
Sometimes it's necessary to change function semantics inside the kernel, and then find and update all users of that function to match the new semantics. Such changes can result in huge patches going into the source tree, affecting hundreds of files.
Al Viro wanted to do a change like that to a bunch of memory handling routines. He'd noticed that the existing memory allocation tools all returned plain numbers that users then would have to convert to pointers in the vast majority of cases. Al posted a mega-whopper patch, making those functions all return pointers instead of plain numbers.
Linus Torvalds didn't like it though. One of the problems with those immense semantic-changing patches, he said, was that back-porting other unrelated patches became more difficult. For each patch that needed to be backported—security fixes, new drivers and so on—Linus said the port would need to be reworked significantly just in order to get across the barrier of Al's changes. That would be time-consuming for the developer, would increase the likelihood of new bugs, and it didn't seem to carry enough value to justify it.
The way to go about it, Linus said, was to create all new functions, with new names, with the new semantics, and let the various parts of the kernel switch over to the new calls as they pleased. But, even that seemed hard to justify to him.
Ultimately, Al dropped his big patch and posted a new set of guidelines for memory allocation that would help users resolve questions of which functions to use in which circumstance:
1) Most of the time kmalloc() is the right thing to use. Limitations: alignment is no better than word, not available very early in bootstrap, allocated memory is physically contiguous, so large allocations are best avoided.
2) kmem_cache_alloc() allows to specify the alignment at cache creation time. Otherwise it's similar to kmalloc(). Normally it's used for situations where we have a lot of instances of some type and want dynamic allocation of those.
3) vmalloc() is for large allocations. They will be page-aligned, but *not* physically contiguous. OTOH, large physically contiguous allocations are generally a bad idea. Unlike other allocators, there's no variant that could be used in interrupt; freeing is possible there, but allocation is not. Note that non-blocking variant *does* exist - __vmalloc(size, GFP_ATOMIC, PAGE_KERNEL) can be used in atomic contexts; it's the interrupt ones that are no-go.
4) If it's very early in bootstrap, alloc_bootmem() and friends may be the only option. Rule of the thumb: if it's already printed 'Memory: ...../..... available.....' you shouldn't be using that one. Allocations are physically contiguous and at that point large physically contiguous allocations are still OK.
5) if you need to allocate memory for DMA, use dma_alloc_coherent() and friends. They'll give you both the virtual address for your use and DMA address referring to the same memory for use by device; do *NOT* try to derive the latter from the former; use of virt_to_bus() et.al. is a Bloody Bad Idea(tm).
6) If you need a reference to struct page, use alloc_page/alloc_pages.
7) In some cases (page tables, for the most obvious example), __get_free_page() and friends might be the right answer. In principle, it's case (6), but it returns page_address(page) instead of the page itself. Historically that was the first API introduced, so a _lot_ of places that should've been using something else ended up using that. Do not assume that being lower level makes it faster than e.g. kmalloc() - this is simply not true.
System calls notoriously have insufficient error reporting. Some take lots of inputs, and if any of them are wrong in any way, or fail some obscure bounds check, the call returns “EINVAL” for invalid data, but doesn't give any other clue about which piece of data had the problem, or what the value was, or where in the code the problem occurred.
Alexander Shishkin recently tried to implement a solution to this. The real issue though is that the kernel can't simply change the way system calls handle return values. There's code all through the kernel and in userland that depends upon the current behavior. Any solution, therefore, would somehow have to provide additional reporting information, without changing the way existing calling routines received syscall return values.
Alexander's technique took advantage of the fact that system calls generally were processed through a set of macros before sending their return values back to the calling routines. By designing an entirely new set of return values for the actual system calls, Alexander's code could reference an error message holding tank that the macros would be able to process while still returning the originally intended error code to the calling routine.
The macros would place a pointer to the detailed error reports, in JSON format, into the task_struct data structure, where it could be retrieved by the calling routines, using a prctl() call.
