
The KVM API has been accruing cruft for many years, a result of the natural process of being an actively developed project and having a lot of crazy deep requirements for virtualizing systems. It's hard to just up and redo an API that's already well established though, so Avi Kivity suggested either a thought experiment of how it might be done or, at most, a co-API that would sit side by side with the original one for several years.
Interesting enough, one of the things people favored in the original crufty interface was the ease of producing cruft. Specifically, Avi wanted to migrate away from ioctls as the primary interface and replace them with system calls. This would be cleaner than the crawling chaos of ioctls, but folks like Alexander Graf and others argued that KVM still was under hot development and definitely was going to need an unknown vector of extensions, and ioctls made that kind of development very easy.
So, this is more of a negative news story: hot flash—KVM interface to remain unchanged! But still, it's interesting because Avi seems to be right. The KVM API has a lot of unnecessary craziness, such as the way the virtualized CPU state is handled. The current cluster-bomb of ioctls in that area could be replaced by just two system calls that would operate on a single orderly data structure. And, there are other similar areas he points out. But apparently, the pace of development will have to slow down, and the interfaces stabilize, before those cleanups really will be practical.
Rakib Mullick is working on a new approach to load balancing between multiple CPUs on an SMP system. The Barbershop Load Distribution (BLD) algorithm keeps track of any change to the load on each CPU and always assigns new processes, and processes coming in from swap-space, to the least-loaded CPU.
Because the preferred CPU is known instantly at the time a process needs to be assigned, the BLD has a speed of O(1), which means it takes the same amount of time to identify the appropriate CPU, regardless of whether there are 2 or 2,000,000 CPUs from which to choose.
As Rakib explains it, this is load balancing without load balancing, because the actual effort to balance the load never takes place. The appropriate CPU simply is picked from an ordered list of all CPUs that already has been sorted by total load.
His code is still under development and hasn't been given a thorough going-over by many developers. It could turn out to be an obvious improvement that is accepted quickly, or it could fall victim to the fact that process migration tends to be a deep, dark art with many incantations and strange requirements. Time will tell. But, it seems like Rakib's got a fun piece of code that inevitably will gain some interest among CPU people.
Periodically, someone expresses frustration at how difficult it is to test scheduler improvements. This time it was Pantelis Antoniou, who has been working on big.LITTLE architectures. The idea behind big.LITTLE is to have a device with two CPUs: one smaller and weaker that handles ordinary operations, and the other bigger and more powerful that gets processes requiring more kick. Any process on the smaller CPU that starts to get too active will be migrated over to the bigger CPU in a seamless fashion. Devices like this have been coming out lately because they tend to have longer battery life than traditional systems, but they're radically different from the SMP-oriented scheduling that Linux grew up with.
Pantelis has suggested implementing some kind of user session recording and playback, so that a large corpus of typical user activity could be built up and then used to test improvements to Linux's scheduler code. As it turns out, some rudimentary session recording tools already exist, but they'd need a lot of work in order to be useful for scheduler testing. And, one potentially big obstacle is the fact that any type of recording undoubtedly would slow down the user interface, changing user behavior and tainting the sample.
But, it still seems like a cool idea. Scheduler advancement is a nightmare of uncertainty in which debates often take the form of the following: “We should do this!” “Why???” “Because I say so!” “Well, I say something else!” “Oh yeah?”, and so on.
I remember the first time I tried to install Quake on Linux. I was so excited to have a native “real” game to play, that I couldn't grab my installation CD fast enough. Unfortunately, I didn't really take good care of my media, and the CD was too scratched to read.
