
Recently, some kernel developers tried to clarify the caveats involved in configuring the DEBUG_INFO option in the Linux kernel. Originally, Borislav Petkov patched the KConfig description of that feature to say that it would cause “huge bloat”. But, David Rientjes didn't feel this quite captured the issue. And as Linus Torvalds said, some object files would be four times larger with this option enabled. The fs/built-in.o file, for example, went from 2.8MB to 11.8MB. So although this didn't affect the size of the runnable vmlinux binary file, it did affect the object files, which could cause problems on small systems running tests. Linus said, “I suspect a lot of people are in denial about just how horrible the overhead of debug builds are.”
This issue tended to come up when testing the allmodconfig build target, because it would enable DEBUG_INFO along with everything else. The main reason for compiling the allmodconfig build target is just to ensure that the kernel actually will compile, as opposed to running the resulting binary. Andrew Morton remarked that he always disabled DEBUG_INFO by hand when testing allmodconfig for precisely this reason. Because he didn't plan to run the vmlinux binary, there was no need to build in all the debugging data. He suggested clarifying Borislav's wording to say that the option would bloat object files on disk and increase build time.
But this didn't fully solve the problem, because the allmodconfig build target still enabled DEBUG_INFO by default. And, there would be value in letting developers and interested users test the build process in as easy a way as possible, without inflicting bloated slowness on them.
Several folks, including Ingo Molnar, tried to design a new KConfig option that still would work for testing, but that would avoid the bloat. Eventually, Linus decided to change the DEBUG_INFO option so that it would disable the COMPILE_TEST option.
That almost failed to be good enough, because Andi Kleen pointed out that he actually did run the vmlinux binary in some circumstances, and so the massive debugging data wasn't merely bloat to him, it was a real part of his test. But since his was a very unusual case, Linus told him just to edit the config files by hand if he wanted to re-insert the debugging data.
Recently, Andy Lutomirski announced virtme, a set of scripts that did the hard work of setting up virtual machines for testing compiled Linux kernel binaries with virtFS in KVM. He'd gotten fed up with having to do the whole mistake-prone process by hand, so he wrote virtme to automate it.
The idea was that virtme wouldn't simply boot the kernel into a virtual machine, it also would set up a user environment that was ready to perform tests, download additional software and so on. Andy believed that in time, virtme could automate an entire testing regimen and report the results, with the user giving just a single command to start the ball rolling.
Some filesystems have stirred up darker regions of the VFS (virtual filesystem), necessitating odd changes. It all started when Ilya Dryomov noticed that some recent ACL (access control list) patches seemed inconsistent. Specifically, the Ceph distributed filesystem didn't work well with the new code. He posted a patch to fix this.
Linus Torvalds, however, in looking over the consistency issues, discovered that some of the ACL code relied on passing inodes around. This was a problem, because distributed filesystems didn't necessarily make the same assumptions about things like inodes that single-disk filesystems could, such as assuming an inode wouldn't change suddenly or assuming each inode was unique.
A better approach, he felt, was to pass actual file paths, which didn't suffer from those issues. The problem, as Christoph Hellwig pointed out, was that some of the VFS code was so deep and dark, it became difficult to construct the data the ACLs would need to pass around.
Linus took a look and confirmed the difficulty. He felt that it might not even be worth fixing, if the problem affected only an unusual Ceph filesystem case. He suggested that the Ceph developers might want to “bite the bullet” and fix the problem on their end.
But, this wasn't good enough. As Christoph pointed out, the Plan9 filesystem had the same issue, as did CIFS. None of these filesystems would be able to use the new ACL helper functions without an in-kernel fix for this problem.
So Linus went back into the kernel depths and tried to push the needed file path data as far as he could through the call chain. Ultimately, he did find a way to push the data just far enough to reach where it needed to go. But getting it any further in, he said, would be much harder. Fortunately, that wouldn't be necessary.
Al Viro felt this was a bit over the top and didn't see the need to pass file path information when inode data would work just as well. But, Linus explained that:
Some network filesystems pass the path to the server. Any operation that needs to check something on the server needs the dentry, not the inode.
This whole “the inode describes the file” mentality comes from old broken UNIX semantics. It's fundamentally true for local UNIX filesystems, but that's it. It's not true in general.
Sure, many network filesystems then emulate the local UNIX filesystem behavior, so in practice, you get the UNIX semantics quite often. But it really is wrong.