Jonathan Corbet, however, had strong doubts about this approach. For one thing, if the calling routine didn't actively query and reset the new debugging data, that data would just sit in the task_struct, getting stale. Although clearing out the debugging data automatically would defeat the purpose of placing it there originally.
And, Johannes Berg also pointed out that with Alexander's changes in effect, applications could break if they had to run on older kernels and expected the new debugging data to be available.
Ultimately, Alexander's approach was not adopted, although no better idea emerged. It's a thorny and persistent problem. It's not clear that any solution will be able to answer all objections, but maybe something will be able to answer more objections than the status quo.
There's a Y2038 bug in Linux. It's the day when the 32-bit UNIX timestamp rolls back to zero. Since Linux basically runs the known universe these days, the bug has to be dealt with, probably by updating the timestamp to hold a 64-bit value. Deepa Dinamani posted some patches to do that, but the problem didn't end there.
The solution had to account for a wide range of possibilities. For example, each different filesystem (NFS, ext4, FUSE and so on) needed its own hand-crafted Y2038 bugfix. It wasn't the kernel alone that needed the fix. Also, after the year 2038, even if all the filesystems had their own fixes, how would a user be able to mount an older filesystem instance that did not have the fix in place? That needed to be solved as well. Additionally, there were corporate interests to consider. Certain service contracts would require a Y2038 fix to be in place, perhaps decades before the bug actually would hit.
Overall, it's going to be a lot of work. Arnd Bergmann, Dave Chinner and Deepa had a long technical conversation about the ins and outs, but the clearest sense of direction to emerge from the discussion was that they should ignore everything that wasn't directly relevant, and they should hew off as many smaller chunks to solve as they possibly could in the hopes that the main chunk might get easier and more manageable.
One thing I truly miss about the “old-school” way of reading the newspaper is that I don't get to read the funny pages. No, that's not all I would read (although admittedly it may have been the first page I turned to), but a little levity always makes the day better. I'm not a big fan of graphic novels or even comic books, but the daily funny pages are just my speed.

Whether you love them or hate them, the GoComics Web site is full of new and old comics alike (www.gocomics.com). The GoComics app for Android is a free way to consume those daily comic strips whether they're new or decades old. My personal favorite comic of all times is Garfield (shown in the screenshot). I collect Garfield memorabilia, Garfield books, and as a kid, I even had Garfield sheets and curtains in my room. Anyway, thanks to the GoComics app, I'm able to read decades of Garfield comics at my leisure, and see the latest strips as well.
If it weren't for GoComics, I'd have to wait to buy the books every year for my daily dose of fuzzy fun. Get the free version in the Google Play Store, or pay an annual fee of about a buck a month to get the ad-free version. Either way, it's a wonderful way to spend a few minutes every day (or an entire afternoon binge session).
For Linux users, scripting user installation is fairly simple. It's possible, but not quite as simple with OS X. Thanks to Per Olofsson, it's possible to distribute user accounts as installable packages that are as simple as a double-click to install.

Managing user accounts is something all sysadmins have to do, and with CreateUserPkg, it's simple to install and distribute. It also includes the ability to create auto-login users, which is convenient, but it does add security concerns since the password can't be encrypted in the PKG file if it's going to be activated as an automatically logged in account. Like all powerful tools, this one can be dangerous, so use only as appropriate!
Check out the program or its source code at magervalp.github.io/CreateUserPkg.
My last full-time job was manager of a university's database department. Ironically, I know very, very little about databases themselves. I'm no longer in charge of college databases, but I still do have a handful of MySQL servers that run my various Web applications. Apart from apt-get install, I have no idea how to make databases work. Thankfully, help is available.
