
Mimi Zohar recently submitted a patch to provide greater protections for cryptographically signed modules. When signing modules without Mimi's patch, users generate a public and private key, and then use their private key to sign all the kernel modules they intend to use on their system. The kernel is built with the public key, and so it can verify the signature. Users keep the private key hidden and can use it to build additional modules in the future. Attackers are stymied because they are unable to load their hostile, unsigned modules into the system.
The problem with this is that attackers can discover users' keys somehow, and proceed to sign and load their hostile modules. Mimi's idea is to generate a public and private key automatically during the kernel build process, and then destroy the private key afterward. Attackers would be able to discover the key only if they'd been watching at the very moment the build took place.
The drawback is that when the private key is destroyed, users lose access to it as well and, thus, are unable to sign any more modules to run on that system, unless they go through the entire build process again. So, Mimi's code offers increased security, at the cost of a more rigidly planned system.
It's a point of pride, or at least good practice, for the kernel developers to make sure that Linux continues to compile using the most ancient possible versions of all the tools. Really what that means is that they want the kernel to compile using as many different versions of the tools as possible, both modern and old. This way, anyone with a computer of some sort will have a reasonable certainty of being able to compile the kernel without too much fuss.
So, when Rob Landley discovered that the venerable version 3.2 of the GNU C Compiler would no longer compile the 3.7 Linux kernel, it was a big deal. According to his tests, only GCC versions after 4.2.1, from 2012, would compile the latest kernels.
Shaun Ruffell replied to Rob's report, saying that Jan Beulich had a patch that would restore compatibility with the old compilers. It was a three-line patch, and Shaun said it seemed like an obvious fix. No difficulties are expected with getting it into the kernel.
Unfortunately, since the 3.7 kernel already had been released with the bug, there was no way to fix that particular kernel retroactively. The 3.8 kernel almost certainly will have the fix though; at which point Greg Kroah-Hartman and his group of stable tree maintainers also will accept the patch into the stable 3.7 series. So ultimately, the latest 3.7 kernels will compile under GCC 3.2 again.
The Ubuntu team, represented by Herton Krzesinski, has announced that it plans to maintain a stable series of 3.5-based Linux kernels, until March 2014. Herton announced the first release of the new series, Linux 3.5.7.1, and invited users to adapt it to any purpose they saw fit. The Ubuntu team was focused on using the kernel in Ubuntu, but welcomed a wider variety of distributions to rely on the same kernel.
Minchan Kim has submitted some code to add a couple new system calls to the kernel. The calls, mvolatile() and mnovolatile(), allow user programs to let the kernel know that they no longer need certain memory pages. The kernel then could release those pages back to the system for other programs to use.
These are not to be confused with the existing madvise() system call, which also allows user programs to give the kernel information about memory usage. But while mvolatile() and mnovolatile() help the kernel free up memory, madvise() helps the kernel use read-ahead and caching more efficiently to speed things up.
There's some disagreement over whether Minchan's code provides enough benefit to justify adding new system calls, and it's possible the same feature could be implemented without them. But certainly, if there's a way to help a system use memory better, I'd imagine such a feature eventually would go into the kernel in one form or another.
Gurk really shouldn't be awesome. The controls are awkward on-screen arrow keys. The graphics make the original Nintendo look state of the art in comparison. The gameplay is slow.
And yet I just spent two hours straight playing it!
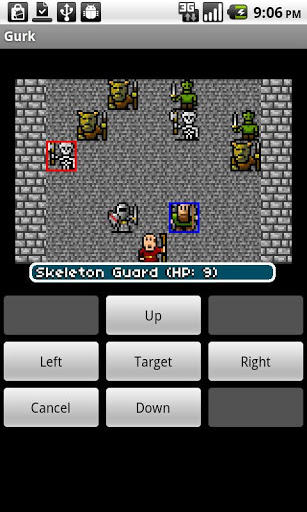
Image via Google Play Store
If you ever spent hours and hours battling slime molds in Final Fantasy, or, like me, you feel turn-based fighting is how civilized people should battle, Gurk is made for you. It takes all the old features of turn-based RPG games of the 1990s and puts them into your modern Android tablet.
