
Recently, someone suggested rewriting Linux in Perl as a way to improve the design and make it more organized and uniform. In particular, the person said that Linux relied on the big kernel lock (BKL) longer than other free OSes like FreeBSD.
It's fun to speculate on who might have posted that. Clearly, he or she knows enough about Linux development to know what the big lock was, and that other OSes had it for less time, but the person is so full of bile against Linux that he or she would snipe that an interpreted language would be faster. Let's see...what big software company employs people to work on Linux because it hates Linux?
Anyway, Theodore Ts'o had an interesting, and actually relevant, response. He said, “Linux had the BKL longer because it has had SMP longer than its competitors. Linux got rid of the last of the BKL in mid-2012. As of 2013, FreeBSD, NetBSD and OpenBSD still have the giant lock (BSD's equivalent of the BKL) in some of their subsystems.” And he added, “Linux has had much better scalability than the *BSD's for much of the past couple years, with SGI using Linux on systems with hundreds of processors, and with people using Linux on 32 and 64 processors systems for the past decade. In contrast, FreeBSD was boasting in 2013 of improving its 16 processor scalability.”
He also remarked that his favorite was when someone “suggested porting BSD 4.3 to Emacs LISP, so that you could run your entire system under GNU Emacs.”
It's fun to think about all the different trolls that have appeared through the years. But actually, there are some pretty valid reasons for proprietary OS companies to be bitter. Linux may not dominate the desktop, but it still powers millions upon millions of servers that help make the Internet what it is. And, those servers represent massive amounts of lost revenue for proprietary OS companies.
Victor Porton wanted to improve the security of the SELinux sandbox, and started a discussion on how to do that. The problem was that hostile code could break out of the sandbox too easily, primarily by spawning child processes. He wanted the sandbox to keep better track of child processes by adding an ID to each process. In his vision, the ID could not be abandoned and would allow the sandbox to reap all child processes after the parent terminated.
There was a lively discussion. Someone suggested that cgroups (Linux Control Groups) could use their resource-limiting features to constrain processes within the sandbox. But Andy Lutomirski objected, saying that cgroups was already a horrible failure, and was getting worse, not better.
Andy suggested using the spanking-new subreaper to accomplish his goal. The subreaper, introduced in Linux 3.4, tracked process ancestry and delivered child-process exit status to the nearest living ancestor of that process, even if the child process' immediate parent already had terminated.
According to Andy, the subreaper could implement a new command to kill all descendants of a given process. This would ensure that no process could slide undetected out of the sandbox's grasp.
Joshua Brindle also suggested using a seccomp filter for sandboxed processes. Seccomp filters could restrict the system calls a given process could use. Joshua suggested that processes in the sandbox be restricted from using any system calls that might allow them to escape. Unfortunately, this wouldn't work for Victor's particular use case, which required the sandbox to span a network successfully.
Ultimately, Victor found no more appealing solution than the cgroups idea, and he offered a thorough description of how he wanted to proceed in that direction. The discussion ended there, but probably at least one of the various approaches to the SELinux sandbox will result in improved security.
There's been some question regarding the status of the 2.6.34 stable tree. Apparently, Aaro Koskinen noticed that it hadn't been updated in a while, and H. Peter Anvin confirmed that it had been more than a year since the last update—during which time the 2.6.32 stable series had seen a new release. Peter said, “I'm worrying if people think that security patches are still being backported if in fact they aren't.”
Paul Gortmaker, the 2.6.34.x tree maintainer, replied that there was another release in the works that would come out within a couple weeks, “with a focus on just clear CVE like fixes and hence a relatively smaller queue size (i.e., nothing like 200 patches etc.)”. But he added that the tree would shortly reach its end of life and would not receive any more updates beyond that point.
I never have a Twitter app crash in the middle of a Tweet. That wouldn't be too terrible to deal with. No, for me, it seems my e-mail application decides to crash after I've spent 20 minutes thumbing out a reply while sitting in a crowded airport. If you've ever lost a love letter, term paper, shopping list or world-class Facebook post, Type Machine is the perfect app for you.
It costs $1.99 in the Google Play Store, and automatically keeps track of the last text typed in every native Android application. It has some great features that satisfy even the most privacy-concerned individuals:
No unnecessary permissions.
Supports a PIN number to lock typing history.
Apps can be blacklisted so no input is recorded.
