
Filesystem inodes have version numbers that are incremented, well, pretty much any time the filesystem thinks it would be useful. There's not really any standard. Some do it when the inode metadata changes; others also do it when the file data changes as well. Whatever the case, updating the inode version number takes a finite amount of time, which can add up to big delays for certain disk operations.
Jeff Layton saw a way to reduce the number of version number updates by incrementing the version number only when some other piece of code actually queried the filesystem for that information. After all, the actual version number was irrelevant—the calling code didn't care if the number changed by 10, 15 or just 1. All that mattered was that the version was different from the last time it checked.
He posted a patch, and Christoph Hellwig asked for some performance numbers. Jeff said that in general, the performance advantage would depend on the workload, but on his tests, he showed a twofold speed improvement.
Bruce Fields loved Jeff's idea and tried to write some standard requirements that might work across all filesystems. The version should be a 64-bit number, which should be big enough to cover all needs. It should apply to directories and not just plain files. It should work across system reboots. And, the version number should increment whenever any relevant inode data has changed between two queries from outside code.
It's not the easiest set of requirements to meet, especially working across system reboots. A crash can occur at any instant of kernel execution. Making sure the system comes back up in a proper state can require some finagling. What if the system went down after the version number increased, but before the relevant data had been written to the drive?
But, it's not as though this would be a new problem for filesystems, NFS being a perennial case. Trying to have filesystems perform truly atomic operations is tough. At one point Jeff said, “We may end up having to settle for something less (and doing our best to warn users of that possibility).” And as Dave Chinner said:
The big question is how do we know there was a crash? The only thing a journaling filesystem knows at mount time is whether it is clean or requires recovery. Filesystems can require recovery for many reasons that don't involve a crash (e.g. root fs is never unmounted cleanly, so always requires recovery). Further, some filesystems may not even know there was a crash at mount time because their architecture always leaves a consistent filesystem on disk.
The discussion continued for a bit. Ultimately, it's probably not the job of this particular feature to fix systemic problems that exist for all filesystems. But if Jeff's patch makes atomicity even more difficult to implement, that may have to be balanced against the magnitude of the speed improvement it offers. That kind of question usually would work its way up to Linus Torvalds to arbitrate, but only after making its way through the various security and stability concerns that might crop up along the way.
Now that companies are building massive, world-shaking data centers in order to perform tasks of utter complexity in mere fractions of a second, console debugging output speed has become a thing. Calvin Owens from Facebook posted a patch to let users configure exactly how much output to send to the console, on a console-by-console basis. This way the slow consoles could receive less output, and the faster consoles could receive more.
There were a few little nits to pick, such as which existing kernel parameters should be honored or ignored, and which console messages were too important to let the user configure away. But there were no major objections, and the feature seems sure to go into the official tree some time in the near future.
The uaccess.h code provides functions for transferring lots of data between kernel and user space. The problem is that the various architectures have been rolling their own for years, with consequent divergence of semantics and behaviors, not to mention lots of bugs and difficulty preserving secure operations.
Al Viro was in the process of clawing the code back from this state into something that could be worked with. He'd already begun to centralize the mess into an easily accessible location, and now he wanted to make the semantics identical for all architectures. He did this by replacing the existing set of calls with eight standard routines. The only architectures he couldn't fix on his own were metag and ia64, which had odd behaviors that required decisions from maintainers.
There was general agreement that Al was awesome, and the work really needed to be done, but there were some implementation details that some folks still wanted to hash out. For example, Vineet Gupta wanted to inline some of the code to speed things up. But, Al felt that any speed improvement was likely to be seen only on a small number of architectures, and Linus Torvalds was even more fundamentally opposed. He felt that there was not much to gain except in a few cases of largely obscure and hidden functions.
Meanwhile, various folks tested Al's patch on various architectures and reported overall success. In spite of this, Al's current patch represents only one step along a larger path. The metag and ia64 maintainers still need to offer some assistance, and there are further cleanups in the same area of code that Al wants to tackle. In fact, Linus was all for tackling them right there in this patch, but Al wanted to do things in order and get the earlier stuff right before proceeding to the later.
This sort of patch is rarely controversial. Generally, everyone is happy when semantics get cleaned up and the rate of bug production slows. But since this type of patch tends to affect everyone, there are often various stakeholders with issues to address, like unexpected slowdowns.