There are some incredible emulators available for Android, and they will indeed let you play the old classic NES RPG games. The problem is, they all require ROM files that are legally questionable. Gurk provides that same nostalgic gameplay, but in a program natively created for your phone or tablet. And if you fall in love with Gurk like I did, there's also Gurk 2, which costs a couple dollars, but it looks even more incredible than Gurk!
Check it out today at https://play.google.com/store/apps/details?id=com.larvalabs.gurk.
Not long ago, I wrote about how awesome it is to have shell access on a remote server. I still hold to that notion, but I received a lot of feedback on the issue. If you've considered paying even a couple dollars a month for shell access on a server, you might want to check out www.lowendbox.com.

Image from www.lowendbox.com
Although not a provider itself, lowendbox indexes all the best deals out there for full root access to your own server. Most of the servers are true to their name and provide only minimum specifications, but if a simple command shell is what you want, purchasing a small server instance in the cloud might be the way to go. I know I was happy to hear such things existed.
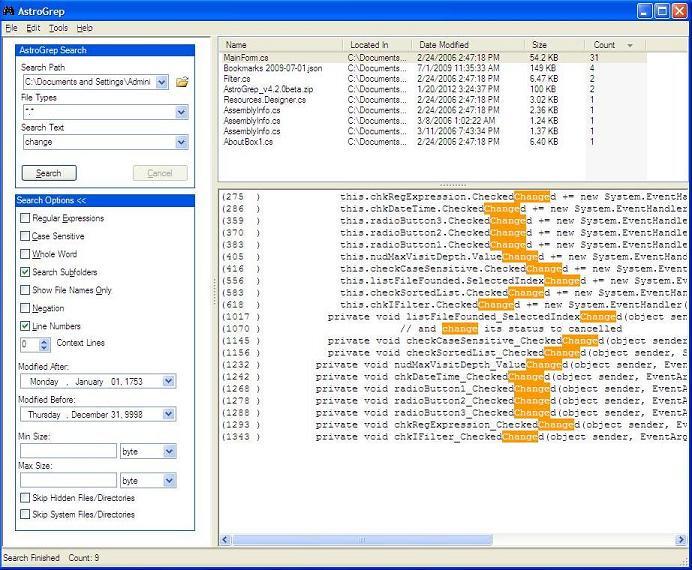
Sometimes when you're stuck on Windows, it's the simple things that are most frustrating—typing ls in a command window, trying to edit a file with vi or doing something as simple as grepping. Thankfully, when it comes to grep, there is hope!
Screenshot from astrogrep.sourceforge.net
Astrogrep is an open-source Windows application that brings the power of grep (which so easily is taken for granted) to Windows. I still find it a little more cumbersome than simply piping something into grep on the command line, but in true point-and-click fashion, Astrogrep gets the job done. If you're on Windows and wish you had grep, try Astrogrep: astrogrep.sourceforge.net.
In almost any business, knowing how long it takes for something to happen can be critical for meeting deadlines. For example:
How long does it take to design a semiconductor?
How long does it take to run a 24-hour weather forecast?
How long does it take to produce an article?
The price of not knowing is manufacturing delays, inaccurate weather predictions or an angry editor.
Given the native unpredictability of writers, not much can be done about the last one. But if you are a semiconductor company doing chip design work, you're undoubtedly running a high-throughput workload on distributed multicore systems. You might think that if you run the same test 1,000 times, each test would take the same amount of time. However, through bad job placement, the run time of each test can vary dramatically. In much the same way if you're running weather simulations across multiple systems, you need to know how long each simulation will take or your weather forecast could end up telling people about the hurricane that happened yesterday.
In many industries, manufacturing deadlines are set long before a design is complete. For example, suppose the marketing department of a cell-phone company already has announced when the next new phone that uses your semiconductors is going to be available. Slipping the schedule for shipping that phone could be costly and have a serious impact on your revenue. In other situations, the deadlines may be completely out of your control and being late is unacceptable. In Formula 1 racing, the race calendar is set more than a year in advance. Showing up to a race without a functional car is obviously not an option.
