
Sometimes a new piece of code turns out to be more useful than its author suspected. Alejandra Morales recently came out with the Cryogenic Project as part of his Master's thesis, supervised by Christian Grothoff. The idea was to reduce energy consumption by scheduling input/output operations in batches.
This idea turned out to be so good that H. Peter Anvin didn't want Cryogenic to be a regular driver, he wanted it to be part of the core Linux input/output system. On the other hand, he also felt that the programmer interface needed to be cleaned up and made a bit sleeker.
Pavel Machek also was highly impressed and remarked that this could save power on devices like phones and tablets that were always running low. And, Christian confirmed that this was one of the main goals of the code.
Christian added that power savings seemed to be on the order of 10%, though that number could be tweaked up or down by increasing or decreasing the amount of delay that was tolerable for each data packet.
David Lang also liked Cryogenic and agreed that it should go into the core input/output system. He added that a lot of other folks had attempted to accomplish similar things. It was a highly desired feature in the kernel. David also pointed out that in order to get into the core input/output system, the Cryogenic code would have to demonstrate that it had no performance impact on code that did not use its features, or that the impact would be minimal.
Luis R. Rodriguez recently pointed out that a lot of drivers were routinely backported to a large array of older kernels, all the way down to version 2.6.24. And although he acknowledged that this was currently manageable, he expected the number of drivers and other backportable features to continue to increase, making the situation progressively more difficult to sustain.
Luis said the kernel folks should do more to educate users about the need to upgrade. But, he also wrote up a recommendation that the kernel folks use Coccinelle to automate the backporting process (www.do-not-panic.com/2014/04/automatic-linux-kernel-backporting-with-coccinelle.html).
Coccinelle is a tool used to transform source code programmatically. It can be used to generate changes to earlier kernel code to match the functionality provided by newer patches. That's so crazy, it just might work!
But to get started, Luis wanted to draw a line between kernels that would receive backports and kernels that would not. Hopefully, that line would only move forward. So he asked the linux-kernel mailing list members in general, which were the earliest kernels they really needed to keep using.
As it turned out, Arend van Spriel knew of Broadcom WLAN testers that still relied on Fedora 15, running the 2.6.38 kernel. He said he was working with them to upgrade to Fedora 19 and the 3.13 kernel, but that this hadn't happened yet.
So it appears that a certain amount of backporting will become automated, but of course, the Coccinelle transformations still would need to be written and maintained by someone, which is why Luis wanted to limit the number of target kernels.
It turns out Windows does certain things better than Linux—for example, in the area of rebooting. Apparently, there are several techniques that can be done in software to cause a system to reboot. But in some cases, the Linux system will go down successfully, and then not come up again. This is a problem, for example, in server farms with minimal human staff. If 20 systems are acting up and you want to reboot them all, it's easier to give a single command from a remote terminal, than to send a human out into the noise and the cold to press each reset button by hand.
One rebooting technique involves sending certain values to the 0xCF9 port on the system. Another is to use the EFI (Extensible Firmware Interface) BIOS replacement from Intel. Depending on the circumstances, one or the other rebooting technique is preferred, but the logic behind that selection can be tricky. In particular, changing the state of various pieces of hardware can change the appropriate reboot technique. So, if you run through a series of reboot attempts, and somehow change hardware state along the way, you can find that none of the attempts can succeed.
The cool thing about this particular bug is the straightforward way Linus Torvalds said that Windows must be doing something right, and the Linux people needed to figure out what that was so Linux could do it right too.
Steven Rostedt pointed out the boot failure in one of his systems, and this triggered the bug hunt. Part of the problem is that it's very difficult to understand exactly what's going on with a system when it boots up. Strange magical forces are apparently invoked.
During the course of a somewhat heated debate, Matthew Garrett summed up what he felt was the underlying issue, and why the problem was so difficult to solve. In response to any of the various bootups attempted, he said, “for all we know the firmware is running huge quantities of code in response to any of those register accesses. We don't know what other hardware that code touches. We don't know what expectations it has. We don't know whether it was written by humans or written by some sort of simulated annealing mechanism that finally collapsed into a state where Windows rebooted.”
