
Recently, Aldo Iljazi suggested removing the venerable menuconfig build target, on the grounds that nconfig was an improvement, and there didn't need to be two menu-based configuration systems in the kernel tree.
nconfig is actually based on the menuconfig code, and they both rely on ncurses to present menus. But nconfig tries to look more modern and gives the user a bit more control using the keyboard.
The idea went nowhere—perhaps it was just too soon, because nconfig has a tiny user base relative to that of menuconfig. But, it was surprising to see how much resistance there was. At one point, Alexander Holler raised the objection that nconfig relied on the Fn keys for its operation, which were not available on software keyboards on smartphones, for example. But, even after Randy Dunlap pointed out that the regular number keys worked just as well, there still was overwhelming opposition to ditching menuconfig.
It's interesting that certain parts of the kernel—for example, config targets that don't themselves bloat the compiled binary (though they may help select features that do)—are much easier to get into the kernel source tree than actual kernel features. And once in, they are harder to remove. There was no particular need for nconfig, given that it performs a similar function to menuconfig, but there it is in the kernel source tree. These helper projects come and go fairly easily, probably because there's not much cost to having them, and by including them in the tree, they get the chance to show whether they really actually may be better than the alternatives.
Recently, Jim Lieb tried to simplify the interface that allowed file servers to impersonate their client user for write operations. This is standard procedure, without which files would have the wrong owners, and things like quotas and access controls would not be able to tell whether a user violated a given constraint. But the existing implementation used a combination of various system calls, including setfsuid(), setfsgid(), setgroups() and others to accomplish this. Jim wanted to replace the mess with a single switch_creds() system call.
As it turned out, there was support for the general idea of cleaning up the existing interface, but no agreement on exactly how it should be done. Al Viro, for example, offered his own implementation that avoided some of the complexities of Jim's approach. But both approaches turned out to have significant security gaps, as Eric W. Biederman and Tetsuo Handa pointed out at various times during the conversation.
Everyone seems agreed on the fact that the current implementation is a bit messy and could use a cleaning. But apparently the security issues are devious and need to be gotten right. The current messy implementation also may turn out to be the best way to deal with those issues—in which case, it really couldn't be considered messy in the first place.
Recently, Peter Huewe took over as the primary maintainer of the TPM (Trusted Platform Module) device driver. TPM is a hardware authentication system that allows third-party services to confirm that only a trusted operating system and set of software is running on the device.
Many other maintainers were listed, several of whom had not been responsive for a while and there was general agreement that the list should be pruned and kept accurate.
A number of folks tried to contact the various maintainers to ask if they were still interested in working on the project. Ultimately, several folks, such as Rajiv Andrade and Ashley Lai, said they still were interested in helping out, but they recognized Peter as the project leader. A number of other folks asked to be removed from the maintainers list, as they had moved on to other projects or other companies.
Jason Gunthorpe inaugurated the new maintainer hierarchy by submitting a set of TPM patches that had been waiting for inclusion and remarking, “there are still lots of patches to go before the subsystem meets the current kernel standard.”
My favorite scene in Star Trek IV is when Scotty tries to use the computer in the 1980s. When he's told he must use the mouse, he responds, “how quaint”, and then proceeds to try speaking into the mouse for the computer to respond. With the advent of Siri on iOS and voice recognition on Android, it's beginning to feel like the voice interface portrayed in Star Trek isn't too far away.
But it's not here just yet.
I set up my Nexus 7 tablet with the most recent tools from Google (technically, they're not yet available for the Nexus 7, but I'm a nerd, so I was able to find a way). I set my now always-responsive tablet on the window ledge in my office, just out of reach but in easy earshot. I went through the entire day, trying to use the tablet as often as possible without touching it. I discovered a few things:
Google is really good at giving certain types of feedback. If I asked about the time in London, the current weather or the stock price of a popular stock, I'd get a visual response along with a voice telling me the answer.
Outside that small list of things Google is really good at answering, it doesn't do anything more than give search results on the tablet. I was hoping for something like, “would you like me to read you the most popular search result?” But alas, it didn't even audibly tell me it heard my question.