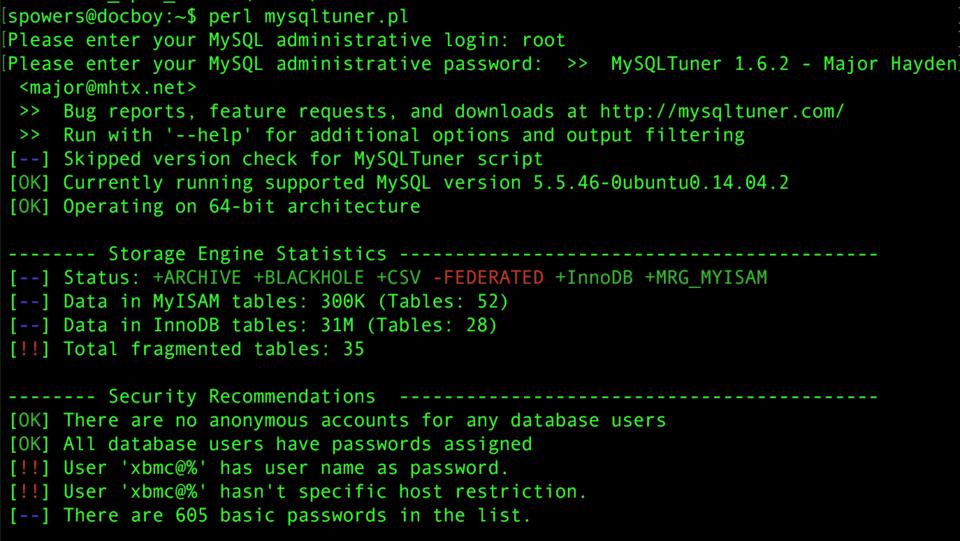
MySQLTuner is a Perl script that checks your local (or remote) MySQL server and gives recommendations for improving security and performance. It does not edit files or actually make changes to the server, but it does give a very lengthy list of recommendations. If you (like me) are the sort of person who just tends to copy/paste database setup instructions, running MySQLTuner is a really good idea.
You can download your copy at mysqltuner.com. Be sure to read the documentation to get the most use out of the program. And, if you discover security problems like the ones shown in my screenshot? Fix them!
Thanks to its ability to help improve and secure MySQL servers that otherwise might be vulnerable, MySQLTuner gets this month's Editors' Choice award. If you're imperfect like me, download a copy today and fine-tune your databases!
I've mentioned many times before the questionable nature of downloading video game ROMs in order to emulate them on your computer. (Heck, my very first article in Linux Journal was a description on how I built a MAME cabinet!) Although I have some emulation tricks up my sleeve for future issues, here I thought I'd mention the vast number of Flash-based emulators available on the Internet.
Some sites are more ad-laden than others, but many of them work quite well. For example, for old-school Nintendo games, check out www.nintendoemulator.com for a huge list of fully functional games. I played Super Mario Brothers on my laptop using Chrome's built-in Flash and wasted a great deal of time doing so!
As with downloading and emulating ROMs locally, you should be aware of potential legal and moral issues. I actually own so many old games that I don't have any moral problem playing with emulators, but I'm not the ultimate authority. If you want to try out some on-line emulators, either search Google for a few options, or visit the site mentioned above. It's a great way to spend a boring afternoon!
I catnap now and then, but I think while I nap, so it's not a waste of time.
—Martha Stewart
As I get older, I've learned to listen to people rather than accuse them of things.
—Po Bronson
The shortest distance between two points is under construction.
—Noelie Altito
In mathematics you don't understand things. You just get used to them.
—Johann von Neumann
Where we have strong emotions, we're liable to fool ourselves.
—Carl Sagan
For this article, I'm returning to portable science software on Android. In a previous article, I looked at a program called xcas/giac. This program is an open-source engine that is used to handle symbolic manipulation of mathematical equations. Because it is open source, it has been ported to several different platforms. Because Android's core is really Linux, a port to the Android platform has been made, and it's available on the Google Play store. Installation is as easy as a quick search on the store and clicking install.
