
Containers are very tricky to implement. Trying to isolate sets of resources from each other completely, so that they resemble a discrete system, and doing it in a secure way, has to be addressed on a feature-by-feature basis, with many caveats and uncertainties. Over time, this makes the core kernel code more secure and robust, but each individual feature may have surprising issues.
The whole namespace idea—corralling subsets of system resources like user IDs and group IDs, and performing on-the-fly translations between the resource names within the container and the corresponding names in the outer system—is tough to manage.
Recently, Marian Marinov noticed that process counters in the outer system counted processes as being owned by the same user if his or her UIDs (user IDs) were the same inside two separate containers. The same was true for GIDs (group IDs). He didn't like this, because the two containers represented two logically isolated systems, and in that context, the same UIDs could refer to different users entirely. They shouldn't be counted together.
He wanted to patch the kernel to isolate these values, so that the process counters wouldn't get them mixed up with each other. But, Eric W. Biederman didn't like Marian's idea of creating namespace-specific data structures within the kernel. He offered some workarounds, but Marian didn't like any of them. He said they were less efficient than his idea, and they would require him to put a lot of effort into redesigning his particular use case, which ran a batch of identical containers, each built out of a single master template.
Ultimately, Eric suggested implementing something akin to Marian's idea, but only for certain filesystems. The problem, he said, was that XFS exposed too much of its inner workings to userspace, making it hard to perform the namespace translations correctly. If they limited support only to “normal” filesystems, Eric said, it would be much easier to give Marian what he wanted.
But, James Bottomley pointed out that Linux distributions wouldn't sacrifice XFS for anything. It had already been tried with the USER_NS feature. Distributions wouldn't accept USER_NS unless it supported XFS. James argued that the same would be true here.
Eric replied that the two cases were different. His solution would not preclude using XFS in a Linux distribution; it would only preclude using a particular use case that didn't currently exist anyway. And, Eric also argued that XFS already had serious issues that made it less container-friendly than other filesystems. It was hard to migrate an XFS filesystem to a system with different endianness and word size. This meant one of the common container uses—migrating processes and containers between machines—already was partially off the table for XFS, at least for the moment. That being the case, Eric said, it didn't make sense to go to great lengths to support it in a feature it couldn't use until so many other XFS characteristics had been fixed.
The debate undoubtedly will continue. Ultimately, the question involves identifying where to draw a line between seemingly integrated features of the kernel. What parts of the system can be containerized safely? What parts have to wait until other issues are addressed? In some cases, the end result will be much cleaner kernel code; in other cases, in the short term, much messier.
Some features get so big and complicated that they can't be changed easily anymore. In particular, it becomes harder to fix design flaws, because each fix has to account for all the existing special wonkiness. The printk() function is one example. Its code apparently has become such a nightmare that kernel developers must choose worse solutions to their problems, just in order to avoid a redesign process that is made so difficult by printk()'s current insane implementation.
Recently, Petr Mladek submitted some code to allow calling printk() from within an NMI (non-maskable interrupt). This is useful when a system is in the midst of crashing and needs to output logging data to help the user identify what went wrong. The problem was that printk() needed to take a lock that might be held by another process. That's a big no-no in NMIs, because the whole point of NMIs is that they never can be interrupted by other processes. The printk() would loop forever, waiting for a process to release a lock, when that process would never get the CPU cycles it needed to release that lock. Presto, deadlock.
Petr's code solved this by taking the lock only if available and failing over to an alternate solution if necessary. Overall, Petr's code improved the situation, because users actually were seeing lockups that could be better-diagnosed with printk()s in NMIs. Specifically, Jiri Kosina said, “we've actually seen the lockups triggered by the RCU stall detector trying to dump stacks on all CPUs, and hard-locking the machine up while doing so.”
But, as Frédéric Weisbecker put it, the printk() code base was an “ancient design” with “fundamental flaws”. Its poor design forced Petr's patch to be 1,000 lines long when such a fix ordinarily might be much smaller (Linus Torvalds later estimated 15 lines as a good size for Petr's features). Frédéric suggested, “shouldn't we rather redesign it to use a lockless ring buffer like ftrace or perf ones?”
Jiri agreed that the printk() code base was “a stinking pile of you-know-what”, and that a redesign would be better than Petr's stop-gap patch. But in fact, he said, the correct design was not yet known, but regardless certainly would take a long time to implement and would delay Petr's important fix that addressed real-world crashes. And as Frédéric added, there also was the danger that “if we push back this bugfix, nobody will actually do that desired rewrite.”