Sending texts and e-mail messages is possible, but frustrating and scary. If you've ever tried to use voice calling with a Bluetooth headset, you've probably had the awkward experience of your phone accidentally trying to call an ex-boyfriend or girlfriend instead of calling the plumber. If you're lucky, you can stop it before it rings on their end, but thanks to caller ID, you're likely in for a very uncomfortable followup call. I found Google's voice-based messaging more cautious than my Bluetooth headset, but still potentially bad. This is especially true because the tablet was across the room, making it hard to dive and press cancel.
So, although we may not be to the point where we can ask Jarvis to order us a pizza while we're flying around in an Ironman suit, we're definitely taking a step in the right direction. The advent of Google Glass will make verbal commands more and more common. Even if you hate Google Glass, you can rejoice in the voice interface improvements it doubtlessly will cause.
Is voice interface more than a novelty for you? Do you successfully send messages to people on a regular basis by dictating only to your smart device? Did you think Star Trek IV was awesome too? I'd love to get feedback on your thoughts concerning voice interfaces, Google Glass and the future of interfaces in general. Send me an e-mail at info@linuxjournal.com. I, for one, look forward to my first cranial implant. (I'd like to wait for version 1.1 though—nobody wants a buggy brain implant!)
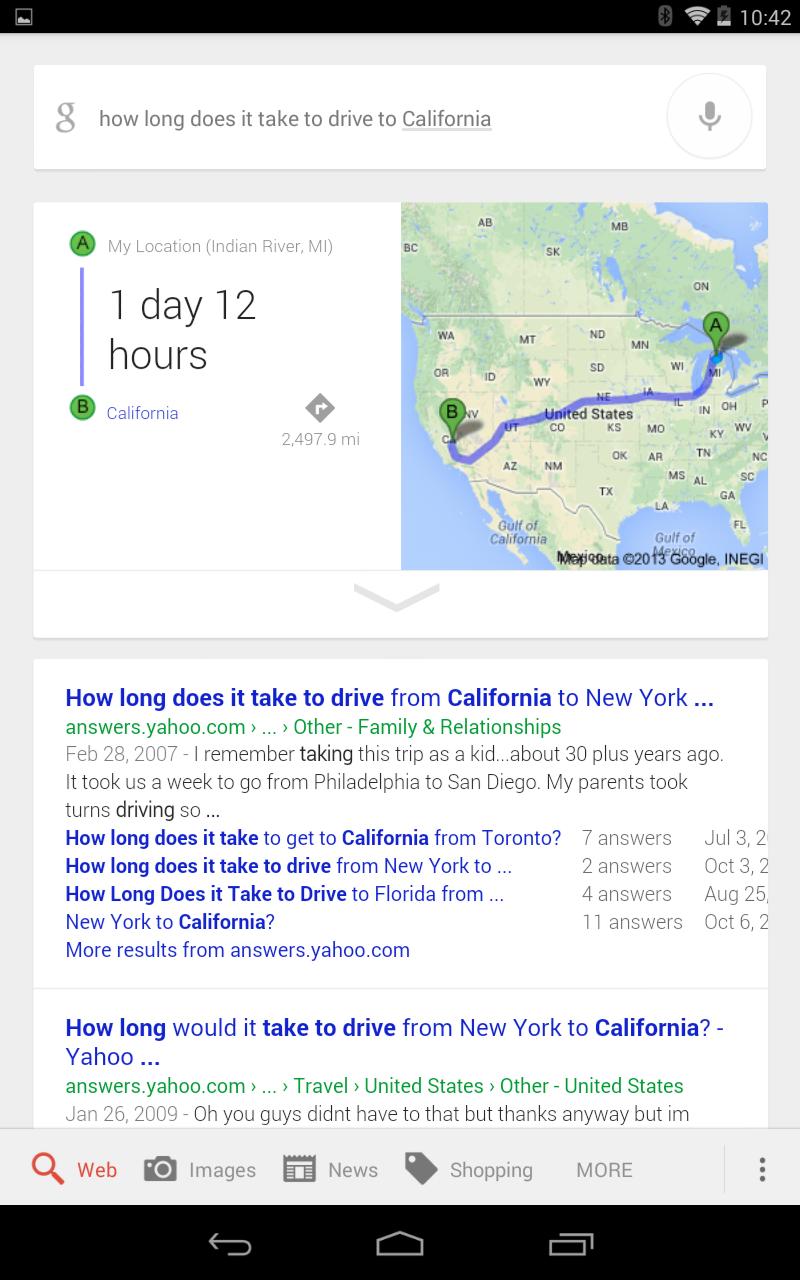
With the recent resurgence of Bitcoin and the subsequent vitality of other cryptocurrencies (Litecoin, for instance), I've been receiving lots of e-mail messages asking how to mine. I've discussed cryptocurrencies in LJ quite a bit during the past few years. Recently, a friend introduced me to Anubis, so I want to mention it briefly here.