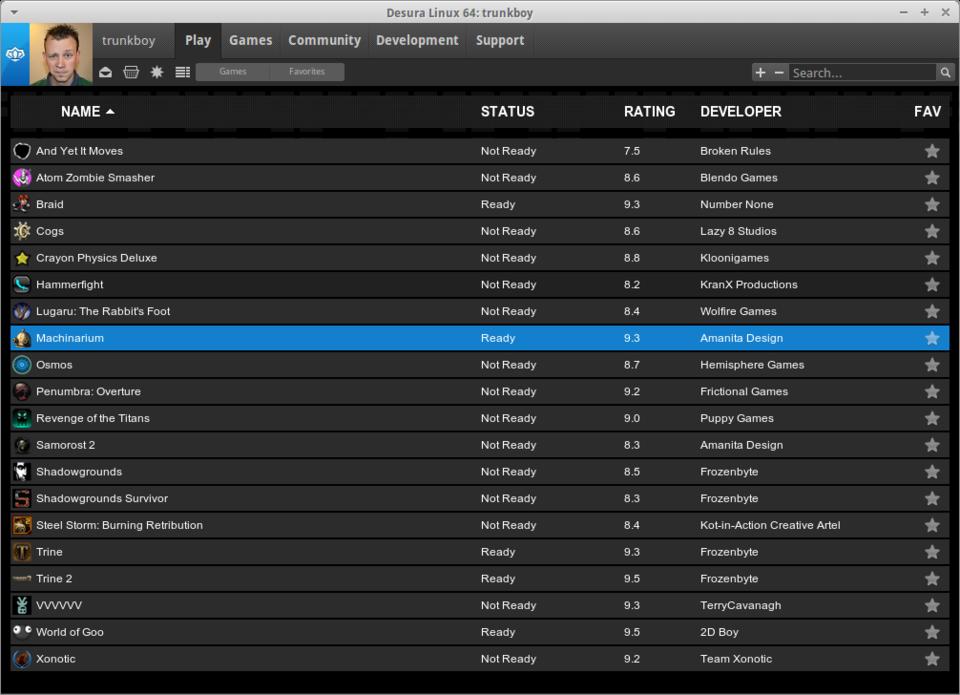
I suspect something similar happened to the inventor of Steam for Windows. Having a permanent on-line archive of your video game library is awesome. Unfortunately, Linux users not only don't have Steam, but it seems like every game we do have installs in its own unique way. Some have binary installers; some are in the package management system; some must be compiled.
Thanks to the fine folks at Desura, Linux users finally get to play with the cool kids! Although obviously a clone of the Steam idea, Desura does an incredible job of simplifying management and installation. It has a built-in game store offering free and for-pay games, and it even supports “codes” for activating games purchased elsewhere. (My favorite “elsewhere” is the awesome Humble Bundle site that periodically sells Linux-compatible games.)
If you're a gamer and a Linux user, you owe it to yourself to give Desura a try. You can download it at www.desura.com. And if you like Linux-compatible games, be sure to check out www.humblebundle.com from time to time.
Usually it's Linux folks who are left out in the cold with regard to cool software. In the case of Pandora Radio, however, it's tough to beat the Linux native Pithos application. Thankfully, Windows users have an open-source option for native Pandora Radio playback as well. Elpis is a .NET Pandora application available for Microsoft Windows.
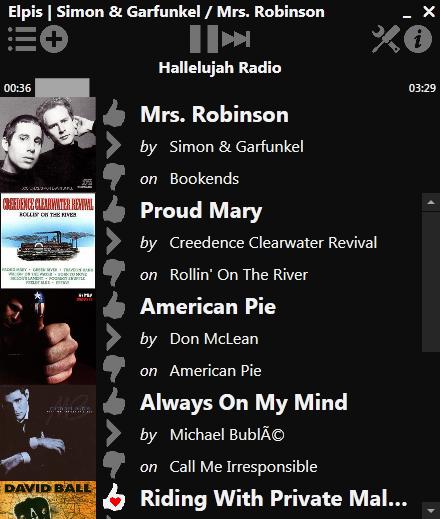
We still think Pithos looks nicer and has a smoother interface, but if you're stuck on Windows, Elpis is fully open source and under active development. A screenshot is worth a thousand words, but if you want to check it out for yourself, visit www.adamhaile.net/projects/elpis.
NASA has started a rather ambitious project: to provide open-source everything. The main site is located at open.nasa.gov. From here, there is access to data, code and applications, among other things. This is a great launching point for anyone interested in space science and NASA work. In this article, I look at what kind of code is being made available that you might want to explore.
The available software covers several genres. Some are low-level, systems-layer software. You can go ahead and do some really long-distance transfers with the Interplanetary Overlay Network (ION). This is an implementation of the Delay-Tolerant Networking architecture (DTN) as described in RFC 4838. This software is physically hosted at SourceForge, and you can use this code to communicate with your next interplanetary probe.