Part of Al's objection was based on the idea that networked filesystems like CIFS couldn't support hard links. But lo and behold, it turned out they really could. This made no sense to Al until he realized this could be accomplished with Samba on a UNIX server. But he detested it, along with Linus' entire patch, even while acknowledging that it probably was necessary. He blamed Andrew Tridgell for supporting hard links in the first place, but at that point Jeremy Allison said, “Actually you have to blame me for that. Tridge always hated the UNIX extensions.”
I have a love/hate relationship with Waze. The idea of peer collaboration regarding traffic, combined with the technology to accomplish it on an enormous scale is truly amazing. Yet, every time I've used Waze myself, it's been an exercise in frustration. It has insisted I turn left off a bridge, and then it refused to reroute me when I didn't. On one trip, it had me get off every freeway exit, only to get back on the freeway immediately with the adjacent onramp. That doesn't seem to be the case for everyone, and perhaps it's simply because I live in a fairly rural area, and there aren't many users apart from me in the area.
Waze is a turn-by-turn GPS application. For most people, it works well and gives quick and easy directions to get from point A to point B. It also has a very robust social aspect, which is really what sets it apart. Did you just pass a police officer setting up a speed trap? Click on the Waze app, and it will warn fellow Waze users as they approach. Is there an accident? Tell Waze about it, and it will warn other users and route them around the slowdown.

There is a certain competitive aspect to Waze as well. Who has mapped the most new roads? How many miles have you driven with Waze? From a mapping aspect, the truly amazing part of the entire system is that Waze watches the routes you take and uses that information to guide others. For that reason, Waze prefers you have the app running whenever you're on the road, whether or not you need it for guidance. Your driving adds to the routing algorithms, ideally making things easier for other drivers in the future.
Waze is available at the Google Play store: https://play.google.com/store/apps/details?id=com.waze. Check it out for yourself and see if the navigator in your phone is awesome, or if it wants to murder you, like mine does for me.
I love SSH. I mean, I really, really love SSH. It's by far the most versatile, useful, amazingly powerful tool in my system administration quiver. One of the problems with SSH, however, is that when it dies, it doesn't automatically recover. Don't get me wrong. It's easy to recover with SSH, especially if you've set up public/private keypairs for authentication (I show you how to do that over here: https://www.youtube.com/watch?v=R65HTJeObkI). But if the SSH connection dies, it's difficult to reestablish.
In the past, I've done something like enclosing the SSH command in an endless WHILE loop so that if it disconnects, it simply starts over. (I talk about WHILE loops in this month's Open-Source Classroom.) With AutoSSH, however, even if an SSH session is still active, but not actually connected, it will disconnect the zombie session and reconnect a fresh one, without any interaction.
Image Credit: AllenMcC, Wikipedia User
I personally use AutoSSH to keep reverse tunnels active inside a remote data center that is behind a double NAT. Getting into the data center remotely is very difficult, but if I can establish a tunnel from inside the double-NAT'd private network to my local server, getting in and out is a breeze. If that SSH tunnel dies, however, I'm locked out. In my particular case, the data center is an entire continent away, so driving over isn't an option. With AutoSSH, if something goes wrong, it will keep attempting to reestablish a connection until it succeeds. The program has saved my bacon more than once, and because it's so incredibly useful, AutoSSH takes this month's Editors' Choice award. It's most likely already in your distribution's repositories, but you can check out the Web site at www.harding.motd.ca/autossh.
Git has become the most popular version-tracking platform around for open-source projects. Whether you're using GitHub, Gitorious, Bitbucket or similar, or even if you're hosting the git repository yourself, accessing the code is something us Linux users take for granted. For Windows users, what seems commonplace to us (typing git clone on the command line, for instance) is completely foreign to the regular point-and-click world they're used to.