Matthew was in favor of ditching the 0xCF9 bootup technique entirely. He argued, “We know that CF9 fixes some machines. We know that it breaks some machines. We don't know how many machines it fixes or how many machines it breaks. We don't know how many machines are flipped from a working state to a broken state whenever we fiddle with the order or introduce new heuristics. We don't know how many go from broken to working. The only way we can be reasonably certain that hardware will work is to duplicate precisely what Windows does, because that's all that most vendors will ever have tested.”
But, Linus Torvalds felt that ditching CF9 was equivalent to flailing at the problem. In the course of discussion he said, “It would be interesting if somebody can figure out exactly what Windows does, because the fact that a lot of Dell machines need quirks almost certainly means that it's us doing something wrong. Dell doesn't generally do lots of fancy odd things. I pretty much guarantee it's because we've done something odd that Windows doesn't do.”
The discussion had no resolution—probably because it's a really tough problem that hits only a relatively small number of systems. Apparently the bug hunt—and the debate—will continue.
I use my phone more often to log in to on-line accounts than I use a computer. I can assure you it's not because typing passwords on a tiny keyboard is fun. For most of us, we just have instant access to our phones at any given time during the day. The big problem with always using a tiny phone is that it means logging into tiny Web sites (especially if there is no mobile version of the site) with tiny virtual keys and a long, complex password. It makes for real frustration.
With PasswordBox, you not only can store your user names and passwords, but also log in to those Web sites with a single click. Once you authenticate with your master password to the PasswordBox app, it will allow you to create login profiles for dozens of sites and give you the ability to add entries for your own personal sites. If you want to log in to your bank with your phone, but don't want anyone to see you type in your banking credentials, PasswordBox is the perfect tool for you.

With great power comes great responsibility, and it's important to understand what PasswordBox allows you to do. When you initially launch it, you'll be prompted for how you desire the application to handle when it locks your data and requires you to retype the master password. Ideally, this would be “immediately after you quit the app”, but PasswordBox allows you to sacrifice security for convenience and will stay unlocked anywhere from 30 seconds to several hours. It even will let you rely on your Android lock screen for security and never prompt you for your master password!
Even with its potential for insecurity, PasswordBox is a powerful and convenient tool that makes using your phone much less burdensome when logging in to on-line services. In fact, it greatly can improve security as you won't need to type in your banking information in plain sight of the guy next to you at McDonald's. For those reasons, PasswordBox gets this month's Editors Choice Award. Check it out today at www.passwordbox.com.
If you're anything like me, your nightstand is full of electronic devices that need to be charged regularly. Every night I have:
Nexus 7 tablet.
Cell phone.
Kindle Paperwhite.
iPad Air.
Fitbit.
Granted they don't all need a daily charge, but the two tablets and cell phone certainly do. Although many of you are probably tsk'ing me for buying an iPad, for this purpose, it's a fine example of a device that is finicky about being charged. Many tablets, the iPad especially, require a lot of amperage to charge properly. Enter the Anker 40W, five-port USB charger.

Before buying the Anker, I had to get a power strip in order to plug in all the wall-warts required to charge my devices. Two of those devices (the Fitbit and Kindle) didn't even come with power adapters, just USB cables to plug in to a computer for charging. With the Anker USB charger, I'm able to use a single, regular-sized power cord to charge all my devices. Because it's designed specifically to charge, it has some great features as well:
Dynamic, intelligently assigned amperage, up to 2.4 amps per port (8 amps max for all ports combined).
Compact size (about the size of a deck of playing cards).
Supports Apple, Android and other USB-based charging.
I've been using the Anker charger for several weeks and absolutely love it. There also is a 25 watt version if you don't need the full 40 watts, but I highly recommend getting the larger version, just in case you need more power in the future.
I purchased the charger on Amazon for $26, and although that's more than I'd normally pay for a USB charger, it's more like getting five chargers in one. Check it out at www.ianker.com/support-c7-g345.html.
Text expansion and hotkey automation are the sort of things you don't realize you need until you try them. Those of you who ever have played with system settings in order to change the function of a keystroke on you system understand the value of custom hotkeys.