History is pruned automatically.
Password fields are never recorded.
The best part about Type Machine is that it works automatically in the background, and you never need to think about it—until you do.

(Screenshot from the Google Play Store)
I'll admit, the thought of installing a keystroke logger on my own device was a little creepy at first. I've never read the “this app requires these permissions” screen more carefully than when installing Type Machine. That said, I've had it only a couple days, and I've already used it to retrieve a Twitter update that got lost amid a program crash. If you have a particularly crash-prone phone, or if you just prefer not to risk the possibility of a lost e-mail, check out Type Machine in the Google Play store: https://play.google.com/store/apps/details?id=fi.rojekti.typemachine.
The de facto standard for port scanning always has been the venerable Nmap program. The command-line tool is indeed very powerful, but I've only ever seen it work with Linux, and every time I use it, I need to read the man page to figure out the command flags.
Windows users have been able to use the “Angry IP Scanner” tool for quite some time, and recently, the program (since version 3) has become truly cross-platform. If you need to scan for open ports on a specific host or on an entire network, the Angry IP Scanner (or just ipscan) tool is fast, robust and, of course, open source.

Grab a copy of this awesome little FOSS tool from its Web site at www.angryip.org or directly from SourceForge at ipscan.sf.net. Just remember, port scanning is one of those skills that can be used for good or evil—be sure you're wearing your white hat!
For the past few months, I've been covering different software packages for scientific computations. For my next several articles, I'm going to be focusing on using Python to come up with your own algorithms for your scientific problems. Python seems to be completely taking over the scientific communities for developing new code, so it is a good idea to have a solid working knowledge of the fundamentals so you can build solutions to your own problems.
In this article, I start with NumPY (www.numpy.org). My next article will cover SciPy, and then I'll look at some of the more complicated modules available in the following article.
So, let's start with the root module from which almost all other scientific modules are built, NumPY. Out of the box, Python supports real numbers and integers. You also can create complicated data structures with lists, sets and so on. This makes it very easy to write algorithms to solve scientific problems. But, just diving in naively, without paying attention to what is happening under the hood, will lead to inefficient code. This is true with all programming languages, not just Python. Most scientific code needs to squeeze every last available cycle out of the hardware. One of the things to remember about Python is that it is a dynamic language where almost all functions and operators are polymorphic. This means that Python doesn't really know what needs to be done, at a hardware level, until it hits that operation. Unfortunately, this rules out any optimizations that can be made by rearranging operations to take advantage of how they are stored in memory and cache.
One property of Python that causes a much larger problem is polymorphism. In this case, Python needs to check the operands of any operator or function to see what type it is, decide whether this particular operand or function can handle these data types, then use the correct form of the operand or function to do the actual operation. In most cases, this is not really an issue because modern computers have become so fast. But in many scientific algorithms, you end up applying the same operations to thousands, or millions, of data points. A simple example is just taking the square of the first 100,000 numbers:
import time a = range(100000) c = [] starttime = time.clock() for b in a: c.append(b*b) endtime = time.clock() print "Total time for loop: ", (endtime - starttime)
This little program uses the range function to create a list of the first 100,000 integers. You need to import the time module to get access to the system clock to do timing measurements. Running this on my desktop takes approximately 0.037775 seconds (remember always to make several measurements, and take the average). It takes this much time because for every iteration of the loop, Python needs to check the type of the b variable before trying to use the multiplication operator. What can you do if you have even more complicated algorithms?
This is where NumPY comes in. The key element that NumPY introduces is an N-dimensional array object. The great flexibility of Python lists, allowing all sorts of different types of elements, comes at a computational cost. NumPY arrays deal with this cost by introducing restrictions. Arrays can be multidimensional, and they must all be the same data type. Once this is done, you can start to take some shortcuts by taking advantage of the fact that you already know what the type of the elements is. It adds extra overloading functions for the common operators and functions to help optimize uses of arrays.
All of the normal arithmetic operators work on NumPY arrays in an element-wise fashion. So, to get the squares of the elements in an array, it would be as simple as array1 * array1.
