisible buffers have been filling up, causing the entire Internet to approach a state of general choppiness in which data no longer is transmitted smoothly from place to place.
The Linux folks are attempting a kind of Herculean challenge. These buffers could exist anywhere along a network connection. They have not been acknowledged by the companies that may have created them, and it is virtually impossible for one system to test for these buffers. But, the Linux folks believe there are algorithms to be discovered that can address bufferbloat directly and help return the Internet to a smooth-flowing state or prevent the further degradation of the global system.
As Linux users, it seems that we have little problem playing a wide variety of video formats. That is not always the case with other operating systems. Certainly with Windows 7, Microsoft has improved the number of video formats it supports, but it pales in comparison to VLC. If you want to play an AVI encoded with an obscure codec or watch a DVD, or if you have a hankering for multicast network video streaming, the VLC player from VideoLAN supports it all (www.videolan.org/vlc).
VLC isn't just for Windows either. OS X and Linux users alike can take advantage of its awesome compatibility. The best part? VLC is open source under the GPL! Enjoy video and freedom at the same time.

If you've ever been outside on a summer night, then come indoors to find you've been attacked by bloodthirsty mosquitoes, you know that those little buggers must be able to see in the dark. In fact, mosquitoes use infrared light to hone in on our body's heat in order to find our juicy bits.
Infrared light also is the same light that most television remote controls use for sending signals. If you've ever tried to troubleshoot a nonworking remote, you know it's frustrating that you can't see if the remote is “lighting up”. Although it's difficult to convince a mosquito to tell you if your remote is working, it is possible to convince your cell phone, or any other digital camera, to do so.
Simply look at the infrared emitter at the business end of your remote through the view-screen of your favorite digital camera (or phone). If the remote is working, you'll see the light it's giving off very clearly. It works well and is much easier than training mosquitoes!

The Linux Professional Institute has offered LPIC-1, LPIC-2 and LPIC-3 training for years. In these tough economic times, making yourself more employable is always a good plan. Unlike the Red Hat Certified Engineer certification process, the LPI certs are platform-agnostic. The requirements include a well-rounded list of objectives for certification. A cool bonus feature for the LPIC-1 exam is that it has the exact same requirements as the CompTIA Linux+ certification. So you can study once and get two certs! For more information, check out www.comptia.org and www.lpi.org.

Computing environments may revolve around heavy usage of NFS infrastructure. Network areas are hosted and provided by storage file servers, with compute servers mounting the exported areas into their directory tree. Periodically, the mounts expire when not in use and are removed from the directory tree on local machines.
If NFS traffic between file servers and compute servers is disrupted, machines holding active mounts will not be able to release them. This could happen in several cases. A potential root cause for the problem might be a network outage; however, this issue will be resolved the moment network traffic is resumed. A far more serious scenario is when a file server stops its service due to malfunction or coordinated maintenance, including an EOL (End of Life) cycle. Any host holding active mounts of areas exported by a file server that is no longer reachable will not release them.
This situation leads to so-called stuck mounts. Any process running on an affected computer server waiting for NFS activity will remain in uninterruptible sleep state without any way to kill it. Up to date, the only sensible solution was to reboot affected hosts. However, critical computer servers, including infrastructure and interactive-use machines, cannot be rebooted without prior coordination. This leaves a time window until the next reboot, during which the affected hosts will continue running in an unstable state.
We provide a rebootless solution to this problem by bringing up a fake file server, a dedicated host assigned the same IP like an unreachable file server, which then rejects the NFS requests from compute servers, freeing them. The special host uses its own network architecture, allowing it to be moved to any VLAN (Virtual LAN) used by file servers. The IP change is done using a Web interface. (A VLAN is a group of hosts with a common set of requirements that communicate as if they were attached to the same broadcast domain, regardless of their physical location. A VLAN has the same attributes as a physical LAN, but it allows for end stations to be grouped together, even if they are not located on the same network switch. Network reconfiguration can be done through software instead of physically relocating devices.)
The stuck NFS mounts solution consists of several key components:
A dedicated host used for faking the IP addresses—we use a virtual machine with minimal hardware requirements. The virtual machine is assigned a separate NIC in the virtualization server. This host is known as the Admin server.