Whether you're mining for Bitcoins with ASIC hardware or Litecoins with high-end graphics cards, chances are you're using the cgminer program to do your mining. Although cgminer provides a nice console-based screen for monitoring your miner, there's no easy way to see how all your miners are doing at once. Enter: Anubis.
Anubis is a Web-based program that interacts over the network to all your miners. It then combines the data it collected into a simple monitoring screen so you can check temperature, errors, efficiencies and even change configurations on the fly. If you're running more than one instance of cgminer in your mining farm, you likely will benefit from Anubis. Check it out at https://github.com/pshep/ANUBIS.
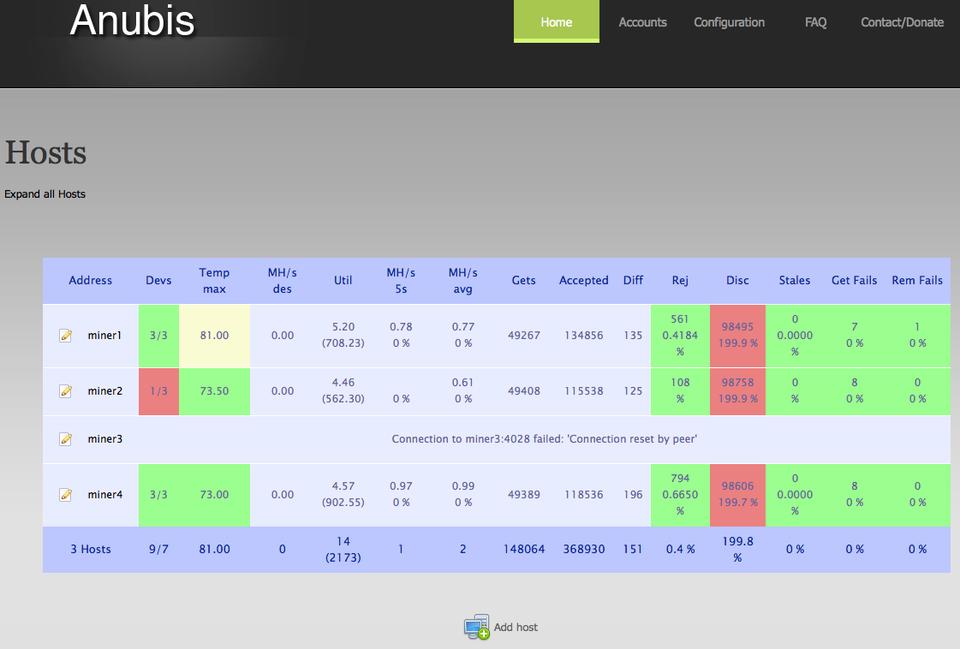
Figure 1. Anubis gives a nice overview of all the problems with my mining farm.
In past articles, I have looked at distributions that were built with some scientific discipline in mind. In this article, I take a look at yet another one. In this case, I cover what is provided by NeuroDebian (neuro.debian.net).
I probably should start by clarifying that NeuroDebian is not strictly a Linux distribution in the classical sense. The people behind NeuroDebian began by working on PyMVPA (www.pymvpa.org), a Python package to do multivariate pattern analysis of neural data. To make this package easy to deploy, NeuroDebian was created. Over time, more and more packages were added to NeuroDebian to try to create the ultimate integrated environment for neuroscience. All of this work is described in a scientific paper, “Open is not enough. Let's take the next step: an integrated, community-driven computing platform for neuroscience” (www.frontiersin.org/Neuroinformatics/10.3389/fninf.2012.00022/full). This paper is available at the “frontiers in NEUROINFORMATICS” Web site.
