
5.6. ISO Character Sets
Unicode
has only
recently become popular. Previously, the space and processing costs
associated with Unicode files prompted vendors to prefer smaller,
single-byte character sets that could only handle English and a few
other languages of interest, but not the full panoply of human
language. The International Standards Organization (ISO) has
standardized 14 of these character sets as ISO standard 8859. For all
of these single-byte character sets, characters 0 through 127 are
identical to the ASCII character set; characters 128 through 159 are
the C1 controls; and characters 160 through 255 are the additional
characters needed for scripts such as Greek, Cyrillic, and Turkish.
- ISO-8859-1 (Latin-1)
-
ASCII plus
the accented letters and other characters needed for most
Latin-alphabet Western European languages, including Danish, Dutch,
Finnish, French, German, Icelandic, Italian, Norwegian, Portuguese,
Spanish, and Swedish.
- ISO-8859-2 (Latin-2)
-
ASCII plus
the accented letters and other characters needed to write most
Latin-alphabet Central and Eastern European languages, including
Czech, English, German, Hungarian, Polish, Romanian, Croatian,
Slovak, Slovenian, and Sorbian.
- ISO-8859-3 (Latin-3)
-
ASCII plus
the accented letters and other characters needed to write Esperanto,
Maltese, and Turkish.
- ISO-8859-4 (Latin-4)
-
ASCII plus
the accented letters and other characters needed to write most Baltic
languages including Estonian, Latvian, Lithuanian, Greenlandic, and
Lappish. Now deprecated. New applications should use 8859-10
(Latin-6) or 8859-13 (Latin-7) instead.
- ISO-8859-5
-
ASCII
plus the Cyrillic alphabet used for Russian and many other languages
of the former Soviet Union and other Slavic countries, including
Bulgarian, Byelorussian, Macedonian, Serbian, and Ukrainian.
- ISO-8859-6
-
ASCII
plus basic Arabic. However, the character set
doesn't have the extra letters needed for non-Arabic
languages written in the Arabic script, such as Farsi and Urdu.
- ISO-8859-7
-
ASCII
plus modern Greek. This set does not have the extra letters and
accents necessary for ancient and Byzantine Greek.
- ISO-8859-8
-
ASCII
plus the Hebrew script used for Hebrew and Yiddish.
- ISO-8859-9 (Latin-5)
-
Essentially
the same as Latin-1, except six letters used in Icelandic have been
replaced with six letters used in Turkish.
- ISO-8859-10 (Latin-6)
-
ASCII plus
accented letters and other characters needed to write most Baltic
languages, including Estonian, Icelandic, Latvian, Lithuanian,
Greenlandic, and Lappish.
- ISO-8859-11
-
ASCII
plus Thai.
- ISO-8859-13 (Latin-7)
-
Yet another
attempt to cover the Baltic region properly. Very similar to Latin-6,
except for some question marks.
- ISO-8859-14 (Latin-8)
-
ASCII plus
the Celtic languages, including Gaelic and Welsh.
- ISO-8859-15 (Latin-9, Latin-0)
-
A revised
version of Latin-1 that replaces some unnecessary symbols, such as
1/4, with extra
French and Finnish letters. Instead of the international currency
sign, these sets include the Euro sign
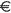 .
.
- ISO-8859-16, (Latin-10)
-
A revised
version of Latin-2 that works better for Romanian. Other languages
supported by this character set include Albanian, Croatian, English,
Finnish, French, German, Hungarian, Italian, Polish, and Slovenian.
Various national standards bodies have
produced other character sets to cover scripts and languages of
interest within their geographic and political boundaries. For
example, the Korea Industrial Standards Association
developed the KS C 5601-1992 standard for encoding Korean. These
national standard character sets can be used in XML documents as
well, provided that you include the proper encoding declaration in
the document and your parser knows how to translate these character
sets into Unicode.
 |  |  |
| 5.5. Unicode |  | 5.7. Platform-Dependent Character Sets |

Copyright © 2002 O'Reilly & Associates. All rights reserved.