A network infrastructure that supports on-the-fly assignment of the “fake” file server (Admin) to the file server VLANs. Admin is connected directly to the NFS router using a single standard NFS connection, with a 3Gb channel to primary port and 1Gb channel to backup port (Figure 1).
A Web interface for assigning Admin to file server VLANs.
A mechanism to change the IP address on Admin, which can be automated (scripted) or manual.
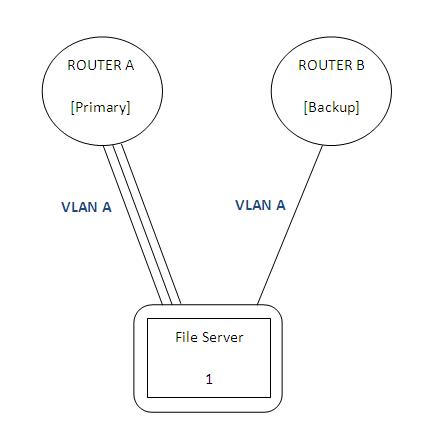
Figure 1. Connection to NFS Router
In our site, Admin is a virtual machine hosted on a virtualization server. The host runs a standard enterprise Linux image; however, it is used only for IP changes and no other purposes, and is configured with minimal disk space and memory. The virtual machine is assigned its own NIC in the virtual server network configuration.
The NFS stuck mounts VLAN change is executed using a Web interface. The GUI allows system administrators with no networking knowledge or access permissions to change the VLAN allocation for the specific router port where the dedicated server is connected to the desired VLAN. The GUI has a static configuration file, with the server name, router name and dedicated port. Once called through the Web interface, it uses SNMP to collect the data from the router and present the table in the middle, the current status and the VLAN drop-down menu. Figure 2 shows a mockup of the Web interface.
Figure 2. Part of the Web Interface for VLAN Change
On clicking the Change VLAN button, the script, using SNMP, changes the VLAN allocation for the specific port. Figure 3 shows the network flow.
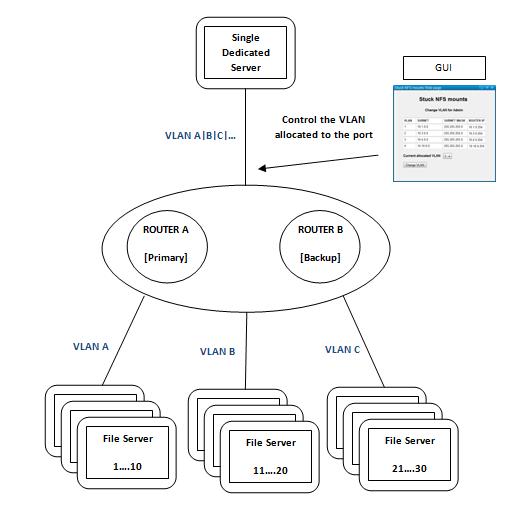
Figure 3. VLAN Change Diagram
Stuck mounts usually are identified by indirect symptoms exhibited by affected hosts, such as increased load due to a large number of processes in an uninterruptible sleep state or lsof not being able to complete its run. The first step is to open the Web interface and change the VLAN to that matching the unreachable file server. Once that's done, data-center operations technicians are instructed to change the IP address and default gateway on the Admin server to match that of the unreachable file server. Alternatively, the IP address and default gateway can be configured manually by logging in to the machine via the virtualization console and performing the change. The host IP address can be changed under /etc/sysconfig/network/ifcfg-ethx or ifcfg-eth-idxxx; the default gateway is configured under /etc/sysconfig/network/routes.
Once those two steps are complete, the network service on Admin needs to be restarted with /etc/init.d/network restart. The “fake” file server will come up and start rejecting NFS requests from affected hosts, releasing the stuck processes. At this stage, system administrators also can try to umount the stuck mounts.
We encountered a number of challenges in setting up this solution. On the network side, file servers are connected to routers; whereas compute servers are connected to switches. This necessitated an innovative approach by the network operations team, which resulted in the dedicated connection to the NFS router.