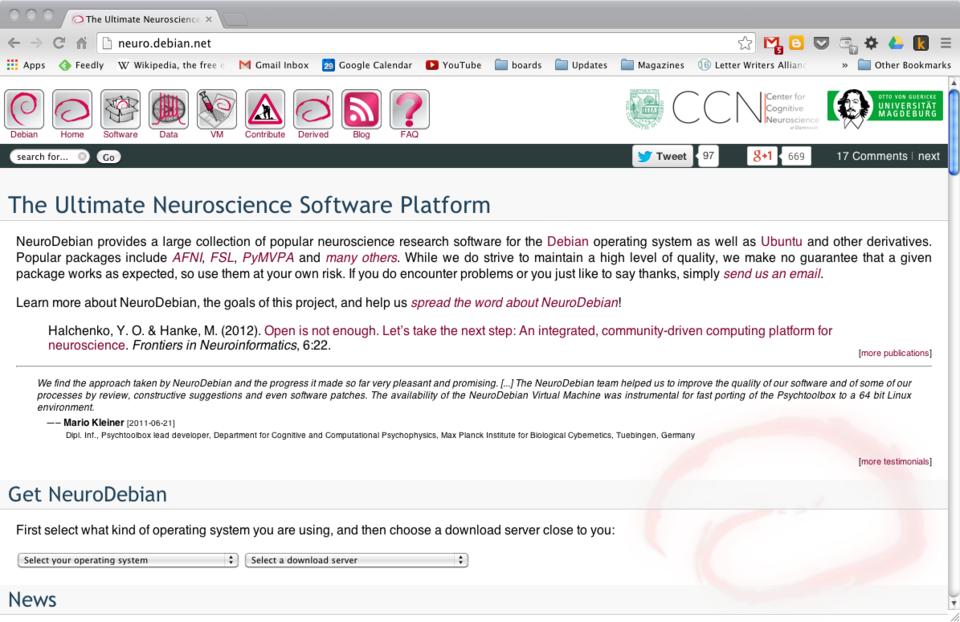
Figure 1. The Main Page for NeuroDebian
Installing NeuroDebian is a bit different from other distributions. On the main home page, there is a section called Get NeuroDebian. Here you can select which distribution you use as your desktop and the mirror from which you want to download.
You then get a couple commands that you need to run on your system. The first one is a wget command meant to download an entry for APT and store it in a source file in the directory /etc/apt/sources.list.d/. The second command uses apt-key to go out to the MIT PGP key server to download and install the key used to verify the NeuroDebian packages. Once these two commands have been run, you then can do:
sudo apt-get update
to download the package definitions for everything provided by NeuroDebian.
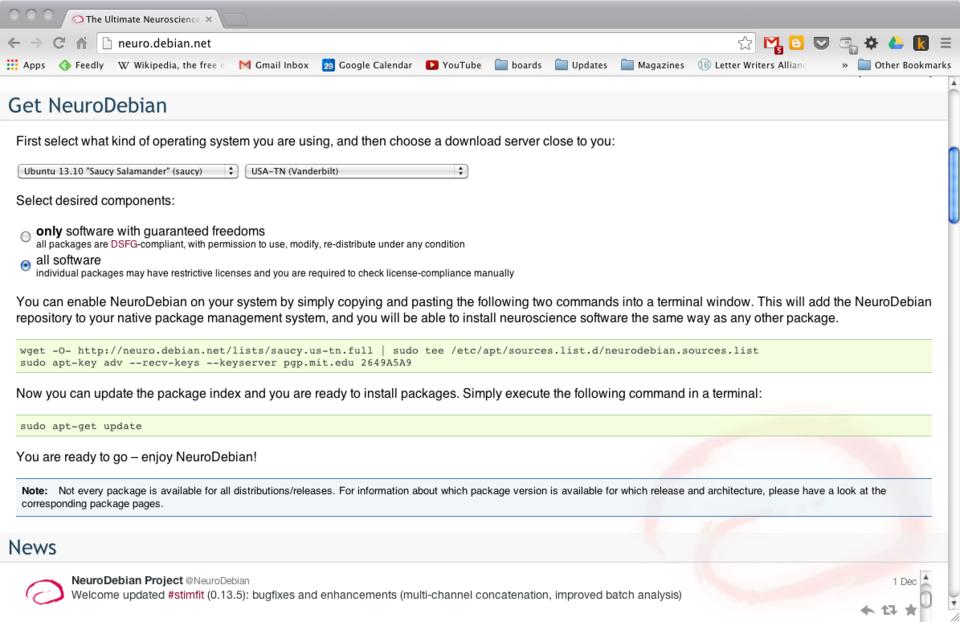
Figure 2. You can get NeuroDebian further down on the main page.
