
Broken protocols can be fixed on the fly with Netfilter's ability to direct packets to userspace programs.
Recently, one of my clients was experiencing problems with remote print servers. These print servers were on an internally NATted network connected to a central records system located across the state through the Internet. The print servers would not stay connected, dropping the connection after a few minutes. Investigation finally tracked this problem down to the keep-alive protocol used between the central system and the remote print servers. The keep-alive protocol employed a UDP packet with the source and destination IP addresses contained within the data. Normally, this would just mirror the addresses in the UDP header and would seem to be redundant. In this case, the server ignored the UDP header addresses and used only the internal addresses. When the packets went through NAT translation, the internal addresses were sent through unchanged, and the central server was attempting to reply to a nonroutable 10.xxx.xxx.xxx address.
Working with my client, we identified the problem and located documentation that specifically stated the protocol would not work with print servers behind NAT. For a number of reasons, my client was unable to move the print servers to a non-NATted environment, which left the problem of fixing the protocol.
Because all the keep-alive packets already were passing through the Linux firewall, that seemed to be the logical place to fix them. The NF_QUEUE facility in netfilter turned out to be the perfect solution.
Netfilter is part of the packet filtering framework within the Linux 2.4.x and 2.6.x kernels. As stated on the netfilter home page: “Netfilter provides a set of hooks inside the Linux kernel that allows kernel modules to register callback functions with the network stack. A registered callback function is then called back for every packet that traverses the respective hook within the network stack.”
The NF_QUEUE facility extends this ability to userspace, allowing packets to be directed using iptables rules to a userspace program. The program then can look at the packet and take action based on the packet content. The program might decide to accept or reject the packet, for example, allowing the firewall to filter packets based on content. The program also might decide to modify the packet and return it to netfilter for further processing. It is this latter ability that allows broken protocols to be fixed on the fly.
The QUEUE facility initially was introduced into the 2.3 kernel and allowed for a single queue. This was changed to NF_QUEUE in the 2.6.14 and later kernels to allow for multiple queues with a 16-bit queue identifier, so it is possible to have up to 65,535 queues. If the queue number is left off the iptables rule, it will default to queue 0 and the behavior is equivalent to the older QUEUE behavior.
An important point to remember is this is a queue. The kernel queues up packets for processing in userspace, and there is finite space to buffer the packets. If it takes too long to process the packet, the queue will fill up and packets will be lost.
Although my situation and this example use IPv4, the NFQUEUE facility is also available in the IPv6 netfilter code and the ip6tables command. The details of mangling the packet change to reflect the protocol and headers that are involved, and there are slight differences in the ip6tables chain traversal, but the overall process remains substantially the same.
Because the packet processing takes place in userspace, you are not limited to writing the program in C. You can use any language you want, as long as there is a binding to the NF_QUEUE facility. At the time of this writing, in addition to C and C++, you can use Perl and Python to write your packet handler (see Resources).
In my case, I chose to write my routines in C. Because the firewall in question also serves as a gigabit router between two internal networks, supports a VPN gateway as well as handling almost a thousand iptables rules, I was interested in keeping overhead low. C was the natural choice.
Before using NF_QUEUE, it must be enabled in the kernel. If your kernel supports the config.gz option, you can use the following:
gzcat /proc/config.gz|grep -E "NETLINK|NFQUEUE"
and see if the configuration options listed below are set. If you do not have gzcat, it's just a hard link to gzip; many distributions seem to leave that out.
If NF_QUEUE is not configured, you'll have to configure and rebuild the kernel. The configuration parameters that you will need to set are the following:
CONFIG_NETFILTER_NETLINK=y CONFIG_NETFILTER_NETLINK_QUEUE=y CONFIG_NETFILTER_NETLINK_LOG=y CONFIG_NETFILTER_XT_TARGET_NFQUEUE=y
Use your favorite kernel configuration tool, rebuild, install and reboot.
If not present, you also need to build and install libnfnetlink and libnetfilter_queue (see Resources).
