
Learn how to integrate applications with an elegant and agile platform that is quick to adapt to ever-faster business changes. This how-to introduces the methodology and includes an integration example of a treasury.gov's financial API with two external apps.
Zato is a Python-based platform for integrating applications and exposing back-end services to front-end clients (https://zato.io/docs/index.html). It's an ESB (Enterprise Service Bus) and an application server focused on data integrations. The platform doesn't enforce any limits on architectural style for designing systems and can be used for SOA (Service Oriented Architecture), REST (Representational State Transfer) and for building systems of systems running in-house or in the cloud.
At its current version of 1.1 (at the time of this writing), Zato supports HTTP, JSON, SOAP, SQL, AMQP, JMS WebSphere MQ, ZeroMQ, Redis NoSQL and FTP. It includes a browser-based GUI, CLI, API, security, statistics, job scheduler, HAProxy-based load balancer and hot-deployment. Each piece is extensively documented from the viewpoint of several audiences: architects, admins and programmers.
Zato servers are built on top of gevent and gunicorn frameworks that are responsible for handling incoming traffic using asynchronous notification libraries, such as libevent or libev, but all of that is hidden from programmers' views so they can focus on their job only.
Servers always are part of a cluster and run identical copies of services deployed. There is no limit on how many servers a single cluster can contain.
Each cluster keeps its configuration in Redis and an SQL database. The former is used for statistics or data that is frequently updated and mostly read-only. The latter is where the more static configuration shared between servers is kept.
Users access Zato through its Web-based GUI (https://zato.io/docs/web-admin/intro.html), the command line (https://zato.io/docs/admin/cli/index.html) or API (https://zato.io/docs/public-api/intro.html).
Zato promotes loose coupling, reusability of components and hot-deployment. The high-level goal is to make it trivial to access or expose any sort of information. Common integration techniques and needs should be, at most, a couple clicks away, removing the need to reimplement the same steps constantly, slightly differently in each integration effort.
Everything in Zato is about minimizing the interference of components on each other, and server-side objects you create can be updated easily, reconfigured on fly or reused in other contexts without influencing any other.
This article guides you through the process of exposing complex XML data to three clients using JSON, a simpler form of XML and SOAP, all from a single code base in an elegant and Pythonic way that doesn't require you to think about the particularities of any format or transport.
To speed up the process of retrieving information by clients, back-end data will be cached in Redis and updated periodically by a job-scheduled service.
The data provider used will be US Department of the Treasury's real long-term interest rates (www.treasury.gov/resource-center/data-chart-center/interest-rates/Pages/TextView.aspx?data=reallongtermrate). Clients will be generic HTTP-based ones invoked through curl, although in practice, any HTTP client would do.
The goal is to make it easy and efficient for external client applications to access long-term US rates information. To that end, you'll make use of several features of Zato:
Scheduler will be employed to invoke a service to download the XML offered by treasury.gov and parse interesting data out of it.
Redis will be used as a cache to store the results of parsing the XML.
Zato's SimpleIO (SIO, https://zato.io/docs/progguide/sio.html) will allow you to expose the same set of information to more than one client, each using a different message format, without any code changes or server restarts.
Zato encourages the division of each business process into a set of IRA services (https://zato.io/docs/intro/esb-soa.html)—that is, each service exposed to users should be:
Interesting: services should provide a real value that makes potential users pause for a moment and, at least, contemplate using the service in their own applications for their own benefit.
Reusable: making services modular will allow you to make use of them in circumstances yet unforeseen—to build new, and possibly unexpected, solutions on top of lower-level ones.
Atomic: a service should have a well defined goal, indivisible from the viewpoint of a service's users, and preferably no functionality should overlap between services.
The IRA approach closely follows the UNIX philosophy of “do one thing and do it well” as well as the KISS principle that is well known and followed in many areas of engineering.
When you design an IRA service, it is almost exactly like defining APIs between the components of a standalone application. The difference is that services connect several applications running in a distributed environment. Once you take that into account, the mental process is identical.
Anyone who already has created an interesting interface of any sort in a single-noded application written in any programming language will feel right like home when dealing with IRA services.