A bit more down to earth is a middleware package that actually is hosted by the Apache Foundation. You can download and use the Object-Oriented Data Technology (OODT) middleware. OODT is component-based, so you can pick and choose which parts you want to use. There are components to handle transparent access to distributed resources, data discovery and query optimization, and distributed processing. There are also components to handle work-flow and resource management. Groups that are using it include the Children's Hospital of Los Angeles and NASA's Planetary Data System. If you're managing data systems, this might be worth taking a look at.
Getting back to actual science processing, you might want to download the Data Productivity Toolkit (DPT). This package is a collection of command-line tools, written in Python, that lets you work on text data files. These utilities follow the UNIX design method of having small utilities that do one task well, and then chaining them together to do more complicated processing. There are tools for massaging and manipulating your data, tools for doing statistics on that data and even tools for visualizing the data and the results. Many of the tools even provide an API to basic Python and numpy/scipy/matplotlib routines.
And, while I'm talking about Python and science, you also can look at SunPy. SunPy aims to provide a library of routines that are useful in studying solar physics. With it, you can query the Virtual Solar Observatory (VSO) and grab data that you can process. Many routines are available that allow you to plot this data using various color maps and processing filters. There is a Sun object that contains physical constants useful in solar physics, along with the sun's position and numerous other solar attributes.
A lot of the computational work done at NASA involves clusters of machines and massively parallel code. This means the NASA folks have needed to put together lots of tools to manage these machines. They also have been nice enough to release a lot of this code for public consumption. The first of these is multil (Multi-Threaded Multi-Node Utilities). In the standard GNU file tools, cp and md5sum operate as a single-threaded process on a single machine. The multil tools provide drop-in replacements called mcp and msum. These utilities use multithreading to make sure each node is kept as busy as possible. Read and write parallelism allows for individual operations of a single copy to be interleaved through asynchronous I/O. Split file processing allows for different threads to operate on different portions of a file in parallel.
NASA also provides a utility to give SSH access to your cluster. There is a middleware utility called mesh (Middleware Using Existing SSH Hosts) that provides single sign-on capability. Mesh sits on top of SSH, and instead of using the local authorized_keys file, loads a file for a dedicated server at runtime. Mesh also has its own shell (called mash) that restricts what applications are available to the user. Using this system, you can add and remove SSH hosts that are available to be used dynamically. Also, because the authentication is handled by a library that is preloaded when SSH first starts up, the restrictions are sure to be enforced on the user.
Now that you have a connection mechanism, you may need to handle load balancing across all of these machines. Again, NASA comes to your aid. It has a software package called ballast (Balancing Load Across Systems) that might help. This package handles load balancing for SSH connections specifically. Each available host runs a ballast client, and there are one or more ballast servers. The servers maintain system load information gathered from the clients and use it to make decisions about where to send SSH connection requests. Because all of this is handled over SSH, the policy deciding which host to connect to also can take into account the user name. This way, you can have policies that are specific to each user. This lets you better tune the best options for each user, rather than trying to find a common policy that everyone is forced to use.
Going back to doing science, another important task is visualization, and NASA has released several tools to help. The first one I look at here is World Wind. This is an Earth visualization system. You can use it to get a 3-D look at Earth and to see data projected onto the globe. It is a Java application, so it works on any desktop that has a Java virtual machine, as well as in most browsers. It is a full development kit, and it has several example applications that you can use as jumping-off points for your own code.
Taking visualization further from the surface of the Earth, there is ViSBARD (Visual System for Browsing, Analysis and Retrieval of Data). This application allows you to pull data from multiple satellites and display them concurrently. It also allows for 3-D viewing of all of this data. This type of vector field information is very difficult to analyze in 2-D plots, hence the need for this kind of tool. The latest version also allows you to visualize MHD (Magneto-Hydro-Dynamic) models. This way, you can compare results from model calculations to actual satellite measurements.
More extensive image processing can be done with the Vision Workbench. This is an application and a full library of imaging and computer vision algorithms. It isn't meant to be a complete, cutting-edge library though. Rather, it provides solid implementations of standard algorithms you can use as starting points in developing your own algorithms.