If the run times of your application jobs are unpredictable and you have dozens of jobs competing with one another on the same machine, you start missing deadlines for getting your designs out to manufacturing. Missing deadlines costs money. However, if each one of the jobs you run is predictable, you can meet delivery schedules and everyone is happy.
The Goal of Repeatable Performance
As data centers increase in size and complexity, it becomes more difficult to manage workloads, scale applications and make the best use of hardware and other resources. End users need to be able to access applications and clusters anywhere and automate their data flows. Administrators need to be able to monitor cluster resources and workloads so they can identify bottlenecks and plan capacity.
In high performance computing (HPC) situations, achieving repeatable performance on application jobs is a key to quality of service. The speed of a job is determined by the speed of the slowest part of the process, which drags down the performance of the whole application. Running each node exactly the same way, with the same core and memory topology guarantees repeatable (and maximum) performance.
Although purists may disagree, today's x86 processors are essentially a NUMA architecture. NUMA stands for Non Uniform Memory Access. A processor and memory form a NUMA node, which may contain multiple cores. Access to memory within the same NUMA node is considered local access, and access to the memory belonging to the other NUMA nodes is considered remote access. Because access between computational cores and memory is not uniform, if you are unlucky enough to be allocated cores and memory that are far apart, the run time of your application can increase significantly. It gets even worse when multiple applications that are running on the same node all have bad allocations. The Linux kernel scheduler works to minimize this problem, but in many cases the access is still not optimal.
With nodes becoming more dense, you may want or need to run multiple applications on the same node to increase utilization. However, multiple applications may interfere with each other, which can lead to a loss of performance or instability. The enterprise way of mitigating this situation was to carve up the physical hardware into lots of smaller virtual machines. However, in an HPC environment, the overhead associated with virtual machines often makes that approach problematic. The other issue you run into is that the requirements of HPC workloads often vary on a job-to-job basis, so it is impractical to statically subdivide the node.
The New Way
IBM Platform LSF is a workload management platform for HPC environments. With the Platform LSF policy-driven scheduling features, you can take advantage of your infrastructure resources and ensure that your applications perform optimally. Platform LSF allows a distributed network to function somewhat like a large supercomputer by matching supply with demand. It distributes the right jobs to the right resources, so you can optimize resource utilization and minimize waste. To users, Platform LSF makes multiple computing resources appear as a single system image as it load-balances across shared computing resources.
The most recent release of Platform LSF, version 9.1.1, takes advantage of control groups in the Linux kernel scheduler. With this feature, you can limit and isolate the use of resources like CPU, memory and disk I/O of process groups. Using control groups, the resources of the node can be shared between different workloads, which ensures that one production workload doesn't interfere with another. So, for example, your production workloads can share extra spare capacity with your test workloads. Control groups also protect one application from memory leaks in another, which gives you repeatable results and predictable run times. The Platform LSF support for control groups means that you now have the same type of topological control within a machine that you always have had among machines based on how they were connected.
Platform LSF enables us to schedule some of the big analysis computation so that our engineers don't have to wait around for an analysis to finish before starting another. They can also run analyses in parallel with each other.—Steve Nevey, Business Development Manager, Red Bull Technology
Optimally Place Workloads
The distance between the memory and core is critical to the performance of an application. You can take advantage of the core and memory affinity features of Platform LSF to place workloads optimally within a node to ensure that the allocated cores and memory are as close to each other as possible. For certain types of applications, the performance of an application can change dramatically depending on how it is allocated. For example, if you're running an engineering application, you want to have the memory and core near each other to minimize latency and maximize performance.