NumPY also uses external standard, optimized libraries written in C or FORTRAN to handle many of the actual manipulations on these array data types. This is handled by libraries like BLAS or lapack. Python simply does an initial check of each of the arrays in question, then hands them as a single object to the external library. The external library does all of the hard work, then hands back a single object containing the result. This removes the need for Python to check each element when using the loop notation above. Using NumPY, the earlier example becomes:
import numpy import time a = numpy.arange(1000000) starttime = time.clock() c = a * a endtime = time.clock() print "Total time used: ", (endtime - starttime)
Running this toy code results in an average run time of 0.011167 seconds for this squaring operation. So the time is cut by one third, and the readability of the code is simplified by getting rid of the loop construct.
I've dealt only with one-dimensional arrays so far, but NumPY supports multidimensional arrays just as easily. If you want to define a two-dimensional array, or a matrix, you can set up a small one with something like this:
a = numpy.array([[1,2,3,4], [2,3,4,5]])
Basically, you are creating a list of lists, where each of the sub-lists is each of the rows of your matrix. This will work only if each of the sub-lists is the same size—that is, each of the rows has the same number of columns. You can get the total number of elements in this matrix, with the property a.size. The dimensions of the matrix are stored in the property a.shape. In this case, the size is 8, and the shape is (2, 4), or two rows and four columns. What shape did the array in the earlier example have? If you go ahead and check, you should see that the shape is (1000000). The other key properties of these arrays are:
ndim: the number of dimensions.
dtype: the data type of the elements.
itemsize: the size in bytes of each element.
data: the buffer that stores the actual data.
You also can reshape arrays. So if you wanted to take the earlier example of the first 100,000 integers and turn it into a three-dimensional array, you could do something like this:
old_array = numpy.arange(100000) new_array = old_array.reshape(10,100,100)
This will give you a new 3-D array laid out into a 10x100x100 element cube.
Now, let's look at some of the other functions available to apply to arrays. If you remember from earlier, all of the standard arithmetic operations are overloaded to operate on arrays one element at a time. But, most matrix programming languages use the multiplication element to mean matrix multiplication. This is something to keep in mind when you start using Python. To get a true matrix multiplication, you need to use the dot() function. If you have two matrices, A and B, you can multiply them with numpy.dot(A, B).
Many of the standard mathematical functions, like cosine, sine, square root and so on, are provided by NumPY and are called universal functions. Just like with the arithmetic operators, these universal functions are applied element-wise across the array. In science, several common functions are used. You can get the transpose of a matrix with the object function a.transpose(). If you need to get the inverse of a matrix, there is the module function inv(), so you would execute numpy.inv(a). The trace is also a module function, given by numpy.trace(a).
Even more complicated functions are available. You can solve systems of equations with NumPY. If you have a matrix of coefficients given by a, and a vector of numbers representing the right-hand side of your equations given by y, you can solve this system with numpy.solve(a,y). In many situations, you may be interested in finding the eigenvalues and eigenfunctions of a given system. If so, you can use numpy.eig(array1) to get those values.
The last thing I want to look at here is a class that provides even more shortcuts, at the cost of more restrictions. Matrices (2-D arrays) are so prevalent that NumPY provides a special class to optimize operations using them as much as possible. To create a new matrix, say a 2x2 matrix, you would write:
A = numpy.matrix('1.0, 2.0; 3.0, 4.0')
Now, you can get the transpose with just A.T. Similarly, the inverse is found with A.I. The multiplication operation will do actual matrix multiplication when you use matrix objects. So, given two matrix objects A and B, you can do matrix multiplication with A*B. The solve function still works as expected on systems of equations that are defined using matrix objects. Lots of tips and tricks available on the NumPY Web site, which is well worth a look, especially as you start out.
This short introduction should get you started in thinking of Python as a viable possibility in “real” numerical computations. The NumPY module provides a very strong foundation to build up complex scientific workflows. Next month, I'll look at one of the available modules, SciPY. Until then, play with all of the raw number-crunching possibilities provided by NumPY.
Several decent video editors are available on the Linux platform. Kdenlive, OpenShot, Cinelerra and Pitivi are those that come to mind as “big players” in an admittedly small market. I've used them all through the years, with varying levels of success. A frustration of mine is that invariably, I end up using a proprietary video editing suite like iMovie or Final Cut Pro when I have to do a larger project. As an open-source enthusiast, that doesn't settle well with me.