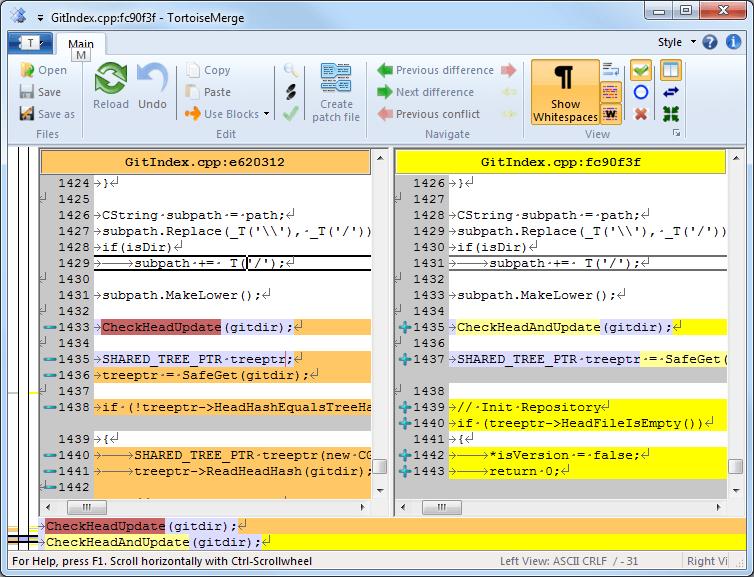
Enter TortoiseGit. With a familiar GUI interface to the underlying git system, TortoiseGit can make Windows-based open-source developers feel right at home. It's open source itself, and it's part of the Tortoise family, which includes TortoiseSVN for Subversion repositories and TortoiseCVS for the Concurrent Versioning System. To check out the whole family of Windows-based Tortoise clients, see the Wikipedia page at en.wikipedia.org/wiki/TortoiseGit.
In my last article, I looked at NumPY and some of its uses in numerical simulations. Although NumPY does provide some really robust building blocks, it is a bit lacking in more sophisticated tools. SciPY is one of the many Python modules that build on NumPY's. In fact, SciPY has become sort of the de facto science package in Python programming. If you have a scientific problem you are trying to solve, you could do worse than starting with SciPY. Not only are there more advanced functions and objects available to do linear algebra, but there also are functions and objects to handle calculus, interpolation, signal processing and Fast Fourier Transforms, among others. So many functions are available, they actually are grouped together into sub-packages. In this article, I take a quick look at what sorts of functions are available and how to use them to get some serious work done.
To start, you need to import the main scipy module. You would do this with the usual:
import scipy
This imports the common set of functions and objects used in SciPY. It also imports the most-used parts of NumPY, because they are so fundamental to the work for which SciPY is used. If you need anything else from NumPY, you need to import the NumPY module explicitly. In many cases, that is something you will want to do anyway. All of the extra functions in the individual sub-packages need to be imported explicitly. So, if you want to do some signal processing, you would need to use this:
from scipy import signal
The simplest package in SciPY probably is the constants sub-package. This package provides a basic set of physical constants that are most used, like pi or Avogadro's number. It also includes a much larger set of constants from the 2010 CODATA database. These physical constants are stored as a tuple of value, unit and uncertainty, and they include items as diverse as the alpha particle mass to the Wien wavelength displacement law constant. The scipy.misc sub-package contains all of those bits and pieces that don't really fit anywhere else. Here, you can find functions like factorial (to calculate the factorial of a number) and imread (to read an image file into Python).
Linear algebra is one of the heavy uses of computational code. SciPY includes a sub-package called linalg, which is a wrapper for the package linalg within NumPY. All of the functionality from NumPY is included in scipy.linalg, along with several other functions. In the NumPY module, these linear algebra functions may or may not be handled by external libraries, depending on how NumPY was compiled. With SciPY, this is no longer an option. It needs to be compiled with the ATLAS LAPACK and BLAS libraries to handle the actual numerical work in an optimized fashion. There are functions to handle things like finding an inverse, determinant or transpose of a matrix. If you need to solve a system of equations, you can do so with a single function call. If you start with a coefficient matrix, A, and a right-hand side vector, b, you can find the solution vector for your system with:
from scipy import linalg linalg.solve(A,b)
In many physics and engineering problems, you need to find eigenvalues and eigenvectors. The linalg sub-package provides very fast functions for doing that as well.
Most people default to using R to do statistics, but you don't have to. SciPY includes a stats sub-package that provides many of the functions you will need in the majority of cases. The describe function will give you the basic statistical description of a vector of samples. This includes the mean, variance, skew and kurtosis. Once you have some basic statistics, you probably will want to run a t-test to see how well your data matches your model. You can do this with something like:
stats.ttest_1samp(x, m)
where x is your data and m is your model. This will give you a t-statistic and a p-value. Just as in R, there are many more complicated statistical functions available to you.
A topic near and dear to my heart is solving differential equations. SciPY can help with that task too. The sub-package you need is named integrate. There are two sets of functions, one that takes a function object as the input and one that takes a set of fixed samples. You can do single, double and triple integrations on a function object with the functions quad, dblquad and tplquad. If you have data from some experiment, you integrate it with the trapezoidal rule, Simpson's rule or Romberg Integration. If you are working with ordinary differential equations, some special functions are available. The function odeint will solve a set of ordinary differential equations with a given set of initial conditions.