For HPC Message Passing Interface (MPI) applications, you also want to make sure the same cores and memory are allocated on each node that is allocated to the job. To ensure optimal performance, you want fine-grained control of the topology of the application both between nodes and within the node. In many cases, the core-to-memory ratio that the application can use is often not the same as how the hardware is procured. In some cases, the job may consume 50% of the cores, but use 80% of the memory on each node. So if you want to use that leftover core capacity for a smaller workload, you need to be certain it won't use more than 20% of the core, otherwise it would affect the distributed parallel workload.
Linux Neutral
Through the years, much of the Platform LSF market has moved away from proprietary UNIX hardware to predominantly Linux and x86 solutions. Many Platform LSF customers have been interested in support for Linux control groups, but it initially wasn't possible to include in the Platform LSF main code because so many customers still were running older versions of Linux. However, even before it became part of IBM, Platform had a vision of creating a “distribution neutral” version of Platform LSF for Linux. Because the latest version of Platform LSF is “Linux neutral”, you can use the same Platform LSF binaries, no matter what Linux distribution you may be running.
Cores and More Cores
The use of control groups in Platform LSF lets you take advantage of the increasing density of servers. Every year, Intel puts more cores on each chip, and cost-conscious companies want to get more chassis on each rack to lower their space and cooling expenses.
Although Platform LSF may not be able to help you ward off the ire of an angry editor, if you're working in a large data center with big data and computing-intensive problems to solve, it can help you take advantage of all the computing power you have and meet your deadlines.
My last several articles have covered lots of software for doing research in the sciences. But one important area I haven't covered in detail is the resources available for teaching the next generation of computational scientists. To fill this gap, you can use the code provided through the Open Source Physics project (www.compadre.org/osp). This project is supported by the American Association of Physics Teachers (AAPT) and the National Science Foundation (NSF), and it offers several different packages for doing simulations and analysis.
The first thing Open Source Physics provides is an entire suite of Java applications that do simulations of different physical systems. Because these simulations are all written in Java, they can be run on operating systems other than Linux. The categories covered include astronomy, electricity and magnetism, classical mechanics, quantum mechanics, optics and relativity. On the main Web site, you either can do a specific search or browse by topic to find simulations. The simulation programs are packaged as .jar files, so you can download them and run them simply by typing:
java -jar filename.jar
This lets you run the simulation on your desktop. But, because these are Java programs, you can put them a Web site and run them within a browser. This means you can include them on your science site and show visitors simulations of the systems you might be trying to explain.
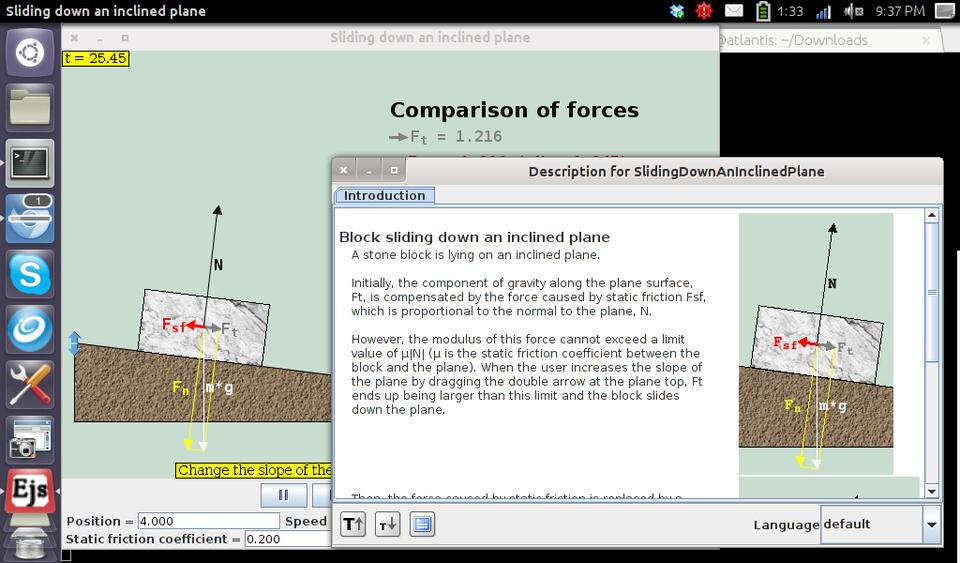
Figure 1. For example, starting up the simulation of sliding down an inclined plane also pops up some introductory material.