Furthermore, this solution requires allocating site assets to be used only rarely. We chose the virtual machine because of reduced cost and higher flexibility in the setup rather than using a physical machine. Finally, the IP/VLAN change procedure requires discipline and some skill on behalf of system administrators to use it effectively.
We first tried the stuck NFS solution as a hack by manually changing the IP address of a standard computer server located on the same segment as the unreachable file server more than a year ago. The attempt proved successful, and we were able to save a number of important infrastructure machines with stuck mounts, preventing downtime and reboots.
Prompted by this early success, we implemented the full solution and have used it on a number of occasions. In July 2010, we prevented a number of Samba servers from being rebooted, alongside another 21 compute servers.
The stuck NFS mounts solution has a direct impact on our ability to recover from unexpected file server outages. We also are able to mitigate scheduled file server EOL leftovers without reboots. In fact, one might argue that the solution creates leniency that may lead to lesser discipline in using strict file server EOL procedures, which requires all mounts to be removed before the file servers are shut down. We believe that the stuck NFS mounts solution does not replace hard work and adherence to procedures and should be used only in an emergency.
The stuck NFS mounts solution is a valuable asset and a necessity in large and dynamic environments. It allows us to maintain high uptime of important machines, without unnecessary reboots due to mistakes or file server traffic disruptions.
Our solution is simple and effective, and it has proven its worth on several occasions in real-life circumstances. The implementation is transparent to users and allows system administrators with no network operations of NFS permissions or extensive knowledge to recover systems quickly and easily. We recommend its use as a standard in computing environments that rely on NFS infrastructure.
The 2011 Readers' Choice awards are just around the corner, and we know you're all eager to vote for your favorites, but first, we want to make sure they're all included. Nominate your top picks for this year's awards at www.linuxjournal.com/rc2011 from July 6–20.
Several mathematics packages under the GPL are available on-line. You can find a package to help with almost any work you need to do, and in a way, you almost are spoiled for choice. But, if your work covers several areas of research, the one thing you likely are missing is a uniform interface to these tools. Sage fills that role (www.sagemath.org). Like most open-source software, Sage is available as packages for Linux, Windows, Mac OS X and Solaris. You also can download a live CD that boots up in a Linux environment based on Puppy Linux. And, of course, you always can download the source code and build it yourself. All of these options are available for download from the main site. The documentation also is very useful.
The basic idea behind Sage is to provide a unified experience when using the bundled packages. This is done through a Python framework wrapped around all of these packages. You can use Sage interactively in two different ways: a graphical interface or a terminal interface. When you start Sage, it starts up a Web server with a default port 8000. Once it has finished starting up (and it can take some time on some systems), simply point your browser at http://localhost:8000 (Figure 1). With this interface, you can create and manage your worksheets. The terminal interface (Figure 2) will be familiar to anyone who has used the command-line interface to programs like Maple, Mathematica, Maxima and so on. You also can use Sage in your own programs. You can link Sage into your own interpreted or compiled code, or you can write standalone Python scripts. This gives you access to all of the included libraries and packages, like GMP, PARI or Maxima.
Figure 1. The starting point in the Web interface is a display of your worksheets, along with tools to manage those worksheets and make more.
Figure 2. The console session allows you to interact with Sage in a form that may be more familiar to users of Maxima and Maple.
If you've used other computer mathematics packages, Sage basics should be easy to pick up. The assignment operator is =. The usual comparison operators are available: ==, <=, =>, < and >. The operators +, * and - mean what you expect. With division, you need to be more careful when dealing with differences between reals and integers. The % operator gives you the remainder from a division operation. If you are interested in the integer quotient, you can get it by using //. Exponentiation can be achieved using **, or ^, which is a synonym. You also have access to several mathematical functions, such as functions like sin(), cos() and tan(), and basic functions, like sqrt() or exp().
One of Sage's strong points is the available documentation. From within the system, you can access lots of help. You can pull up a description of a function, along with examples, with the command func?. For example, if you want to know more about the sine function, type:
sage: sin?
Base Class: <class 'sage.functions.trig.Function_sin'>
String Form: sin
Namespace: Interactive
File: /Users/bernardj/Desktop/Sage-4.6.2-OSX-64bit-10.6.app/
↪Contents/Resources/sage/local/lib/python2.6/
↪site-packages/sage/functions/trig.py
Definition: sin(self, *args, coerce=True, hold=False,
↪dont_call_method_on_arg=False)
Docstring:
The sine function.