The older I get, the more I can truly appreciate a good nap. No really, there's just something about it—taking a nap mid-afternoon is an amazing experience. Unfortunately, with a busy work schedule, I find it difficult to take a nap. It's not that I can't afford the 20-minute break; it's just that I can't ever get to sleep—that is, until I discovered Pzizz.
Pzizz is an Android app that generates a custom “nap narrative” that helps ease you off to dreamland and wakes you up when it's over. I was very skeptical about how restful a 20-minute forced nap could be, and at first, I doubted I'd fall asleep at all. Thankfully, I was very wrong.
Pzizz (which my spell check really wants to change to “pizza”) generates an eerie, 3D-sound soundtrack, and it provides verbal prompting that helps lull you off to sleep. And, it works. It works well. The music is hard to describe. There are chimes, strings and ocean sounds, and they all blend into a “moving” 3D auditory experience that knocks me right out. I'm often worried the eerie sounds will give me nightmares, but quite the opposite seems to happen. I always fall asleep, and I always feel rested when the app wakes me up 20 minutes later. (The amount time can be adjusted to suit your nap preferences.)
So far, I've used Pzizz only for naps, but there's also a module to aid with sleeping through the night. I can't wear earphones or earbuds that long, so I've never tried it overnight. I think if I lived alone, I might try connecting my phone to speakers and play Pzizz out loud. If you have a bed mate, it's the sort of thing you'd have to discuss in advance, and I don't think my wife would be keen on the eerie-sounding music and British man's voice all night!
The Pzizz app is free in the Google Play Store, and I can't recommend it enough. In fact, for doing exactly what it claims to do while never trying to push an expensive “upgrade”, Pzizz gets this month's Editors' Choice award. Give it a try this afternoon—unless you're a bus driver, in which case, wait until after work to give it a try.
Through the years, I've used all sorts of router and firewall solutions at home and at work. For home networks, I usually recommend something like DD-WRT, OpenWRT or Tomato on an off-the-shelf router. For business, my recommendations typically are something like a Ubiquiti router or a router/firewall solution like Untangled or ClearOS. A few years ago, however, a coworker suggested I try pfSense instead of a Linux-based solution. I was hesitant, but I have to admit, pfSense with its BSD core is a rock-solid performer that I've used over and over at multiple sites.
It's not that pfSense is better than a Linux solution, but rather, it feels more focused. It seems like many of the firewall/router solutions out there try too hard to be everything for your network. pfSense offers services like DNS, DHCP, SNMP and so on, but out of the box, it just routes traffic and does it very well. Another thing that makes pfSense worth checking out is that there's no “premium” version of it. What you download is the full, complete pfSense product. The only thing you can pay for is support. That model has been around for a long time in the Open Source world, but lately it's been outmoded by the “freemium”-type offerings.
If you're looking for a firewall/router/NAT solution for your network, and you're not afraid to use a non-Linux product, I can't recommend pfSense enough. It's fast, rock-solid, and it has just enough network-related addons available to make it a viable option for small to medium-sized networks. Plus, it's completely free, so you can test it out without any financial commitment! Check it out today at www.pfsense.org.
Most phones have a panoramic photo mode that allows you to take a wide shot by moving the phone as it records. Unfortunately, it's not always convenient to do so. Thanks to digital photos being fast and cheap, I usually take a bunch of snapshots when I'm trying to get a good shot. Occasionally, it would be nice to stitch those photos together into something bigger, but actually doing so is harder than it seems. Different angles combined with perspective shifts means a lowly human with a photo editor has almost no chance of stitching together photos into something believable.
Hugin is an open-source tool available at hugin.sf.net that takes photos and mathematically computes the matching bits in order to stitch together a panoramic shot. It seems like a simple enough task, but if you've ever tried to accomplish something like that manually, you'll truly appreciate Hugin. It's free, it's powerful, and I'm happy to say that it's easy to use as well. I just took two photos out my office window, and I was able to stitch them together with Hugin in about 20 seconds.