Listing 1 shows the standard boilerplate code for an NF_QUEUE packet handler. Steps 1–3 are basic setup. Step 4 creates a specified queue and binds the program to it. The queue identifier must match the queue number used in the iptables rules. This call also registers the callback function, which is where the packet actually is processed. Step 5 tells NF_QUEUE how much data is to be sent to the userspace program. The choice is none, all or just the packet metadata (information from NF_QUEUE, but no packet data).
This is pretty standard, except that under 2.6.23 kernels, step 2 will return an error, which may be safely ignored. The packet is not actually read using the recv() function; it is accessed by a callback function invoked by the nfq_handle_packet() function. In addition to the packet data, this allows access to additional NF_QUEUE metadata and permits re-injection of the packet as well as ACCEPT and DROP decisions to be made. The return code from the recv() call may be used to determine if the queue has filled and packets are being dropped.
Before the program exits, it should close gracefully by unbinding the queue with a call to nfq_destroy_queue(), followed by a call to nfq_close(). In my implementation, I elected to include a signal handler that closed any log files and unbound the queue on receipt of a SIGINT or SIGHUP signal.
The callback function is where the real action is. Here you have access to the entire packet, including headers and NF_QUEUE metadata. Listing 2 shows a simple callback routine that prints the source and destination IP addresses and dumps the packet contents in hex.
When you have finished processing the packet, the routine must return a verdict using the nfq_set_verdict() function. This can be NF_ACCEPT or NF_DROP (other verdicts are possible, but these two cover 99% of the cases). If the packet is unchanged, a zero value length parameter and null pointer can be returned. If the packet has changed, these parameters should point to the new packet. In any case, a call to nfq_set_verdict() must be made for every packet retrieved so the kernel can remove the packet and associated information from its internal data structures.
With access to the packet, combined with an understanding of the protocol, you can mangle the packet to fix almost any conceivable problem. In my case, I used a small lookup table to translate the internal IP addresses to an external address on packets being sent to the central system and the external IP address to the internal address on packets being returned to the print server.
A very important point with packet mangling is that any change to the packet contents will, almost certainly, change the packet checksum. The IP header checksum will be unchanged unless you modify the source or destination IP addresses. However, any change to the packet contents will change the checksum for UDP or TCP packets. When the kernel NATs the packet, it does not recompute the checksums. Instead, it optimizes the process by modifying only the current checksums with the difference between the old and new addresses. If the kernel does not use NAT, the checksum is not even inspected. This means the checksums must be correct when returning the packet to the kernel. Actually, with UDP packets, you can cheat by using a 0 checksum. The UDP protocol specification states the checksum is optional, and a 0 value indicates that you have not calculated it. That is not a recommended practice, particularly when traversing external networks, but you can get away with it. With TCP packets, this is not an option; the TCP header must contain a correct checksum. Any packet with an incorrect checksum will be dropped by the next network device it hits.
There are a number of ways to determine if your checksum is correct. The easiest is to look at the packet using a sniffer like Wireshark (Figure 1). Unlike tcpdump, which will print only the packet contents, Wireshark will verify the packet checksums and even tell you what they should be if not correct.
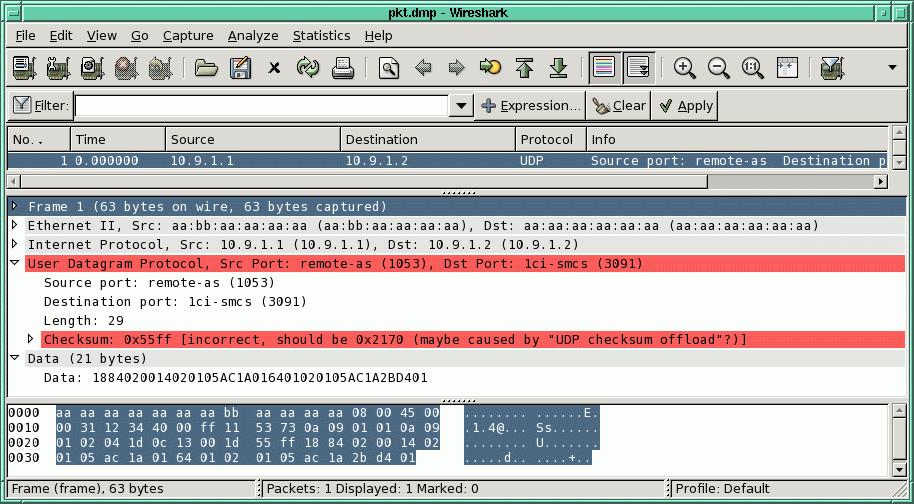
Figure 1. Not only does Wireshark tell you the checksum is wrong, it also tells you what it should be.