For Windows users, the customization of keystrokes is pretty limited with the system tools. Thankfully, the folks at www.autohotkey.com have created not only an incredible tool for creating scripted hotkeys, but they've also included automatic text expansion/replacement for speed boosts on the fly.

Programming the hotkeys and text replacements is pretty straightforward, and the Web site offers plenty of tutorials for making complex scripts for elaborate automation. Even if you just want to do a few simple hotkeys, however, AutoHotkey is a tool you really want to check out. Best of all, it's completely open source, so there's no reason not to go download it today!
I am a visual learner. When I try to teach something, I naturally like to use visual examples. That usually involves me working for hours to create flowcharts in Google Docs using the drawing program. Yes, it works, but it's a very cumbersome way to create a flowchart. Thankfully, I recently discovered Lucidchart (www.lucidchart.com).
Lucidchart is an on-line service that provides a free way to create flowcharts quickly and easily. Once the flowchart is created, items can be dragged around, resized and modified while still staying connected. I used Lucidchart for this month's Open-Source Classroom column, and if you need to create a quick flowchart, I recommend you give it a try as well.
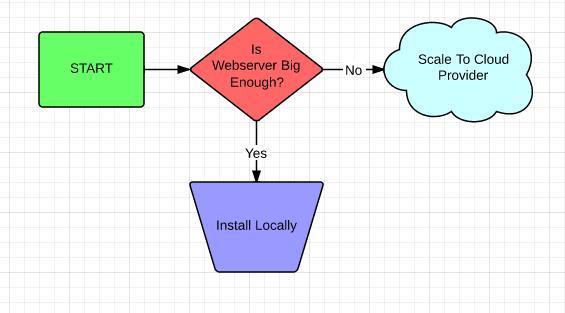
Lucidchart provides its service for free, but there also are paid tiers that give you more options, such as importing and exporting Visio documents and so on. There certainly are other more powerful charting tools available, but few are as simple and quick to use.
Several computer algebra systems are available to Linux users. I even have looked at a few of them in this column, but for this issue, I discuss OpenAxiom (www.open-axiom.org). OpenAxiom actually is a fork of Axiom. Axiom originally was developed at IBM under the name ScratchPad. Development started in 1971, so Axiom is as old as I am, and almost as smart. In the 1990s, it was sold off to the Numerical Algorithms Group (NAG). In 2001, NAG removed it from commercial sale and released it as free software. Since then, it has forked into OpenAxiom and FriCAS. Axiom still is available. The system is specified in the book AXIOM: the Scientific Computation System by Richard Jenks and Robert Sutor. This book is available on-line at wiki.axiom-developer.org/axiom-website/hyperdoc/axbook/book-contents.xhtml, and it makes up the core documentation for OpenAxiom.
Most Linux distributions should have a package for OpenAxiom. For example, with Debian-based distributions, you can install OpenAxiom with:
sudo apt-get install openaxiom
If you want to build OpenAxiom from source, you need to have a Lisp engine installed. There are several to choose from on Linux, such as CLisp or GNU Common Lisp. Building is a straightforward:
./configure; make; make install
To use OpenAxiom, simply execute open-axiom on the command line. This will give you an interactive OpenAxiom session. If you have a script of commands you want to run as a complete unit, you can do so with:
open-axiom --script myfile.input
where the file “myfile.input” contains the OpenAxiom commands to be executed.
So, what can you actually do with OpenAxiom? OpenAxiom has many different data types. There are algebraic ones (like polynomials, matrices and power series) and data structures (like lists and dictionaries). You can combine them into any reasonable combinations, like polynomials of matrices or matrices of polynomials. These data types are defined by programs in OpenAxiom. These data type programs also include the operations that can be applied to the particular data type. The entire system is polymorphic by design. You also can extend the entire data type system by writing your own data type programs. There are a large number of different numeric types to handle almost any type of operation as well.
The simplest use of OpenAxiom is as a calculator. For example, you can find the cosine of 1.2 with:
cos(1.2)
This will give you the result with 20 digits, by default. You can change the number of digits being used with the digits() function. OpenAxiom also will give you the type of this answer. This is useful when you are doing more experimental calculations in order to check your work. In the above example, the type would be Float. If you try this:
4/6
the result is 2/3, and you will see a new type, Fraction Integer. If you have used a commercial system like Maple before, this should be familiar.