When you first start Xcas Pad, it asks you to enable the keyboard included with the application. It takes you to the Language and Input section of the settings so you can activate the keyboard. When you finish, click the back button and go back to Xcas Pad's main screen. The main screen has four tabs along the top where you can access the main worksheet, a help screen, a plotter screen and a session pane. At the bottom of the xcas pane is an entry line where you can enter the individual xcas commands. The output from each command is displayed in the main portion of the xcas pane. As an example, you can find the derivative of the equation x3–x with the command:
diff(x^3-x)
Figure 1. The main screen is a worksheet where you can start working right away.
Once you enter the equation, you either can tap the done button on the keyboard, or if you tap the back button, you also can tap the enter button at the far right side of the entry line. You then will see a pretty-printed version of your command entry and the results line immediately below it (Figure 2).
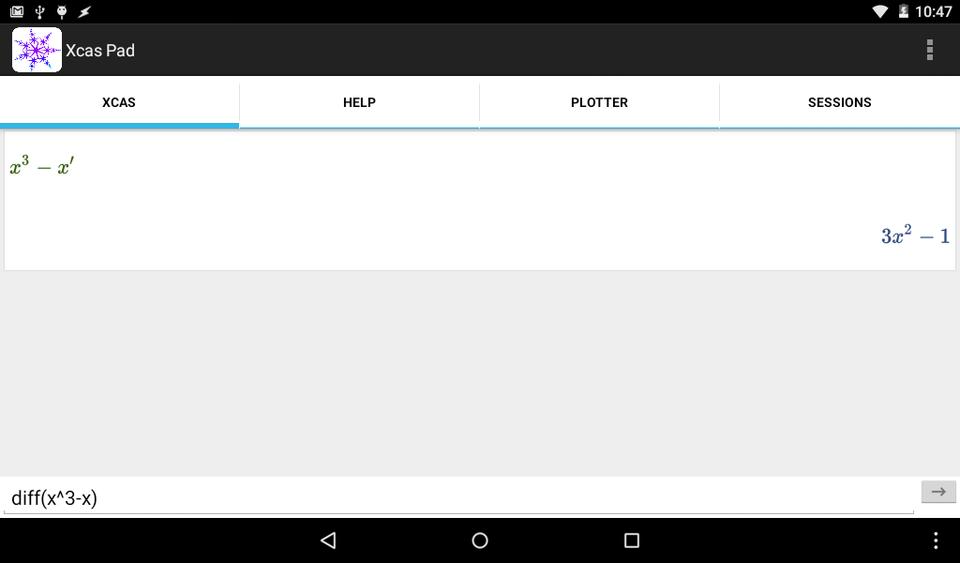
Figure 2. The commands and results are displayed in pretty print on the main panel.
If you tap on the entered command in the display pane, it will be copied and pasted into the entry line, ready for you to edit. You also can tap on the result line to get it copied and pasted into the entry line so you can use it in the next step of your calculation. This is very useful, especially when you are doing discovery-level work.
Xcas is a very large system, however, with many different commands. Part of the problem is trying to find exactly the command you need to use. Tapping on the Help tab at the top of the screen brings up the help pages available within Xcas Pad. At the top, you can enter a search string to narrow the list a bit. You can find a description of the above example command by searching for the string “diff”. Tapping the entry for “diff” pulls up a help page with a short description, a list of examples, related commands and the arguments for the command.