Last, but not least, let's look at the weave sub-package. Even though SciPY already is full-featured, it can't cover every eventuality. Although you always can write the code in pure Python for whatever piece is missing, sometimes you need to squeeze every last cycle out of your hardware. In those cases, you probably want to write some optimized C code to do the heavy lifting. Although you could write this and compile it as an external object file, that is far too much work for any self-respecting programmer. Enter the weave sub-package.
With weave, you can add C code from within your Python program in a number of ways. The most direct is the inline function. With this, you can write out your C or C++ code, compile it and run it directly within your Python program. All of your Python objects are available within the scope of your inlined code. The contents of any mutable objects are changeable from within your C/C++ code. If you want to return results to your Python program, these are available in a special variable called “return_val”. A trivial example, from the SciPY documentation, uses printf to show how the inline function works:
import weave
a = 1
weave.inline('printf("%d\\n",a);',['a'])
The general form for the inline function is a string containing the code to compile and run, and a list of the Python variables to make available to the C/C++ code. If you have a larger fragment of code you want to inline, you can use triple quotes to define a code block and save it to a variable first. For example, you may have something like:
code = """
for (int i=0; i<a; i++) {
printf("%d\\n", i);
}"""
weave.inline(code, ['a'])
Another way to speed up your code is to let Python do it for you with the blitz function. In this case, blitz takes some NumPY expression and creates C++ code and compiles it to an external module. The first time you do this, it may take several minutes to generate the code and compile it. Once this is done, the compiled object file is stored to be reused the next time it is called. Now you can see a speedup of 2–10 over just straight Python code. It is also saved after Python closes, so you can reuse it the next time you run your Python code.
Now you have some tools available to do some real scientific computations. In my next article, I'll look at matplotlib, one of the ways available to visualize all of this computational work you have been doing. Until then, get some science done.
Setting up Web servers is fairly simple. In fact, it's so simple that once the server is set up, we often don't think about it anymore. It wasn't until I had a very large Web site rollout fail miserably that I started to research a method for load-testing servers before releasing a Web site to production.
There are many, many options for load-testing a Web site. Some are commercial, and some are specific to a particular type of Web server (there are a few SharePoint-specific load testers, for example), but I struggled to find a simple “simulate a bunch of traffic” method to see how a server would handle load.
As is usually the case, many months after I needed the tool, I stumbled across it. A very simple, yet powerful tool named Siege is available in most distributions. Developed by Joe Dog Software, Siege does exactly what's on the tin: it lays siege to your Web server. It has lots of options and features, but by simply specifying a Web URL, Siege will launch a ton of generated hits on your server to see how it performs. To try Siege, you can search your software repository, or head over to www.joedog.org/siege-home to get the program directly from the developer.
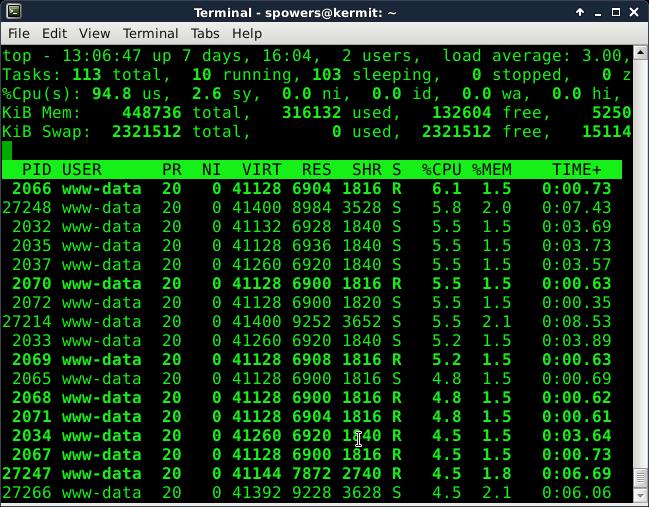
My little Raspberry Pi server didn't crash while under siege, but it certainly was taxed!
It's not the hours you put in your work that counts, it's the work you put in the hours.
—Sam Ewing
If you don't make mistakes, you're not working on hard enough problems. And that's a big mistake.
—Frank Wilczek
No man who ever held the office of president would congratulate a friend on obtaining it.
—John Adams
This is why I loved technology: if you used it right, it could give you power and privacy.
—Cory Doctorow
For one person who dreams of making fifty thousand pounds, a hundred people dream of being left fifty thousand pounds.
—A. A. Milne