Some of the simulations provided by Open Source Physics have parameters that you can alter to change the runtime details of the simulation. These parameters might be items like masses, velocities or field strengths. If the simulation you are using does have settable parameters, there will be an option to save the model details off to a data file. You can do this by clicking File→Save Model. The data file is an XML file, so it should be relatively clear if you want to edit the file directly with a text editor. You then can reload these parameters in the simulation by clicking File→Load Module. This way, you can share models you've developed with other people by sharing the XML data file.
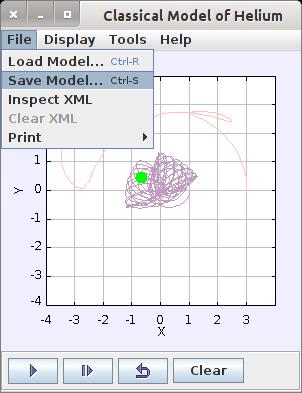
Figure 2. Saving a Run for Sharing with Other People
Once you have gone beyond the material covered by the pre-packaged simulations, you probably will want to see what other systems you can model and analyze. Open Source Physics provides a system called Easy Java Simulations (EJS) to do just that. This Java program provides a nice and easy interface to allow for prototyping, testing and distributing your own simulations. EJS is good for educational situations because it allows for relatively complex simulations without needing to know a great deal about programming.
EJS is larger than the single simulations I mentioned above, so you need to download a zip file rather than just a single jar file. Once you have the zip file downloaded, you need to unpack it on your machine. Then you can navigate to the directory where you unpacked and execute:
java -jar EjsConsole.jar
This pops up a console window where you can set some initialization parameters and start one or more EJS instances. This opens a modeling and authoring tool where you can define your physical system and the details of what you are trying to model. You can run these models from within the authoring tool, so you can try things out and see whether you are getting the results you expect. Once you are happy with the simulation, the authoring tool has options to allow you to package the entire simulation as a single bundle that you can share with others. This is great when you are developing code for a class, because you can define simulations for the exact physical systems you want to teach and then package it for your students.
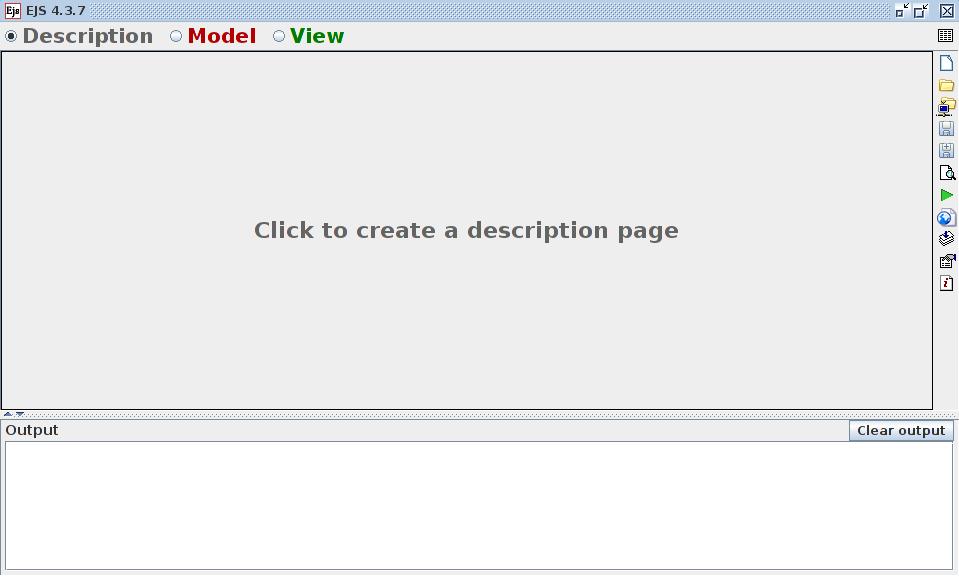
Figure 3. The EJS console lets you define your own simulations.