This works well if you already are running some version of Debian, or a derivative like Ubuntu, as your desktop operating system. But, what can you do if you are running Windows or Mac OS X? The NeuroDebian project provides a virtual machine option for those situations. If you select either Windows or Mac OS X as the operating system in the download section, you will be provided with a link to download an OVA file. This type of file is a standard file format for virtual machines. For example, you can import this file into Virtual Box (Figure 3). This virtual machine uses Debian 7, or Wheezy, as the core operating system. The main Web site says that GNOME is used as the desktop environment.
Figure 3. The OVA file can be imported in Virtual Box to get a complete environment.
However, when I actually installed the latest version of the virtual machine, the desktop environment that is used is XFCE. You even could use this on your Linux desktop in a virtual machine. This way, you always have a stable, complete computing environment for neuroscience that you know will not change or be broken.
When you first start up this virtual machine, you will be presented with some configuration steps. The first step is to do an update of the installed packages. After this, you will be asked whether you want to take part in an application survey. If you are using NeuroDebian regularly, you may want to take part in order to provide feedback to the team. Several tools require environment variables to be set. The next step asks you whether you want these to be set automatically in the default profile settings. The next step allows you to select several extra packages like Emacs, a PyMVPA tutorial and R. Be prepared for a bit of a wait, as there are several packages to be downloaded. In my case, I ended up with a download of 625MB of extra packages.
After all of the configuration steps are completed, you can click on the Applications Menu button in the top right-hand corner and go down to the NeuroDebian menu entry. Here you will find all of the particular applications specifically selected for neuroscience. They are broken down into categories for electrophysiology, medical imaging, psychophysics and a section of support links to access the relevant mailing lists. There is also an entry to re-run the setup wizard for the virtual machine.
Now that you have NeuroDebian installed and set up, let's take a quick look at some of the provided tools. The core reason for the creation of NeuroDebian was to deploy PyMVPA, so let's start there. PyMVPA provides a set of tools to do multivariate pattern analysis on large data sets. This is very useful in neuroimaging. Several processing steps are usually involved in this type of work flow, such as data preparation, classification, feature selection and generalization testing. PyMVPA provides high-level abstraction of these processes.
A tutorial is available at the PyMVPA project Web site that walks you through the core concepts and processes involved in using it. A full description of what you can do would require a whole article on its own.
PyMVPA isn't the only software included, however. Going to the package list at the NeuroDebian home page gives a full listing, broken down into the following categories: distributed computing, electrophysiology, magnetic resonance imaging, modeling of neural systems, neuroscience datasets and psychophysics.
An interesting piece of software is under the educational category: virtual-mri-nonfree. This package provides a virtual MRI scanner to simulate running an MRI. This way, you can learn about how scanner parameters affect your images—a very cool tool.
Software is not the only thing provided by the NeuroDebian distribution. There is also a rather large set of data packages available, all in one location. These include items like brain atlases, fMRI data from face and object processing in the ventral temporal cortex, and an MRI-based brain atlas of the anatomy of a normal human brain.
There are tutorials for PyMVPA and MRI analysis that require sample data sets. These also are available from NeuroDebian. Additionally, there is a blog on the NeuroDebian Web site where you can find articles on specific tools and help with particular techniques.
If you do work in computational neuroscience, you could do worse than starting with NeuroDebian. This distribution gives you a full set of tools to get you started. There even are further derivatives of NeuroDebian, built to support classwork or to have a specific subset of the tools available for well-defined work flows. Maybe other research communities might be tempted to do a similar project? If you have the ability, you should consider offering some of your skills back to the project in order to help it grow. Of course, this is true of all-open source projects.