EXAMPLES:
sage: sin(0)
0
sage: sin(x).subs(x==0)
0
sage: sin(2).n(100)
0.90929742682568169539601986591
sage: loads(dumps(sin))
sin
We can prevent evaluation using the ``hold`` parameter:
sage: sin(0,hold=True)
sin(0)
To then evaluate again, we currently must use Maxima via
``sage.symbolic.expression.Expression.simplify()``:
If you don't know the full name of the function, you can try Sage's Tab completion. It behaves just like the Tab completion in bash, so it should be comfortable for users of most Linux distributions.
Creating your own functions is easy. You can define a function with the command def. Input variables simply need to be listed in the definition. You don't need to specify type for any variables. The body of your function follows Python coding rules. Unlike other programming languages, you don't use special characters (like parentheses) to define sections of code. Blocks of code are defined by indentation level. Lines of code at the same indentation level belong to the same block. As a really silly example, let's say you wanted a function to calculate the cube of a number. You could define a function called cube in this way:
sage: def cube(x):
answer = x * x * x return answer
Then, you would be able to call this function just like you would with any other function:
sage: cube(3) 27
Within Sage, there is support for the common fundamental data types: integers, reals, strings and so on. There also is support for the compound data type, list. The list is opened with [ and closed with ]. Also, a list can contain any combination of data types. For example, a list could be defined as:
sage: a = [1, 5, "a string", 1/2, exp(10)]
You can access individual elements with an index. The index is 0-based. So, to pull out the third entry, you would use:
sage: s[2] 'a string'
Use the command len to find the length of your array. You can add or delete elements with the command .append() or del. As an example, if you want to delete the string and tack it onto the end of the array, you could use:
sage: b = a[2] sage: del a[2] sage: a.append(b)
A more structured compound data type is the dictionary or associative array. This is like a list, except each entry has a label along with a value. You could set up a mapping between letters and numbers with:
sage: mapping = {'a':1, 'b':2, 'c':3}
sage: mapping['b']
2
As you can see, you also define a dictionary with { and }, rather than [ and ]. Even more complex data types can be defined by creating a new class. A class has a couple standard functions you will want to override, __init__ and __repr__. The function __init__ gets called whenever a new instance of the class is created. You can place any initialization code here. The function __repr__ gets called whenever you want a representation of the object printed.
A common task you likely will want to do is solve equations, either exactly or numerically. You can do this with the solve command. Define the variables you want to use with the var command. Here's a simple example:
sage: x = var('x')
sage: solve(x^2 + 3*x +2, x)
[x == -2, x == -1]
You also can solve equations with multiple variables:
sage: x, y = var('x', 'y')
sage: solve([x+y==6, x-y==4], x, y)
[[x == 5, y == 1]]
If you're more interested in calculus, you can do differentiation and integration—for example:
sage: x = var('x')
sage: diff(sin(x), x)
cos(x)
sage: y = var('y')
sage: integral(y, y)
1/2*y^2
Sage is capable of handling 2-D and 3-D graphs. You can draw shapes, such as circles or polygons, by using commands with parameters to define dimensions. You also can draw graphs of functions with the plot command:
sage: x = var('x')
sage: plot(x^2, (x, -2, 2))
This displays your plot immediately. If you want to hold off on the actual display, you can assign the plot to a variable with:
sage: p1 = plot(x^2, (x, -2, 2))
To plot this function, use show(p1), which is useful if you want to plot more than one function on the same graph. For example, the following produces the graph shown in Figure 3:
sage: x= var('x')
sage: p1 = plot(x^2, (x, -2, 2))
sage: p2 = plot(x^3, (x, -2, 2))
sage: show(p1+p2)
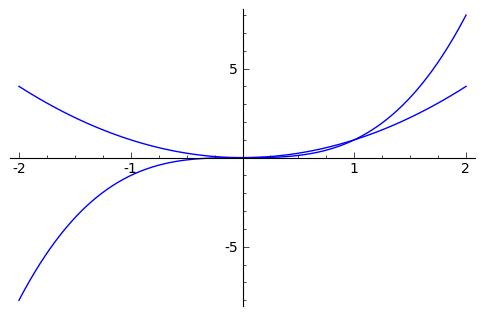
Figure 3. You can plot multiple functions on the same graph.