Open Source Physics aims to help with all aspects of teaching, so to this end, it provides a program called the Launcher. The Launcher is a central program that provides access to a series of simulations, along with supporting documentation and teaching notes. You can click on the curriculum link and search for collections that cover specific topics. Just like with the individual simulations, you either can search for a specific item or browse a list of topics for which there are curriculum launchers already prepared. You are not limited to those, however. You can use the LaunchBuilder to create your own collections. This utility lets you define the materials you want to bundle together, and then it will output a jar file that you can distribute. The actual material list is stored as an XML file, so you can open it with a text editor if you want to refine any of the entries before actually generating the distributable file.

Figure 4. The Data Tool helps you do basic statistics on your data.
When you are ready to go even further, the Open Source Physics project has an entire programming environment available based around the Eclipse IDE. This IDE includes the Open Source Physics libraries that are used in the simulations and the EJS code. This way, you can go further and develop your own programs without having to re-invent the wheel when it comes to common tasks. A lot of documentation is available, including several chapters of two upcoming books titled Open Source Physics: A User's Guide with Examples and An Introduction to Computer Simulation Methods.
The Open Source Physics project provides two other tools: Data Tool and Tracker. First, let's look at Data Tool. Data Tool provides plotting and data-fitting functions to help you analyze experimental data. You can change the appearance of plots interactively by selecting parameters on the main screen. Once your data is loaded, Data Tool also can do basic statistics on the data set. So, you quickly can get items like mean, median and standard deviation. With your data plotted, you can get the slope and area under curves in the plot. Often, you collect data to try to demonstrate some relationship between inputs and outputs. To verify this, you try to fit some function to your data. Data Tool provides a number of predefined functions that you can ask it to try to fit. Or, you can use Fit Builder to define your own functions to be used in the fitting routine. You also may find that you need to massage your data before either plotting it or trying to fit it. This may involve applying different types of mathematical transformations to your data. In regular data analysis, this would be a step you would handle before importing your data, but Data Tool provides a function called Data Builder that allows you to do this right here.
The last tool to look at here is Tracker. Tracker can do image and video analysis by using the functionality in the Open Source Physics library. Tracker is capable of object tracking in video, giving you position, velocity and acceleration. It can provide overlays and graphs, special-effects filters, multiple reference frames and calibration points. It even can be used to analyze spectra and interference patterns, allowing you to analyze laboratory measurements. As an example, you can overlay simple dynamic particle models on top of a video clip. This allows you to take a video of an experiment and then use it to make your measurements and analysis. There are several examples on the Web where people have used this to model all kinds of events, including modeling the physics of Angry Birds. A quick Google search will open your eyes to what is possible.
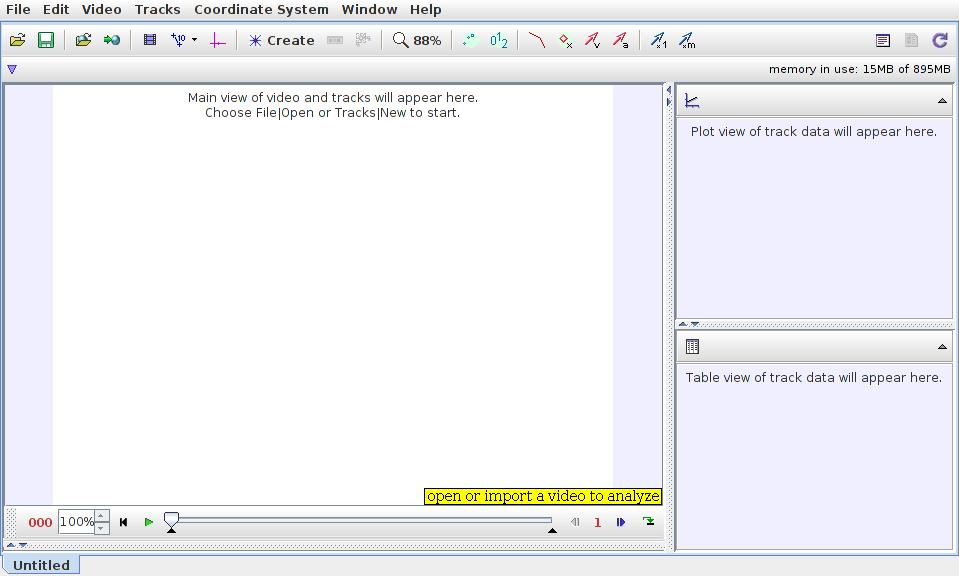
Figure 5. The tracker handles video analysis with object tracking.