When you're ready to go and launch your own satellite, you can download and use the Core Flight Executive (cFE). This software is used as the basis for flight data systems and instrumentation. It is written in C and based on OSAL (Operating System Abstraction Layer). It has an executive, along with time and event services. You can track your satellite with the ODTBX (Orbit Determination Toolbox). The ODTBX package handles orbit determination analysis and early mission analysis. It's available as both MATLAB code and Java.
The last piece of code I cover here is S4PM (Simple, Scalable, Script-based Science Processor for Measurements). This actually is used at the Goddard Earth Sciences Data and Information Services Center to do data processing. It is built up out of a processing engine, a toolkit and a graphical monitor. S4PM allows a single person to manage hundreds of jobs simultaneously. It also is designed to be relatively easy to set up new processing strings.
The open-source project at NASA doesn't cover only code. NASA has been releasing data as well. The Kepler Project is looking for exo-planets. As I mentioned previously, you can download data from the Solar Dynamics Observatory. You can work on climate data by checking out information from the Tropical Rainfall Measuring Mission. You can look up tons of data from the various moon missions, from Apollo on up. There also is data from the various planetary missions. Climate data and measurements of Earth are available too.
I've touched on only a few of the items NASA has provided for the public. Hopefully, you have seen enough to go and check out the rest in more detail. There is a lot of science that regular citizens can do, and NASA is doing its part to try to put the tools into your hands.
Plex always has been the Mac-friendly offshoot of XBMC. I've never considered using an Apple product for my home media center, so I've never really put much thought into it. Things have changed recently, however, and now the folks behind Plex have given the Linux community an awesome media server.
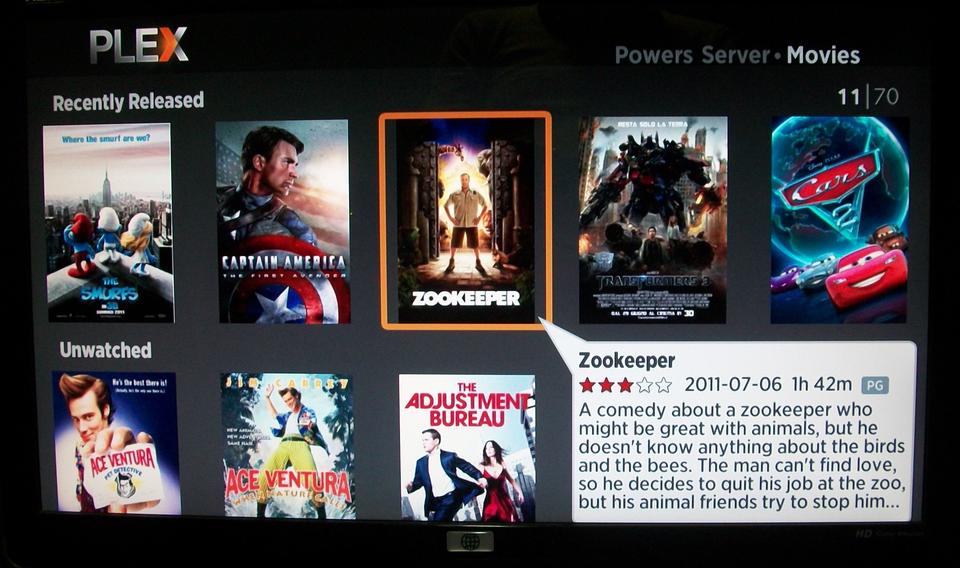
Installing the media server is fairly straightforward. Instructions are available at www.plexapp.com. The server application runs on a headless Linux server and is configured via a Web interface. After you've pointed Plex Media Server at your video collection, the real magic begins.
Fire up your Roku, any model, and search for the Plex channel in the Roku Channel Store. With some simple configuration, your Roku will be able to browse your entire media collection and stream HD video to your television. The responsiveness is incredible, and the video quality is astounding. I was expecting pixelated video with stuttering playback over wireless, but everything was smooth. Your local media behaves just like Netflix! For more information, check out the Plex Web site: www.plexapp.com.
Technology makes it possible for people to gain control over everything, except over technology.