At some point, Frédéric asked for Linus' opinion, and Linus essentially torpedoed Petr's whole approach. He said:
Printing from NMI context isn't really supposed to work, and we all know it's not supposed to work.
I'd much rather disallow it, and if there is one or two places that really want to print a warning and know that they are in NMI context, have a special workaround just for them, with something that does not try to make printk in general work any better.
Dammit, NMI context is special. I absolutely refuse to buy into the broken concept that we should make more stuff work in NMI context. Hell no, we should not try to make more crap work in NMI. NMI people should be careful.
Make a trivial “printk_nmi()” wrapper that tries to do a trylock on logbuf_lock, and maybe the existing sequence of:
if (console_trylock_for_printk()) console_unlock();then works for actually triggering the printout. But the wrapper should be 15 lines of code for “if possible, try to print things”, and not a thousand lines of changes.
Which, Petr said, was exactly what his patch did, but he just needed 1,000 lines of code instead of 15 because of how broken printk() was already. And Jiri said, “I find it rather outrageous that fixing real bugs (leading to hangs) becomes impossible due to printk() being too complex. It's very unfortunate that the same level of pushback didn't happen when new features (that actually made it so complicated) have been pushed; that would be much more valuable and appropriate.”
At this point, Paul McKenney offered a compromise. Since Petr's patch was inspired by the RCU (read-copy-update) stall detector using NMIs to dump the stack, and thus needing printk(), Paul could rewrite the RCU code to avoid using NMIs for the stack dump. This way, regular printk() would work, without requiring Petr's patch.
The problem with this was that RCU wouldn't do quite as good a job of dumping the stack data. As Jiri put it, “this is prone to producing not really consistent stacktraces though, right? As the target task is still running at the time the stack is being walked, it might produce stacktraces that are potentially nonsensical.”
But, Linus was insistent. He said, “We should stop using nmi as if it was something 'normal'. It isn't. Code running in nmi context should be special, and should be very very aware that it is special. That goes way beyond 'don't use printk'. We seem to have gone way way too far in using nmi context. So we should get rid of code in nmi context rather than then complain about printk being buggy.”
So, Paul's solution, even being known to provide worse stack dumps than Petr's, would be adopted, simply because it could avoid making further changes to printk(). Jiri said, “I feel bad about the fact that we are now hostages of our printk() implementation, which doesn't allow for any fixes/improvements. Having the possibility to printk() from NMI would be nice and more robust...otherwise, we'll be getting people trying to do it in the future over and over again, even if we now get rid of it at once.”
I love Evernote. I pay for a premium membership, and to be honest, I don't think I even use the premium features. I just love Evernote so much, I want to support the company. But in the spirit of fair comparison, I forced myself to try Google Keep.
It's pretty neat. Honestly though, even though Google Keep has matured quite a bit, I don't see it as a competitor with Evernote. I thought that was what it was going to be, but to me it seems more like a really awesome sticky-note program that syncs seamlessly between devices. The Web interface (keep.google.com) mirrors the Android app almost exactly, and it syncs in what seems like real time. You can grab notes to rearrange them, and yes, you can search notes using Google's powerful search engine.
Perhaps it's the lack of integration with other apps, or perhaps it's just that Google Keep is so new compared to Evernote, but I couldn't use it on a daily basis for more than quick notes here and there. I'd be curious to know if there are any Google Keep fanatics out there who can't imagine life without it. For me, Evernote combined with Nixnote is still the ultimate tool for keeping track of, well, everything! Download Google Keep from the Google Play store and give it a try. It really is a neat app, and if you're not an Evernote addict, it might be perfect!
For years I avoided installing keyboard shortcut tools on my computers. I thought dog-gonnit, if something needed to be typed out, I'd type every letter myself. Recently I capitulated, however, and I must say, going back seems unlikely. If you've never tried a text-replacement app, I highly recommend doing so. The time it saves is incredible, and after I abandoned my grouchy old ways, I've grown to love it.
Unfortunately, there aren't too many options in Linux for really good text-replacement apps. My personal favorite is Autokey. It can be a challenge to set up, but that's mainly because it's so powerful. If you want text replacement to work only in a particular app (think programming code shortcuts), it can be set to work only with those apps. If you want to have a special hotkey required before text replacement works, that's an option too. In the screenshot here, you can see I make a simple auto-replacement shortcut so that every time I type “ttt”, it replaces it with a sentence. It works only in gedit, because that's the constraint I set in the settings.