The UDP checksum is fairly easy to calculate, although it does involve constructing a pseudo-header containing the source IP, destination IP, UDP data length and the UDP protocol number. I was in a hurry and grabbed two different routines off the Net and found that both calculated incorrect checksums on a 64-bit platform. I finally had to rewrite one of the routines to generate correct checksums (see Resources for a download link). During development, you can use the checksum calculator URL in Resources to paste in a hex dump of your packet to verify your results.
When NF_QUEUE activates a callback, along with the requested data is a parameter containing the hook that invoked it. The possible values of the hook are defined in netfilter_ipv4.h as:
NF_IP_PRE_ROUTING 0 NF_IP_LOCAL_IN 1 NF_IP_FORWARD 2 NF_IP_LOCAL_OUT 3 NF_IP_POST_ROUTING 4
The value of the hook tells you which iptables chain was employed to direct the packet to the callback. You can use different iptables commands with different chains to change the behavior of your program by checking the value of the hook parameter. You might direct packets from your internal Net to the PREROUTING chain and packets from the external Net to the POSTROUTING chain, for example.
Understanding how iptables behave is essential in picking the right hook. The URL for faqs.org listed in Resources has one of the clearest explanations I have found. Figure 2, adapted from this reference, illustrates the packet path through iptables. The top label in the ovals is the table name while the lower label identifies the chain.
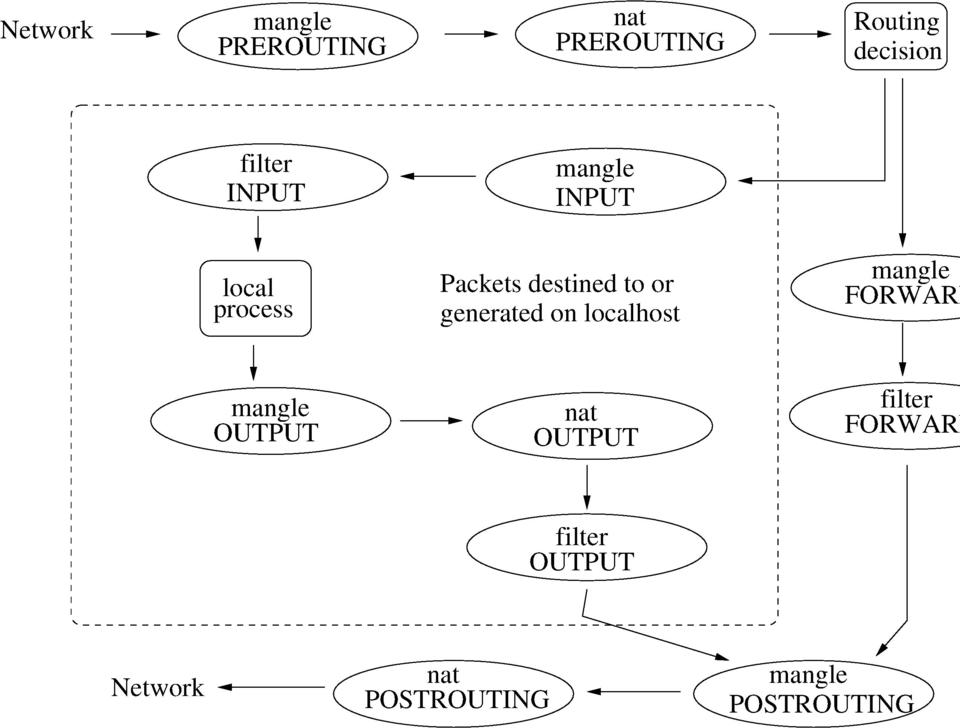
Figure 2. Packet flow through iptables tables and chains. Table names are in lowercase, chain names in uppercase.