OpenAxiom has data types to try to keep results as exact values. If you have a reason to use a particular type, you can do a conversion with the :: operator. So, you could redo the above division and get the answer as a float with:
(4/6)::Float
It even can go backward and calculate the closest fraction that matches a given float with the command:
%::Fraction Integer
The % character refers to the most recent result that you calculated. The answer you get from this command may not match the original fraction, due to various rounding errors.
There are functions that allow you to work with various parts of numbers. You can round() or truncate() floating-point numbers. You even can get just the fractional part with fractionPart().
One slightly unique thing in OpenAxiom is a set of test functions. You can check for oddness and evenness with the functions odd?() and even?(). You even can check whether a number is prime with prime?(). And, of course, you still have all of the standard functions, like the trigonometric ones, and the standard operators, like addition and multiplication.
OpenAxiom handles general expressions too. In order to use them, you need to assign them to a variable name. The assignment operator is :=. One thing to keep in mind is that this operator will execute whatever is on the right-hand side and assign the result to the name on the left-hand side. This may not be what you want to have happen. If so, you can use the delayed assignment operator ==. Let's say you want to calculate the square of some numbers. You can create an expression with:
xSquared := x**2
In order to use this expression, you need to use the eval function:
eval(xSquared, x=4)
You also can have multiple parameters in your expression. Say you wanted to calculate area. You could use something like this:
xyArea := x * y eval(xyArea, [x=2, y=10])
The last feature I want to look at in this article is how OpenAxiom handles data structures. The most basic data structure is a list. Lists in OpenAxiom are homogeneous, so all of the elements need to be the same data type. You define a list directly by putting a comma-separated group in square brackets—for example:
[1,2,3,4]
This can be done equivalently with the listfunction:
list(1,2,3,4)
You can put two lists together with the append function:
append([1,2],[3,4])
If you want to add a single element to the front of a list, you can use the cons function:
cons(1, [2,3,4])
List addressing is borrowed from the concepts in Lisp. So the most basic addressing functions to get elements are the functions first and rest. Using the basic list from above, the function:
first([1,2,3,4])
will return the number 1, and the function:
rest([1,2,3,4])
will return the list [2,3,4]. Using these functions and creative use of loops, you can get any element in a given list. But, this is very inconvenient, so OpenAxiom provides a simpler interface. If you had assigned the above list to the variable mylist, you could get the third element with:
mylist.3
or, equivalently:
mylist(3)
These index values are 1-based, as opposed to 0-based indexing in languages like C.
A really unique type of list available is the infinite list. Say you want to have a list of all integers. You can do that with:
myints := [i for i in 1..]
This list will contain all possible integers, and they are calculated only when you need the value in question. You can have more complicated examples, like a list of prime numbers:
myprimes := [i for i in 1.. | prime?(i)]
One issue with lists is that access times depend on how big the list is. Accessing the last element of a list varies, depending on how big said list is. This is because lists can vary in length. If you have a piece of code that deals with lists that won't change in length, you can improve performance by using an array. You can create a one-dimensional array with the function:
oneDimensionalArray([2,3,4,5])
This assigns a fixed area of memory to store the data, and access time now becomes uniform, regardless of the size of the list. Arrays also are used as the base data structure for strings and vectors. You even can create a bits data structure. You could create a group of eight 1-bits with:
bits(8,true)
In this way, you can begin to do some rather abstract computational work.
As you have seen, OpenAxiom, and its variants, are very powerful systems for doing scientific computations. I covered only the very basic functionality available here, but it should give you a feeling for what you can do. In the near future, I plan to take another look at OpenAxiom and see what more advanced techniques are possible, including writing your own functions and programs.
It is necessary to try to surpass oneself always; this occupation ought to last as long as life.
—Queen Christina
We go where our vision is.
—Joseph Murphy
I didn't mind getting old when I was young. It's the being old now that's getting to me.
—John Scalzi
There's no such thing as quitting. Just sometimes there's a longer pause between relapses.
—Alan Moore
It is better to offer no excuse than a bad one.
—George Washington