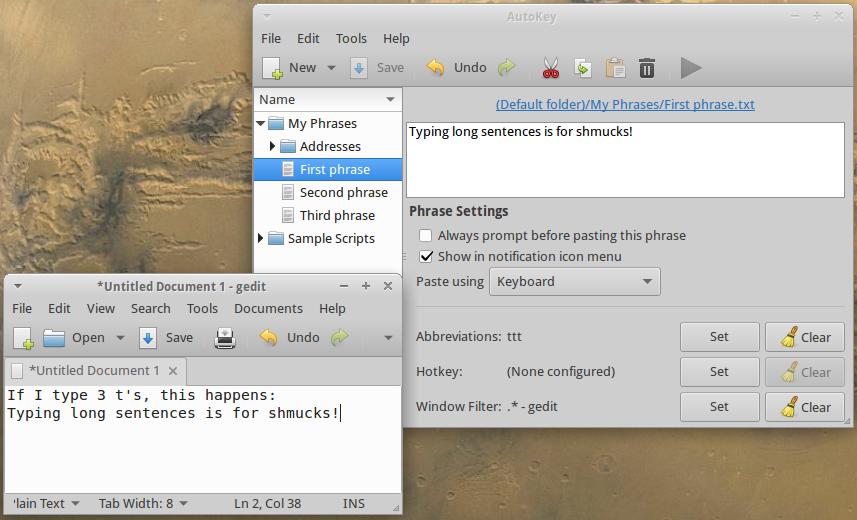
Even though it has a very complicated interface, the Autokey program is a great program, and one we hope continues to get updated once it no longer works. It's currently available for Ubuntu 12.04 and below, but it will install on recent versions without a problem. Autokey takes this month's Editors' Choice award, because once you start using it, you won't be able to imagine life without it! Get your copy today at https://code.google.com/p/autokey.
For new Linux users, the command line is arguably the most intimidating thing. For crusty veterans like me, green text on a black background is as cozy as fuzzy slippers by a fireplace, but I still see CLI Companion as a pretty cool application.
The concept is pretty easy. It's a GUI environment that allows you to double-click your way into entering CLI commands. You can create your own commands (sort of like bookmarks for the command line), or you can search from within the large database of common applications. Oh, and if the command requires command-line arguments? The application pops up a window prompting you to enter them in.
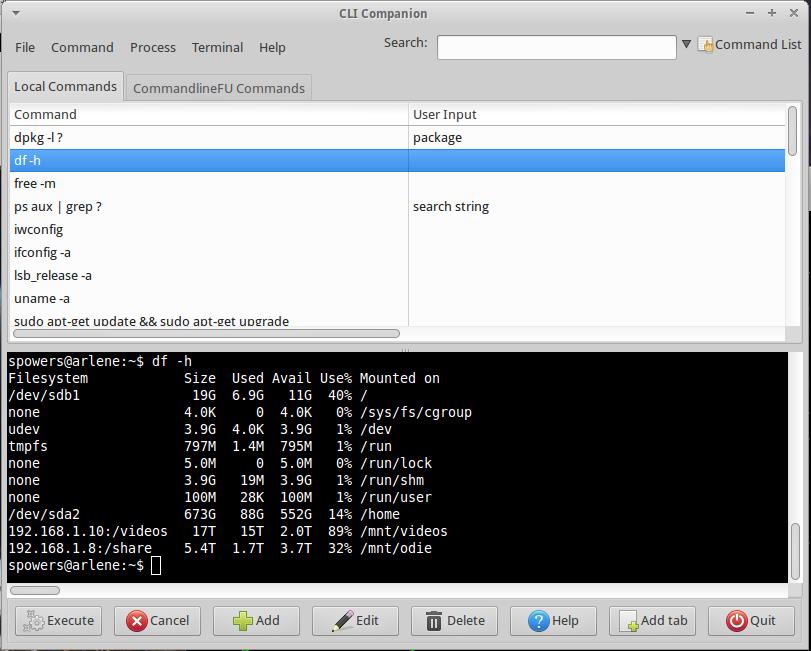
If you're a dyed-in-the-wool Linux professional, CLI Companion might seem like a silly thing to install. If the command line is intimidating, on the other hand, it might be the perfect tool to help you gain mastery. Heck, as I scrolled through the database of applications, I learned a few command-line tools I didn't know existed!