Although I'm honestly not sure Pitivi is the best choice for Linux-based video editing, I truly can say that its current fundraising push is impressive. The “kickstarter” concept is old hat by now, but that doesn't mean a well-planned campaign isn't still a great idea. The Pitivi team is trying to raise enough money to put serious coding time into the program and get to the 1.0 release. That's only the first step of the journey, however, because after the solid 1.0 foundation is complete, future features will be added according to contribution and user-base voting.
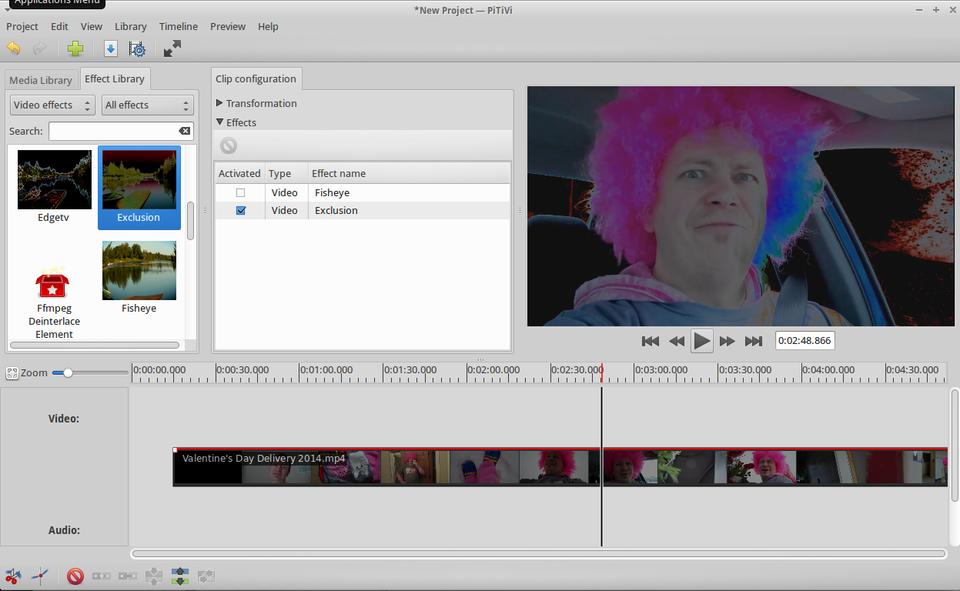
I'm confident to say that Pitivi is currently a great choice for video editing on Linux. If the fundraising campaign works out well, it soon may be the clear leader in stability and functionality. Thanks to the combination of an incredible product plus a game plan to get even better, Pitivi is this month's Editors' Choice. If you want to be a part of Pitivi's future, check out the fundraiser page at fundraiser.pitivi.org. If you want to test the program itself, you can download it today for your favorite distribution at www.pitivi.org.
Most people with Internet access in their houses have visited a speed-test Web site to make sure they're getting somewhere close to the speed they're overpaying for. I'm paying more than $100 a month for my business-class connection from Charter, so on a regular basis, I make sure I'm getting the advertised speed. (I seldom get the advertised speed, but the margin of error is acceptable. I guess.)
One of the frustrations with Internet speed tests is that most of them require Adobe Flash to work. Even those sites that don't require Flash do require a rather robust (and frivolous) GUI that I find annoying at best. If you're anything like me, you'd like a simple command-line tool that gives you your speed. If you're truly like me, that last sentence just sparked notions of automated scripts e-mailing results via timed cron jobs at different times during the day. Welcome to the club; we're all nerds here.

Thankfully, my friend Charlie K. (I won't use his last name, because I didn't ask him if I could) posted a link on Google Plus to the speedtest-cli program. The project is on GitHub at https://github.com/sivel/speedtest-cli, and to get the Python-based program, simply do this:
# wget -O speedtest-cli \ https://raw.github.com/sivel/speedtest-cli/master/speedtest_cli.py # chmod +x speedtest-cli
Then execute the script ./speedtest-cli to get your results. There are advanced options as well, but a simple execution of the script will provide your speed results. You can see the results of my supposed 80/5 business connection in the screenshot.
There's more to life than books, you know. But not much more.
—Morrissey
Don't cry because it's over, smile because it happened.
—Dr. Seuss
Be yourself; everyone else is already taken.
—Oscar Wilde
Two things are infinite: the universe and human stupidity; and I'm not sure about the universe.
—Albert Einstein
Most people work just hard enough not to get fired and get paid just enough money not to quit.
—George Carlin