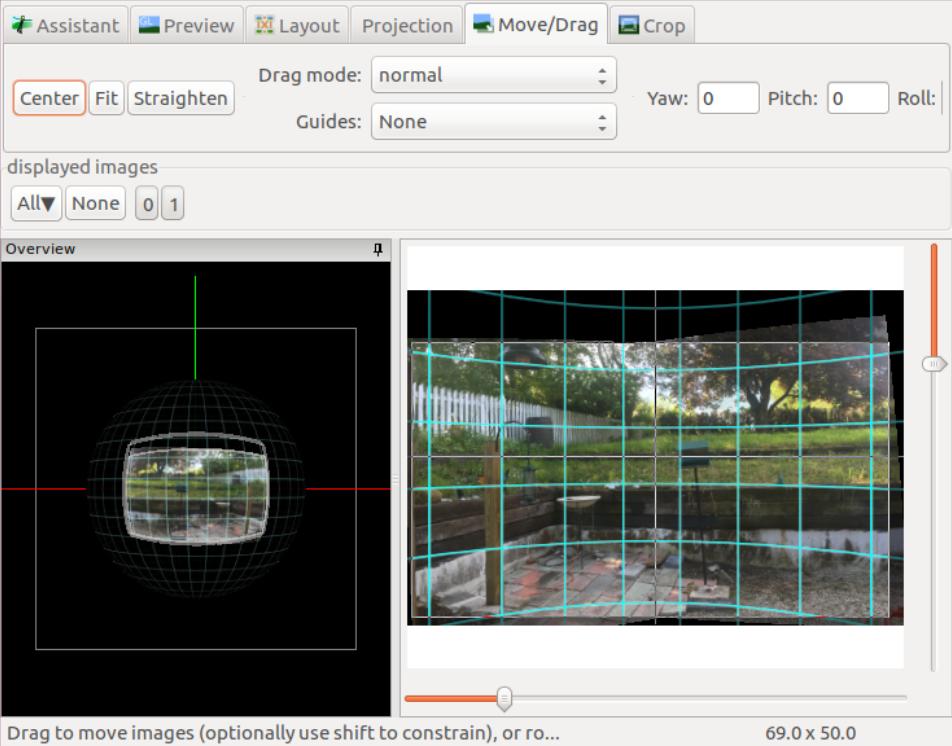
Hugin also supports things like 360-degree compilations, so if you're at all interested in photography, be sure to add Hugin to your list of software packages. It's amazing!
One of the problems with being a nerd is that you always seem to want the latest and greatest items. This year alone, I've struggled to find a Nintendo Classic, a Nintendo Switch and a PlayStation 4 Farpoint VR bundle. Not only are all the stores out of stock, but places like Amazon aren't even taking back orders. Unless you're willing to be price-gouged on eBay, the only option is to wait. Unfortunately, thousands of other people are out there waiting too, so when something comes back into stock, it immediately sells out.
If you don't have the time to check Amazon all day waiting for your must-have product to be restocked, I urge you to check out www.nowinstock.net. It's a site that will notify you when a product is available, which alleviates the need for constantly checking. (Be sure to use .net on that URL, I think the .com is a fake site.)
I ended up buying the Farpoint Bundle on eBay, because I'm so into virtual reality that I didn't want to wait. But if you're a bit more patient than I am, NowInStock might be a perfect tool.
I've looked at several open-source packages for computational chemistry in the past, but in this article, I cover a package written in Python called PyMOL (https://www.pymol.org).
PyMOL is a very powerful program, used for visualizing and analyzing chemical structures. Although the main project is an open-source one, a commercial version is available that provides support for those who need it.
There are several installation options, but I actually suggest that you don't install it directly from the available downloads. You first will need to install a rather large number of dependencies, which may lead you to dependency hell. So, if the package manager for your particular distribution includes a package for PyMOL, it probably will be much easier to use it, especially when you are just learning how to use PyMOL.
As I've mentioned and is obvious from the name, PyMOL is written in Python, and it also uses 3D libraries to handle the actual image rendering. PyMOL also is written with a plugin architecture, which means you can expand PyMOL's feature set to handle new analysis workflows.
When you first start PyMOL, two windows will open (Figure 1). The first is a console window where you will be able to interact with PyMOL programmatically. The second window is the actual viewer for the results of the visualization and analysis of your chemistry problem.

Figure 1. When you first start up PyMOL, you get both a console window and a viewer window.