In this case of mangling packets transiting the firewall, the LOCAL_IN and LOCAL_OUT hooks will not be used (they apply only to packets originating from or destined to the local host). That leaves three choices: PRE_ROUTING, FORWARD or POST_ROUTING (note that older kernels had more limited choices for the mangle table).
In this case where the IP header and actual source and destination addresses are not changed, any of the three choices would work. This might not be the case if you modify the source or destination addresses, which might affect subsequent routing decisions. If the destination address were changed to the local system, for example, you would be limited to the PREROUTING chain. If you want to modify the packet after all filtering has been done and intercept any locally generated packets as well, you would use the POSTROUTING chain. The FORWARD chain is useful for packets transiting the system.
At this point, you have a kernel with NF_QUEUE enabled, the nfqueue and nfnetlink libraries are installed, you have a packet sniffer ready to go, and your program is compiled and ready to test. How do you connect it to iptables?
The iptables target QUEUE will send any matching packets to a program that has registered itself for that queue, which defaults to Queue 0. An optional --queue-num parameter may be used to specify a nondefault queue. It is also possible to use a --queue-balance parameter with recent kernels that specifies a range of queues. This allows multiple instances of a userspace program on multicore architectures to improve throughput. If no program has registered itself for the queue, the QUEUE target is equivalent to DROP.
iptables has four built-in tables: filter, nat, mangle and raw. Each table supports different chains (Figure 2). The filter table, which is the default for the iptables command, is useful if your program is making an accept or deny decision on the packet, thus allowing firewall filtering based on content. The nat table is used for address translation, and the raw table, a recent addition, is used only for setting marks on packets that should not be handled by the conntrack system. The table to use when altering packets is, as the name implies, the mangle table. Listing 3 illustrates a few iptables commands that will set up NF_QUEUE forwarding for UDP packets destined for port 1331. In practice, this can become more complicated if you limit the source and destination addresses using additional iptables commands or include other selection criteria.
The NF_QUEUE application must run as root, at least when setting up the queue. Otherwise, you will get a -1 return from the unbind or bind calls.
In my case, the print server generated a ready supply of keep-alive packets, so I had no need of a packet generator. In the general case, you will need some way of generating test packets to verify that your system is operating correctly. A plethora of packet generators are available. One example is PackETH, which is a GUI-based packet generator that is quite easy to use, although still a little unfinished.
Another necessary requirement is the ability to capture packets both before and after processing to verify the output packet is correct. This can be easily done using tcpdump or Wireshark to view packets on the input and output interfaces of the test system. Wireshark may be used directly if you have X libraries available on the test system. In my case, since I was running the packets through a production system, I used tcpdump and then viewed the packet dump files offline with Wireshark.
The project turned out to be very successful. Fixing the keep-alive packets as they traversed the firewall resolved the problem without requiring any configuration changes on either endpoint. It was a completely transparent solution and my client was very happy with the result.
After being in place for a while, a crisis ensued when the remote system IP was changed. The printers stopped, because the remote IP was hard-configured into the print servers, and local personnel were unavailable to reconfigure them. With the addition of a DNAT firewall rule and a tweak to the protocol dæmon to fix the server address within the packet (all done remotely), the printers came back on-line in time to run payroll.
TCP protocols also can be fixed using this approach. Because TCP is a connection-oriented protocol rather than a datagram, the program will need to keep some state information as it processes the data stream. This is a little more complicated than a UDP protocol, but not unreasonable in practice.
I've posted a small sample NF_QUEUE packet sniffer on my Web site containing complete build and execution directions. It's fairly basic, but it allows you to get a hex dump of UDP or TCP streams determined by iptables rules and can serve as a basic framework if you're building an NF_QUEUE handler.