You can write your own Sage scripts for more complex applications. These can be written in a simple text file. Once you have written one, you can read it in and run it within Sage with the load command. For example, to run a script named test1.sage, do:
sage: load "test1.sage"
Using load, sage reads in the file only once. If you are working on developing a script, use the attach command instead. This attaches the script to your Sage session and reloads it whenever it changes, which is useful while you develop your own procedures.
The last step you probably will want to do is generate some kind of documentation around a fabulous discovery you made. Sage includes LaTeX functionality to allow you to produce really pretty output. You also can access jsMath for pretty printing mathematical equations.
This article barely scratches the surface of what you can do with Sage. With nearly 100 packages included, going through the documentation on the Web site is a must.
I believe that a scientist looking at nonscientific problems is just as dumb as the next guy.
—Richard Feynman
For a successful technology, reality must take precedence over public relations, for Nature cannot be fooled.
—Richard Feynman
There are 1011 stars in the galaxy. That used to be a huge number. But it's only a hundred billion. It's less than the national deficit! We used to call them astronomical numbers. Now we should call them economical numbers.
—Richard Feynman
The first principle is that you must not fool yourself—and you are the easiest person to fool.
—Richard Feynman
You can know the name of a bird in all the languages of the world, but when you're finished, you'll know absolutely nothing whatever about the bird....So let's look at the bird and see what it's doing—that's what counts. I learned very early the difference between knowing the name of something and knowing something.
—Richard Feynman
Cool Projects is one of our favorite topics at Linux Journal, and it's one we've explored quite a few times. There are so many cool projects in our archives, it's tough to know where to start.
Perhaps I could interest you in the programmable iRobot Create? The Create is an educational robot brought to you by the same folks who make the Roomba, so at the very least it'll be a great way to scare your pets and children! (See “Fun with the iRobot Create”: www.linuxjournal.com/article/10262.)
Maybe you'd like to get super geeky and/or ferment some beer? Either would be a noble pursuit, so check out Kyle Rankin's article “Temper Temper” (www.linuxjournal.com/article/10809). My favorite quote says it all: “I mean, why wouldn't you power your fridge with Linux if you had the chance?”
And, if you haven't already, you must check out one of my all-time favorites: “Build Your Own Arcade Game Player and Relive the '80s!” by Shawn Powers (www.linuxjournal.com/article/9732). I dare you to read it and not be nostalgic for the 1980s. (Unless, of course, you don't remember the 1980s, and then get off my lawn! Only joking, I love you too.) Just looking at the pictures, I swear I can smell the rancid spilled Coke and hygienically challenged teenage boys in the mall arcade. Ah, the good-old days.
WPAD certainly isn't new technology. In fact, it's been around for many years. However, it seems that many system administrators are unaware of its magic. Simply put, WPAD allows you to offer proxy information to users in your network without ever touching their computers. The feature is supported by most browsers, and in general, it “just works”.
Although proxy information can be sent over DHCP, unfortunately, not all clients honor those settings. For maximum compatibility, it's best to have a local DNS record that points the domain “wpad” to a Web server. You put a configuration file named wpad.dat in the root level of that Web server, and clients get proxy information automatically, assuming they're configured to do so. (Most are by default; this is what your browser refers to as automatically detecting proxy settings.)
Here's a simple wpad.dat file:
function FindProxyForURL(url, host)
{
if (isPlainHostName(host) ||
dnsDomainIs(host, "my.local.network.domain.org") ||
(host=="127.0.0.1") )
return "DIRECT";
else
return "PROXY my.proxy.server.address:8080";
}
For more detailed information on how to configure your custom wpad.dat file, check out en.wikipedia.org/wiki/Proxy_auto-config.
And, for more information on the Web Proxy Autodiscovery Protocol itself, see en.wikipedia.org/wiki/Web_Proxy_Autodiscovery_Protocol.