The most basic usage is as a regular viewer of chemical structures. In order to do that, click the File→Open menu item to pop up a dialog window where you can select the file to open (Figure 2).
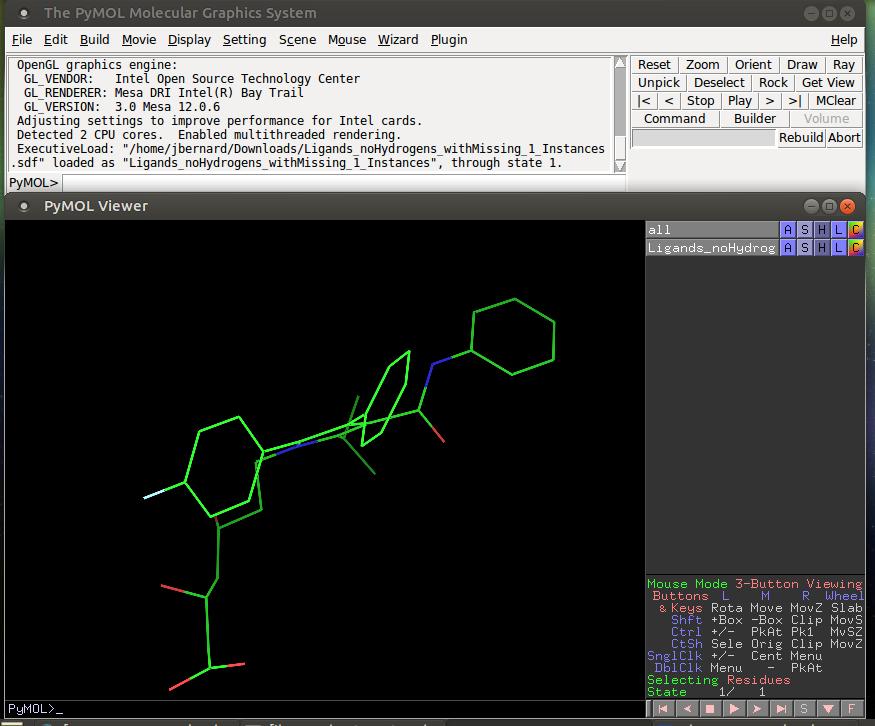
Figure 2. Opening a PDB file renders the molecule within the viewer window.
PyMOL can handle several dozen different file formats. If you don't have any input files of your own yet, you can get PDB files from the RCSB Protein Data Bank in order to explore PyMOL and see what you can do with it (www.pdb.org).
When it opens, you will get the default view of the molecule as a stick figure. Within the viewer window, there are three panes. The left-hand pane contains the actual rendered image. On the right-hand side, there are two smaller panes. The bottom half has a description of mouse actions you can use to manipulate the molecule in the viewer. You can rotate the image, zoom in and out, and control clipping and selection of the objects rendered within the viewing pane. The top half is the object control panel. It contains a list of all of the objects that are being worked with in the current session.
Each object in the list has a series of buttons that can apply functions to that object. There is one special entry at the top of the list that affects all of the objects together. The first button, labeled “A”, is a set of actions you can apply to selected objects. These actions include things like using presets for viewing options or even initiating calculations (Figure 3).

Figure 3. A number of presets are available to make visualization easy.
You can alter several other view options of the display through the action menu. The “S” and “H” buttons provide menus of which elements to show and which elements to hide. The “L” button lets you set what gets labeled within the viewer, and the “C” button lets you play with how colors are used within the rendering.
You also have the option of changing the viewing elements directly within the viewing pane by right-clicking in the viewer. When you do, you get a drop-down menu that allows you to change the zoom, the orientation and what objects are visible, among many other options.
With so many settings to change, you may find yourself in a situation where you can't see the relevant objects anymore, or you may not be able to undo the changes you have made effectively. In those situations, you can right-click the viewer and select the Reset entry to start over from the beginning.
For more complex interactions, a number of wizards are available from the Wizards menu item to help you coordinate these types of interactions. For example, you could work with density maps by clicking the Density option (Figure 4). This gives you a set of tools within the right-hand pane where you can change settings around the density mapping functionality.