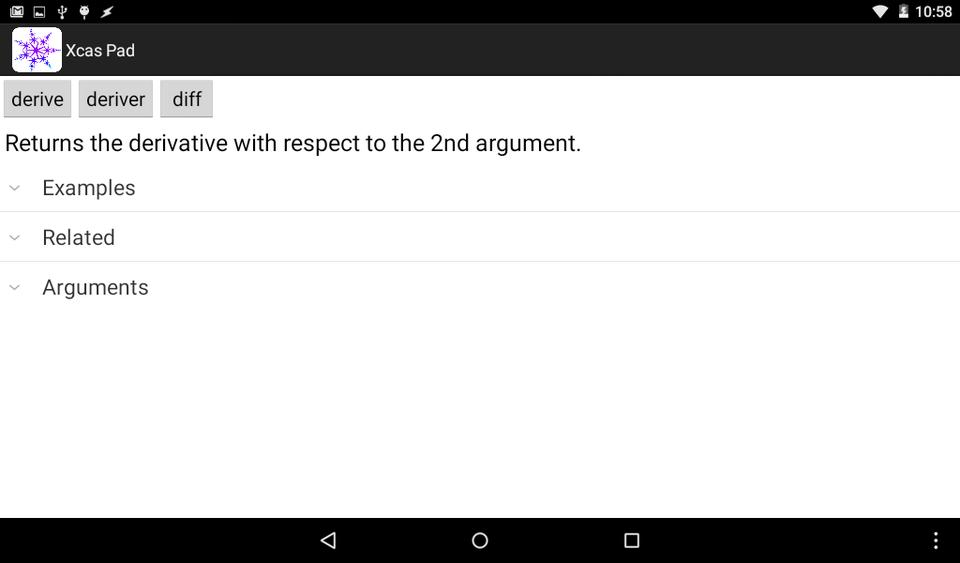
Figure 3. Help information is available for the commands within Xcas Pad.
At the very top of the help page is a list of command names that are aliases and equivalent to each other. Tapping on one of them enters that command name into the entry line of the main worksheet tab.
The list of examples is especially useful. You can tap on one of the examples available, and it will be copied into the entry line of the main worksheet tab. This is a good way to get a starting point for some calculation that you need to do, leaving you with just having to do some edits before you are doing useful work.
One thing to remember is that Xcas Pad is like most other symbolic mathematical programs that are used in that the commands are run sequentially. This means if you want to rerun an earlier command, it will be rerun again based on the current state of the engine. This might be different from one run to another based on what you have been doing between the two runs. For example, you may have rewritten a function that is used within the command in question.
You also can do plotting within Xcas Pad. Doing a search for “plot” in the help page will bring up a rather large number of available commands. Scrolling down to the command plot and tapping it will give you a list of simple examples for basic plots to see what the plots can look like. Entering the following example gives the plot shown in Figure 4.
plot(x-1/6*x^3,x)
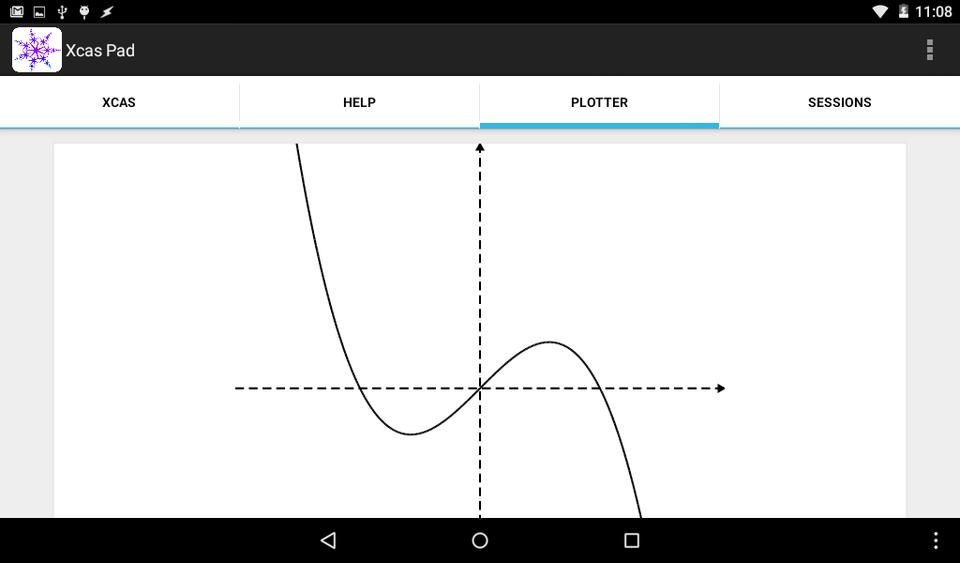
Figure 4. Executing a plot command pops open the plotter tab.