If a GUI CLI is an oxymoron you'd like to check out, surf over to https://launchpad.net/clicompanion and check it out.
We mention Autokey later in this issue as a great tool for text replacement in real time on Linux. Thankfully, there's an option for Windows users that actually is even more powerful than Autokey! AutoHotkey is a similarly named application that runs strictly under Windows. It's still FOSS, but there's unfortunately no version for Linux.
The premise for AutoHotkey is the same as Autokey for Linux. Type a quick short bit of text, and it will expand that shortcut into the predefined text you tell it to use. I find this useful while programming, as creating those curly braces in pairs is very useful. The program is a bit of a bear to configure, because there's no GUI to configure keys. In order to configure the program, you write a text-based script that defines your shortcuts.
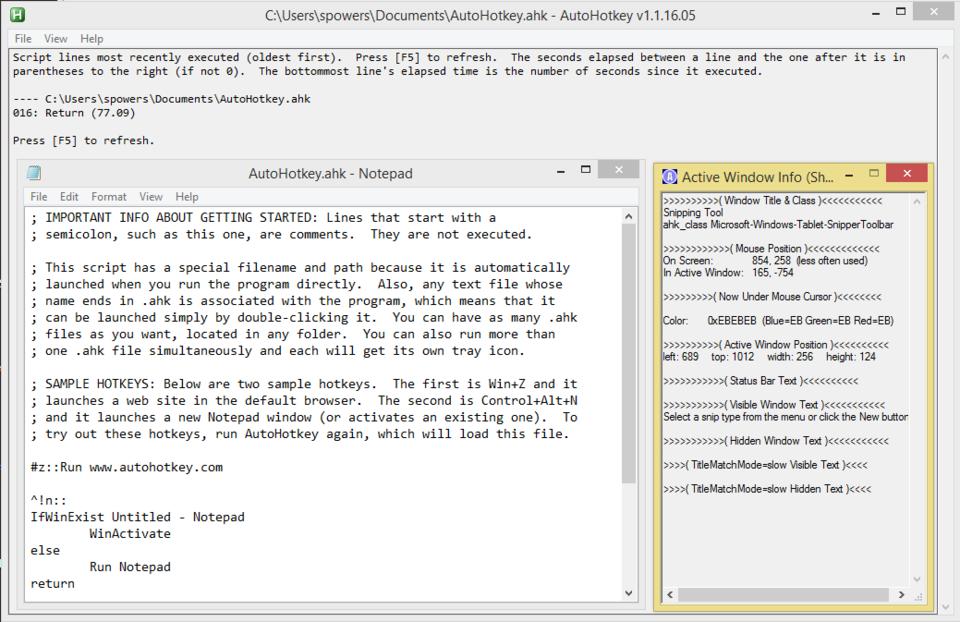
AutoHotkey (AHK it's sometimes called) even allows you to pre-compile your shortcuts into an executable so you don't need to re-program them when you move to a new computer. Grab your .exe file, and run it when you visit your folks for the holidays. (But don't make a shortcut that automatically misspells your sibling's name when your parents type it...or if you do, don't blame me!)
AutoHotkey is free, and it's available at ahkscript.org. There's a nice quick-start tutorial as well to help you get started, because like I mentioned, it's a little rough at first. If you're stuck typing a lot of text on a Windows machine, check out AutoHotkey today!
I've covered a lot of various pieces of software that are designed to help you do scientific calculations of one type or another, but I have neglected a whole class of computational tools that is rarely used anymore. Before there was the electronic computer, computations had to be made by hand, so they were error-prone. To try to minimize these human errors, shortcuts and aids of one form or another were developed.
A common computational problem is to solve equations of some number of variables. The tool that was developed for this class of problem is the nomograph, or nomogram. A nomograph uses a graphical representation of an equation to make solving the equation as simple as setting down a straightedge and reading off the result. Once a nomograph is constructed, it is one of the fastest ways to solve an equation by hand.
In this article, I explore some common nomographs that many of you likely will have seen, and I take a look at a Python package, PyNomo (www.pynomo.org), that you can use to create your own. I also walk through creating some new nomographs, which hopefully will inspire you to try creating some too.
First, let me explain what a nomograph actually is. Electrical engineers already should have seen and used one example, the Smith chart. This chart provides a very quick way to solve problems involved with transmission lines and matching circuits. Solving these types of problems by hand was a very tedious task that wasted quite a lot of time, so the introduction of the Smith chart increased productivity immensely.