This short article barely scratches the surface of what is available. If you are either teaching physics or learning physics, exploring the Open Source Physics project definitely will be worth your time.
It seems as though all the cool kids are addicted to Evernote. I'm not quite that cool, but I have been trying hard to convert to a paperless lifestyle. Evernote admittedly is a great tool for archiving information. When I bought my Nexus 7, I also bought a subscription to Evernote Premium. I'm still not completely sold on the Evernote lifestyle, but because I spent money, I'm far more inclined to give it a solid go.
When it actually comes to using Evernote, there is a native client for both Windows and Macintosh that keeps in sync with the Evernote cloud and all your Evernote-enabled devices. The Web interface is quite robust, but there are times when I'm off-line and really want to take some notes on my Linux machine. Enter: Everpad.
Everpad is a client for the Evernote “world”, and it syncs your Linux machine much the way the native Evernote programs do with Windows and Mac. Not only do you get a way to access your notes (Figure 1), but the truly awesome part of Everpad is its integration with Ubuntu's Unity. It's no secret that I'm not a fan of Unity, but for those folks using it, Everpad allows the Unity search engine to search in your Evernote notes along with your local Linux files.
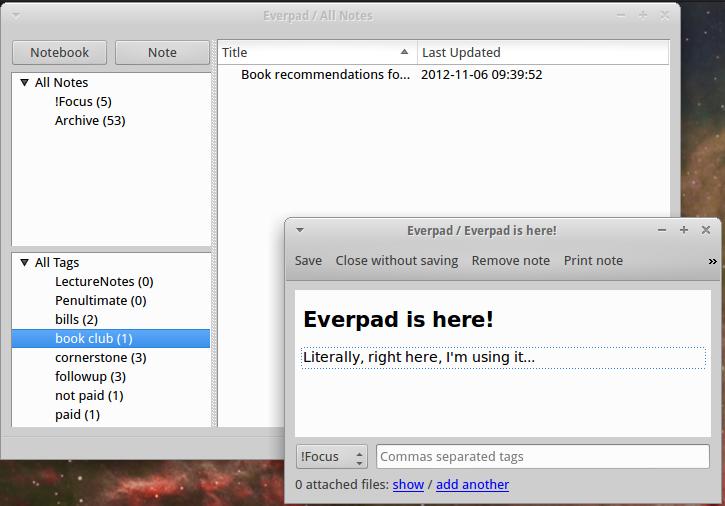
Figure 1. Accessing Your Notes with Everpad
Although Everpad has a fairly spartan-looking interface, its deep integration with Unity makes it quite impressive. Thankfully, Everpad doesn't require Unity to work, and in my Xubuntu environment, it works quite nicely. Due to its power and flexibility, Everpad is this month's Editors' Choice. For instructions on installing it into your Linux environment, check out its wiki at https://github.com/nvbn/everpad/wiki/how-to-install.
We are stuck with technology when what we really want is just stuff that works.
—Douglas Adams, The Salmon of Doubt
Technology is a word that describes something that doesn't work yet.
—Douglas Adams
A CD. How quaint. We have these in museums.
—Eoin Colfer, The Eternity Code
Please, no matter how we advance technologically, please don't abandon the book. There is nothing in our material world more beautiful than the book.
—Patti Smith
Computers are useless. They can only give you answers.
—Pablo Picasso