Plots also are pretty-printed and look fairly nice. If you just accept the defaults, you will get bare axes with no labels. Unfortunately, there is not as much customizability available as there is with the desktop versions, so you are kind of stuck with just creating and looking at basic plots. This still can be extremely useful when you are trying to figure out what a particular equation is doing.
Let's say you've been working on some problem for the last hour and want to save your work. These worksheets are called sessions within Xcas Pad. In order to save your current worksheet, you need to tap the option button in the top right corner to get a pull-down menu. From this menu, tapping the entry Save Session brings up a new window where you can enter a filename to use.
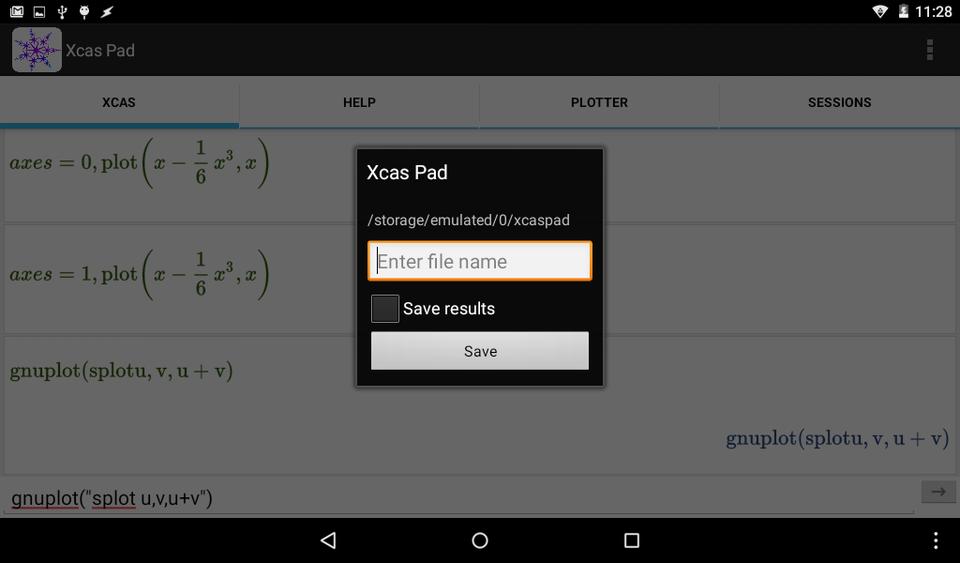
Figure 5. The save session window allows you to enter a filename on your Android device.
There is a check box where you can select whether you also want to save off the results along with the commands from your worksheet. You can reload these saved sessions from the session tab. When you click on it, it gives you a file and directory listing for the default “home” directory on your Android. Any sessions you saved from Xcas Pad will be in the xcaspad sub-directory. You also can copy over other xcas-saved files from work you may have done on your desktop.
When you select one of these session-saved files, you only have the option of running it as a script. This is one major deficiency right now. If you want to make changes to a file before running it, you need to open the session file in a text editor first and make your edits there. Then you can open and run it within Xcas Pad. There are many very good text editors available on Android, so that shouldn't be a blocking problem.
Now you have another tool to help you get some heavy-duty science done on the go. With just your phone or tablet, you can work on your next big idea wherever you like. And if you use a file sharing service, such as Dropbox or Google Drive, you simply can pick up your work from the office wherever you have a few minutes to spare.