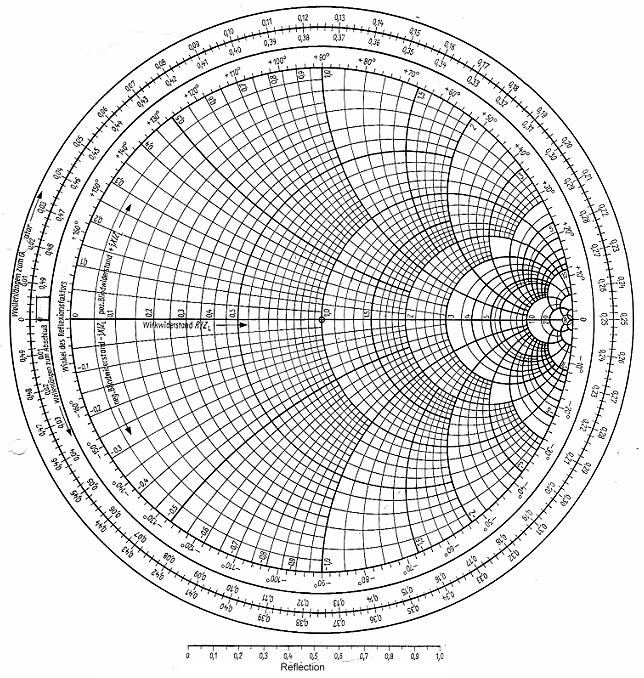
Figure 1. With a Smith chart, you can work on problems around transmission lines and circuit matching.
A Smith chart is scaled in normalized impedance, or normalized admittance, or both. The scaling around the outside is in wavelengths and degrees. The wavelength scale measures the distance along the transmission line between the generator and the load. The degree scale measures the angle of the voltage reflection coefficient at that point. Since impedance and admittance change as frequency changes, you can solve problems only for one frequency at a time. The result calculated at one frequency is a single point on the Smith chart. For wider bandwidth problems, you just need to solve for a number of frequencies to get the behaviour over the full range. But, because this isn't meant to be a lesson in electrical engineering, I will leave it as an exercise for the reader to see just how many other problems can be solved with a Smith chart.
Another example, which should be recognizable to any parent, is the height/weight charts used by doctors. These charts allow a doctor to take the weight and height of a child and see where he or she fits on a nonlinear scale that compares one child to the available statistics of a population very quickly. This is much easier than plugging those values into an equation and trying to calculate it manually.
But, what can you do if you want to use a totally new type of nomograph? Enter the Python module PyNomo. The easiest way to install PyNomo is to use pip. You would type:
pip install PyNomo
You may need to preface this command with sudo if you want it installed as a system module. To get started, you need to import everything from the nomographer section with:
from pynomo.nomographer import *
This section contains the main Nomographer class that actually generates the nomograph you want to create. There are ten types of nomographs that you can create with PyNomo:
Type 1: three parallel lines
Type 2: N or Z
Type 3: N parallel lines
Type 4: proportion
Type 5: contour
Type 6: ladder
Type 7: angle
Type 8: single
Type 9: general determinant
Type 10: one curved line
Each of these also is described by a mathematical relationship between the various elements. For example, a type 1 nomograph is described by the relationship:
F1(u1) + F2(u2) + F3(u3) = 0
Each element of a given nomograph must be of one type or another. But, they can be mixed together as separate elements of a complete nomograph. A simple example, borrowed from the PyNomo examples on the main Web site, is a temperature converter for converting between Celsius and Fahrenheit degrees. It is generated out of two type 8 blocks. Each block is defined by a parameter object, where you can set maximum and minimum values, titles and tick levels, as well as several other options. A block for a scale going from –40 to 90 degrees Fahrenheit would look like this:
F_para={'tag':'A',
'u_min':'-40.0,
'u_max':'90.0,
'function':lambda u:celcius(u),
'title':r'$^\circ$ F',
'tick_levels':4,
'tick_text_levels':3,
'align_func':celcius,
'title_x_shift':0.5
}
You will need a similar parameter list for the Celsius scale. Once you have that, you need to create block definitions for each of the scales, which looks like this:
C_block={'block_type':'type_8',
'f_params':C_para }
The last step is to define a parameter list for the main Nomographer class. For the temperature converter, you can use something like the following:
main_params={'filename':'temp_converter.pdf',
'paper_height':20.0,
'paper_width':2.0,
'block_params':[C_block,F_block],
'transformations':[('scale paper')]
}
Now you can create the nomograph you are working on with the Python command:
Nomographer(main_params)

Figure 2. A simple nomograph is a Celsius-Fahrenheit temperature conversion scale.