—John Tudor
If GM had kept up with technology like the computer industry has, we would all be driving $25 cars that got 1,000 MPG.
—Bill Gates
Technology...is a queer thing. It brings you great gifts with one hand, and it stabs you in the back with the other.
—Carrie P. Snow
Technology does not drive change—it enables change.
—Unknown
Men are only as good as their technical development allows them to be.
—George Orwell
One of the great things about independent game companies is that they realize Linux gamers exist—and we're willing to spend money. Frozenbyte is the indie game developer that brought us Shadowgrounds, Shadowgrounds Survivor and Trine. Frozenbyte was kind enough to send me a review copy of its newest release, Trine 2.
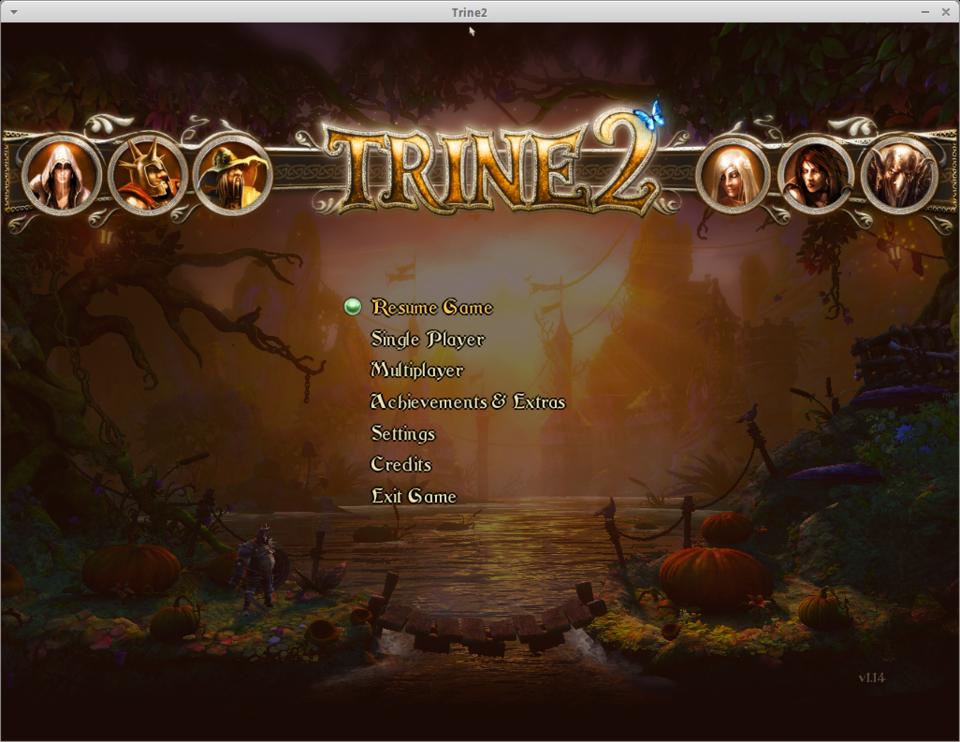
As an obvious sequel to the original, Trine 2 is a platform-based side-scroller. It has stunning graphics, rich sounds and a pleasant storyline. The game revolves around solving physics puzzles in a fantasy-based world. It's no secret I'm a rather poor gamer, but Trine 2 is enjoyable even for a part-time player like myself. It also supports multiplayer co-op mode for up to three players. Multiplayer mode works both on the local network and over the Internet.
I'll admit, it took a little while to get used to jumping with the W key (Trine 2 uses the WASD keys for movement), but that wasn't a big deal. I was able to jump right in and start playing. I truly appreciated the ability to skip past cut scenes and get right to the action. If you're in the mood for a fun game with great graphics, I highly recommend Trine 2.
The Collector's Edition comes with a digital artbook and soundtrack. You can buy it through the Humble Store now at www.trine2.com or from the developer's Web site, www.frozenbyte.com.
Visit this newest section of LinuxJournal.com at www.linuxjournal.com/whitepapers to find carefully selected resources from Linux Journal partners that will help you with topics from version control to automation, multimedia and more. Is there a topic you'd like to see covered? Please let us know by sending e-mail to info@linuxjournal.com, and we'll do our best to accommodate.