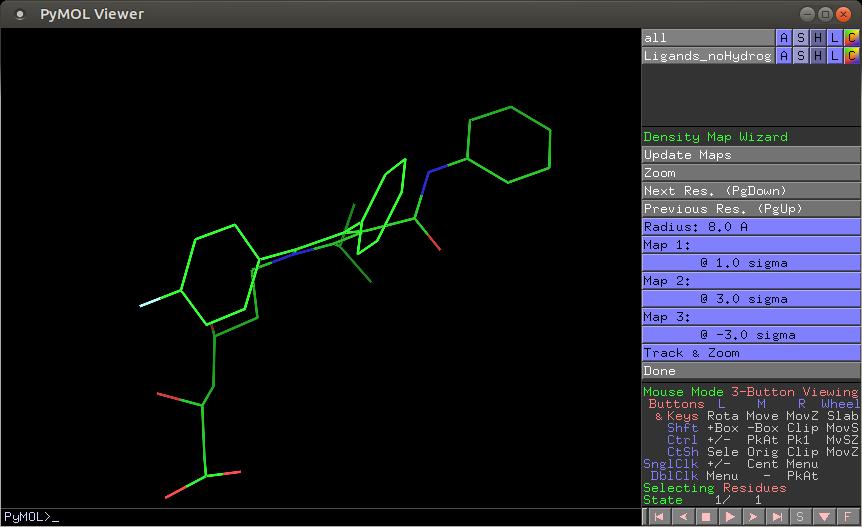
Figure 4. There are wizards to help you with more complex tasks, such as working with density maps.
There is also a suite of plugins, which can add extra features to PyMOL. Go to Plugin→Plugin Manager for a new window where you can work with those plugins (Figure 5).

Figure 5. The plugin manager allows you install, remove and configure your PyMOL plugins.
Clicking the “Install New Plugin” tab provides a few options of how to install your new plugin. The first option allows you to install directly from a file stored on your local filesystem. The second option is to install a plugin from the PyMOL Wiki, and you can enter a URL pointing to a plugin described on one of the Wiki pages. The third option is to select and install a plugin from one of the available repositories of plugins.
When you select one of the repositories from the list, the available plugin list will be populated, and you simply can select the plugin you need from that list.
Although you can write your own full-fledged plugins, you also can add your own customized functionality much more easily by using scripts. PyMOL includes a command language of its own that you can use directly within the console window. These include simple commands, like loading files or saving images, and more complex commands, such as doing fits between two molecules.
Along with these built-in commands, you also have access to a full Python interpreter underneath the hood. This means you can write Python scripts that work with these commands and the objects within your PyMOL session to do even more complex tasks.
Once you have your task figured out, you can save your work within a script file that you can reload later and apply within a different session.
The PyMOL Wiki also hosts a script library, and it's a good place to look before you start down the road of creating your own script, as someone else may have run into the same issue and may have found a solution you can use. If nothing else, you may be able to find a script that could serve as a starting point for your own particular problem.
When you're are done working with PyMOL, there are many different ways to end the session. If there is work you are likely to pick up again and continue with, click File→Save Session to save all of the work you just did, including all of the transitions applied to the view. If the changes you made were actually structural, rather than just superficial changes to the way the molecule looked, you can save those structural changes by selecting File→Save Molecule. This allows you to write out the new molecule to a chemical file format, such as a PDB file.
If you need output for publications or presentations, a few different options are available. Clicking File→Save Image As allows you to select from saving a regular image file in PNG format or writing out data in a POVRay or VRML 3D file format. If you are doing a fancier presentation, you even can export a movie of your molecule by clicking File→Save Movie As. This lets you generate an MPEG movie file that can be used either on a web-based journal or within a slide deck for a presentation.
Learning is not compulsory...neither is survival.
—W. Edwards Deming
Looking forward to things is half the pleasure of them. You mayn't get the things themselves; but nothing can prevent you from having the fun of looking forward to them.
—L. M. Montgomery
To succeed is nothing, it's an accident. But to feel no doubts about oneself is something very different: it is character.
—Marie Leneru
We learn by example and by direct experience because there are real limits to the adequacy of verbal instruction.
—Malcolm Gladwell
One's dignity may be assaulted, vandalized and cruelly mocked, but cannot be taken away unless it is surrendered.
—Michael J. Fox