A more complicated example is a nomograph to help with the calculations involved in celestial navigation. To handle such a complex problem, you need to use a type 9 nomograph. This type is a completely general form. You need to define a determinant form to describe all of the various interactions. If the constituents are functions of one variable, they will create a regular scale. If they are of two variables, they will create a grid section. For example, one of the single scales in this example would look like this:
'g':lambda u:-cos(u*pi/180.0)
Whereas the grid is defined by:
'g_grid':lambda u,v:-sin(u*pi/180.0)*sin(v*pi/180.0)
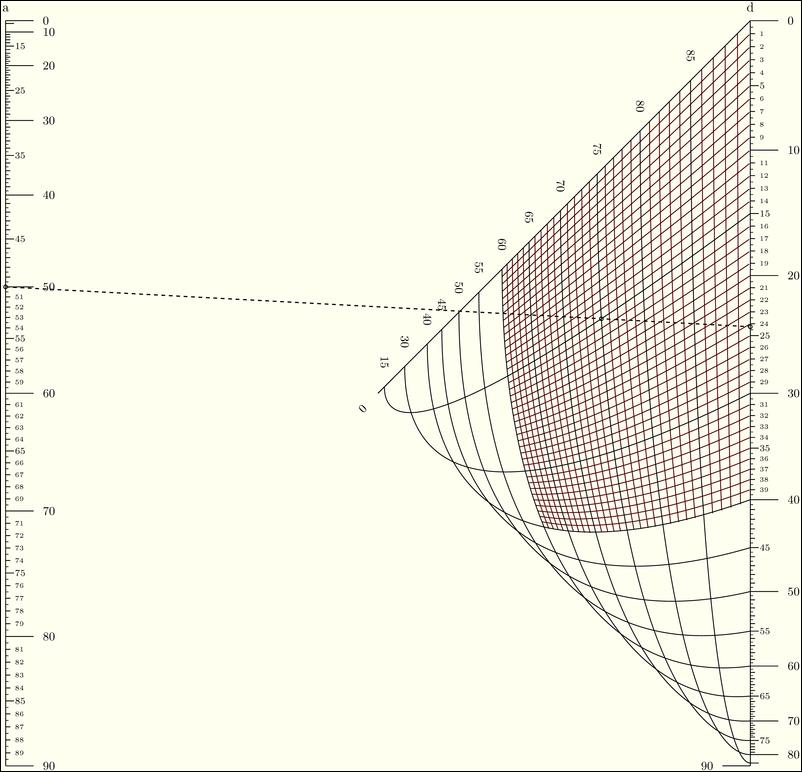
Figure 3. You even can do something as complicated as celestial navigation with a nomograph.
Once this nomograph is constructed, you can use it to compute the altitude azimuth.
PyNomo goes through several steps in generating the nomograph. The last step is to apply any transformations to the various parts. Transformations to individual components can be applied only to type 9 nomographs. If you do apply transformations to individual components, you need to make sure that relative scalings between the various parts are still correct. For other nomograph types, transformations can be applied only to the entire nomograph. There aren't a large number of transformations available yet, but there are enough to handle most customizations that you may want to make. The transformations available are:
scale paper: scale the nomograph to the size defined by paper_height and paper_width.
rotate: rotates the nomograph through the given number of degrees.
polygon: applies a twisting transformation to the tops and bottoms of the various scales.
optimize: tries to optimize numerically the sum squared lengths of the axes with respect to paper area.
With these transformations, you should be able to get the look you want for your nomograph.
Now that you know about nomographs, and even more important, how to make them, you really have no excuse to avoid your trip to that isolated South Pacific island. Go ahead and play with PyNomo and see what other kinds of nomographs you can make and use.
You may be disappointed if you fail, but you are doomed if you don't try.
—Beverly Sills
One person with a belief is equal to a force of 99 who have only interests.
—John Stuart Mill
The freethinking of one age is the common sense of the next.
—Matthew Arnold
Real success is finding your lifework in the work that you love.
—David McCullough
The secret of happiness is to make others believe they are the cause of it.
—Al Batt