Although its timetable may not always be ideal, Valve has come through for Linux users lately. Not only has it released a native Linux version of Steam (with many native games!), it also has expanded its Linux support as the basis for its standalone SteamBox. The first step toward a Steam-powered console is the operating system. Thankfully for nerds like me, Valve released its operating system (SteamOS) to the public.
SteamOS is in beta testing right now, and unfortunately at the time of this writing, it supports only NVIDIA graphics cards. That limits who can test the OS, but releasing the operating system at all is extremely exciting! Geeks have been creating their own XBMC boxes for years, and now we'll be able to create our own gaming consoles too.

(Image from www.steampowered.com)
If you haven't tried SteamOS yet, and if you have an NVIDIA graphics card, I urge you to go try it out (store.steampowered.com/steamos/buildyourown). Will the SteamBox finally bridge the gap between PC gaming and console gaming? Will its open-source roots help SteamOS become the dominant living room device? It's been a number of years, but Valve definitely has invested into the Linux community. Now if you'll excuse me, I need to go shoot some zombies.
However beautiful the strategy, you should occasionally look at the results.
—Winston Churchill
Don't bother just to be better than your contemporaries or predecessors. Try to be better than yourself.
—William Faulkner
If women are expected to do the same work as men, we must teach them the same things.
—Plato
Never read a book through merely because you have begun it.
—John Witherspoon
Avoid the crowd. Do your own thinking independently. Be the chess player, not the chess piece.
—Ralph Charell
I'm not really much of a computer gamer. That said, I'm both ashamed and oddly proud of the hours (probably thousands!) I spent playing Dune 2000 back when it was cutting-edge gaming technology. There's just something about real-time strategy games that appeals to those of us lacking the reflexes for the more action-packed first-person shooters. If you also enjoy games like Dune 2000, Starcraft, Warcraft, Civilization or other RTS classics, Warzone 2100 will be right up your alley.
Warzone 2100 reminds me very much of my beloved Dune 2000. The landscapes, the missions and even the look of the game pieces resemble that old RTS game I spent so much time playing. Warzone 2100 is far better than Dune 2000 ever was, however, thanks to its amazing set of features:
Cross-platform, supporting Windows, Mac and Linux.
Single-player missions.
Multiplayer gameplay.
Network and Internet hosting/playing.
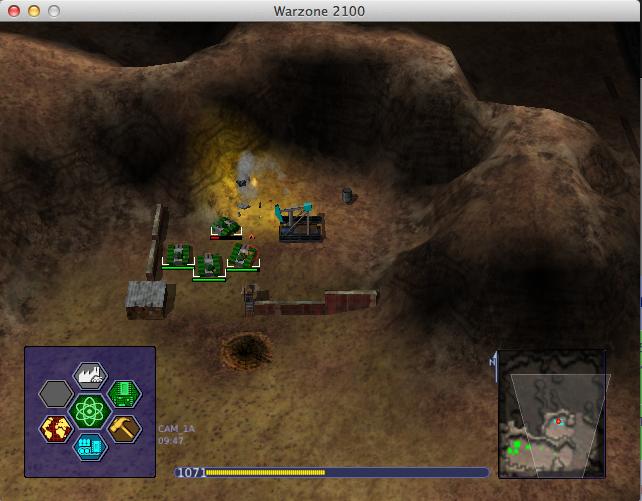
Warzone 2100 truly excels at being a fun, easy-to-learn game. The coolest part, at least in my opinion, is its history. Warzone 2100 started as a commercial game. Much like the Quake engine was open-sourced, Warzone 2100 was released to the public as an open-source project back in 2004. Then, in 2008, the rights of that license were clarified, and the in-game videos and soundtrack also were released. Now the game is under active development, and it has a healthy community releasing maps and mods.
The game is available for direct download either at SourceForge or its Web site: www.wz2100.net. It's also available using Desura, the Linux-native game manager (similar to Steam) that we've covered before in Linux Journal. Due to its fun and relevant gameplay, cross-platform availability and awesome history, Warzone 2100 is this month's Editors' Choice.