From Zato's viewpoint, there is no difference in whether a service corresponds to an S in SOA or an R in REST; however, throughout this article, I'm using the the former approach.
The first thing you need is to diagram the integration process, pull out the services that will be implemented and document their purpose. If you need a hand with it, Zato offers its own API's documentation as an example of how a service should be documented (see https://zato.io/docs/progguide/documenting.html and https://zato.io/docs/public-api/intro.html):
Zato's scheduler is configured to invoke a service (update-cache) refreshing the cache once in an hour.
update-cache, by default, fetches the XML for the current month, but it can be configured to grab data for any date. This allows for reuse of the service in other contexts.
Client applications use either JSON or simple XML to request long-term rates (get-rate), and responses are produced based on data cached in Redis, making them super-fast. A single SIO Zato service can produce responses in JSON, XML or SOAP. Indeed, the same service can be exposed independently in completely different channels, such as HTTP or AMQP, each using different security definitions and not interrupting the message flow of other channels.
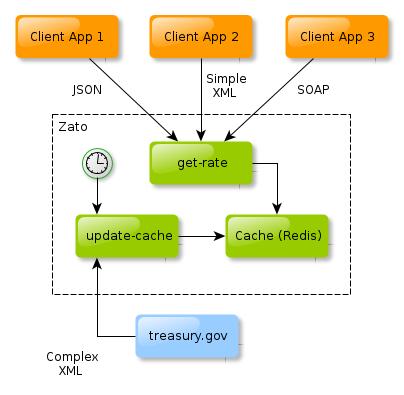
Figure 1. Overall Business Process
The full code for both services is available as a gist on GitHub, and only the most interesting parts are discussed (https://gist.github.com/dsuch/6440366).
linuxjournal.update-cache
Steps the service performs are:
Connect to treasury.gov.
Download the big XML.
Find interesting elements containing the business data.
Store it all in Redis cache.
Key fragments of the service are presented below.
When using Zato services, you are never required to hard-code network addresses. A service shields such information and uses human-defined names, such as “treasury.gov”; during runtime, these resolve into a set of concrete connection parameters. This works for HTTP and any other protocol supported by Zato. You also can update a connection definition on the fly without touching the code of the service and without any restarts:
1 # Fetch connection by its name
2 out = self.outgoing.plain_http.get('treasury.gov')
3
4 # Build a query string the backend data source expects
5 query_string = {
6 '$filter':'month(QUOTE_DATE) eq {} and year(QUOTE_DATE) eq
{}'.format(month, year)
7 }
8
9 # Invoke the backend with query string, fetch
# the response as a UTF-8 string
10 # and turn it into an XML object
11 response = out.conn.get(self.cid, query_string)
lxml (lxml.de) is a very good Python library for XML processing and is used in the example to issue XPath queries against the complex document (data.treasury.gov/feed.svc/DailyTreasuryRealLongTermRateAverageData?$filter=month%28QUOTE_DATE%29%20eq%208%20and%20year%28QUOTE_DATE%29%20eq%202013) returned:
1 xml = etree.fromstring(response)
2
3 # Look up all XML elements needed (date and rate) using XPath
4 elements = xml.xpath('//m:properties/d:*/text()',
↪namespaces=NAMESPACES)
For each element returned by the back-end service, you create an entry in the Redis cache in the format specified by REDIS_KEY_PATTERN—for instance, linuxjournal:rates:2013:09:03 with a value of 1.22:
1 for date, rate in elements:
2
3 # Create a date object out of string
4 date = parse(date)
5
6 # Build a key for Redis and store the data under it
7 key = REDIS_KEY_PATTERN.format(
8 date.year, str(date.month).zfill(2),
↪str(date.day).zfill(2))
9 self.kvdb.conn.set(key, rate)
10
12 # Leave a trace of our activity
13 self.logger.info('Key %s set to %s', key, rate)
linuxjournal.get-rate
Now that a service for updating the cache is ready, the one to return the data is so simple yet powerful that it can be reproduced in its entirety:
1 class GetRate(Service):
2 """ Returns the real long-term rate for a given date
3 (defaults to today if no date is given).
4 """
5 class SimpleIO:
6 input_optional = ('year', 'month', 'day')
7 output_optional = ('rate',)
8
9 def handle(self):
10 # Get date needed either from input or current day
11 year, month, day = get_date(self.request.input)
12
13 # Build the key the data is cached under
14 key = REDIS_KEY_PATTERN.format(year, month, day)
15
16 # Assign the result from cache directly to response
17 self.response.payload.rate = self.kvdb.conn.get(key)
A couple points to note:
SimpleIO was used—this is a declarative syntax for expressing simple documents that can be serialized to JSON or XML in the current Zato version, with more to come in future releases.
Nowhere in the service did you have to mention JSON, XML or even HTTP at all. It's all working on a high level of Python objects without specifying any output format or transport method.
This is the Zato way. It promotes reusability, which is valuable because a generic and interesting service, such as returning interest rates, is bound to be desirable in situations that cannot be predicted.
As an author of a service, you are not forced into committing to a particular format. Those are configuration details that can be taken care of through a variety of means, including a GUI that Zato provides. A single service can be exposed simultaneously through multiple access channels each using a different data format, security definition or rate limit independently of any other.
There are several ways to install a service:
Hot-deployment from the command line.
Hot-deployment from the browser.
Adding it to services-sources.txt—you can specify a path to a single module, to a Python package or a Python-dotted name by which to import it.
Let's hot-deploy what you have so far from the command line, assuming a Zato server is installed in /opt/zato/server1. You can do this using the cp command:
$ cp linuxjournal.py /opt/zato/server1/pickup-dir $
Now in the server log:
INFO - zato.hot-deploy.create:22 - Creating tar archive INFO - zato.hot-deploy.create:22 - Uploaded package id:[21], ↪payload_name:[linuxjournal.py]
Here's what just happened:
The server to be deployed was stored in an SQL database, and each server from a cluster was notified of the deployment of new code.
Each server made a backup of currently deployed services and stored it in the filesystem (by default, there's a circular log of the last 100 backups kept).
Each server imported the service and made it available for use.
All those changes were introduced throughout the whole cluster with no restarts and no reconfiguration.
Zato's Web admin is a GUI that can be used to create server objects that services need quickly, check runtime statistics or gather information needed for debugging purposes.
The Web admin is merely a client (https://zato.io/docs/progguide/clients/python.html) of Zato's own API, so everything it does also can be achieved from the command line or by user-created clients making API calls.
On top of that, server-side objects can be managed “en masse” (https://zato.io/docs/admin/guide/enmasse.html) using a JSON-based configuration that can be kept in a config repository for versioning and diffing. This allows for interesting workflows, such as creating a base configuration on a development environment and exporting it to test environments where the new configuration can be merged into an existing one, and later on, all that can be exported to production.
Figures 2–6 show the following configs:
Scheduler's job to invoke the service updating the cache.
Outgoing HTTP connection definitions for connecting to treasury.gov.
HTTP channels for each client—there is no requirement that each client be given a separate channel but doing so allows one to assign different security definitions to each channel without interfering with any other.
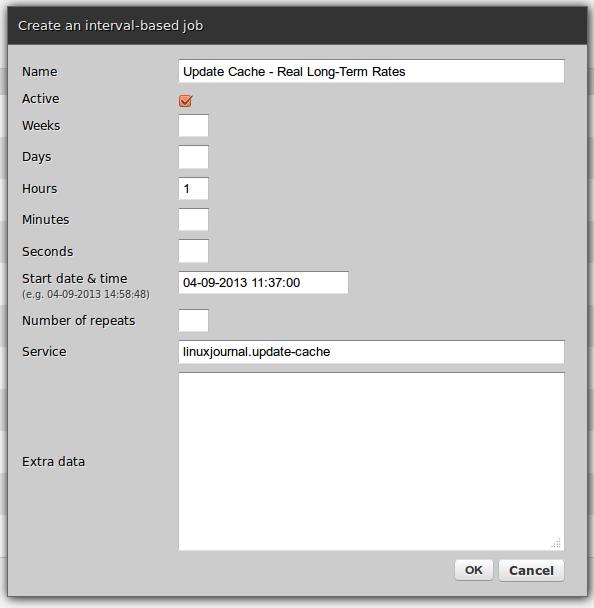
Figure 2. Scheduler Job Creation Form
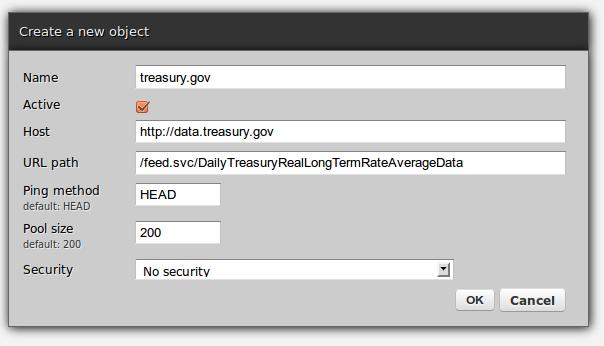
Figure 3. Outgoing HTTP Connection Creation Form
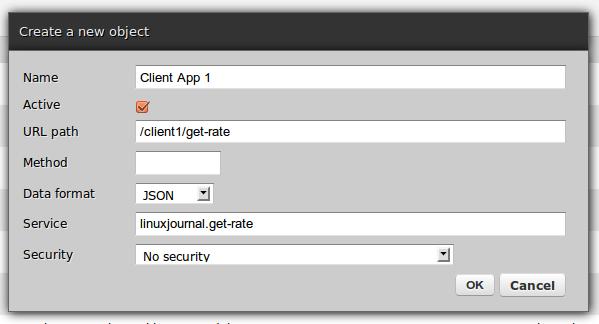
Figure 4. JSON Channel Creation Form
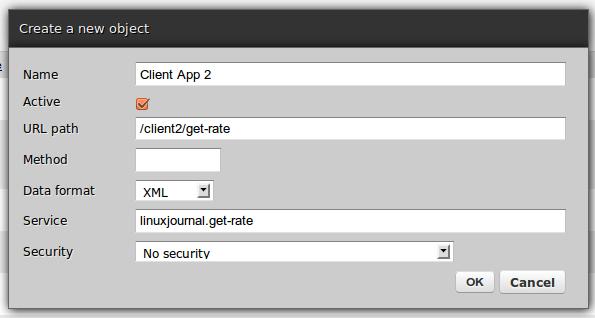
Figure 5. Plain XML Channel Creation Form
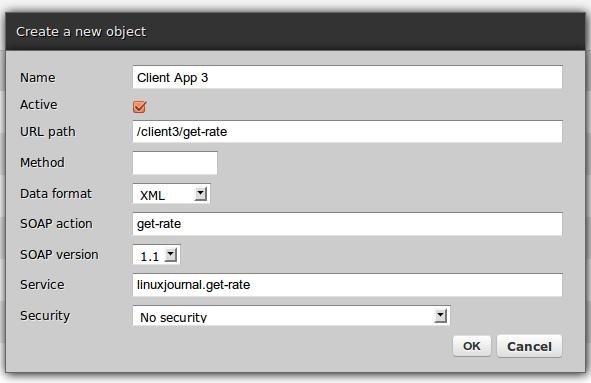
Figure 6. SOAP Channel Creation Form
update-cache will be invoked by the scheduler, but Zato's CLI offers the means to invoke any service from the command line, even if it's not mounted on any channel, like this:
$ zato service invoke /opt/zato/server1 linuxjournal.update-cache
↪--payload '{}'
(None)
$
There was no output, because the service doesn't produce any. However, when you check the logs you notice:
INFO - Key linuxjournal:rates:2013:09:03 set to 1.22
Now you can invoke get-rate from the command line using curl with JSON, XML and SOAP. The very same service exposed through three independent channels will produce output in three formats, as shown below (output slightly reformatted for clarity).
Output 1:
$ curl localhost:17010/client1/get-rate -d
↪'{"year":"2013","month":"09","day":"03"}'
↪{"response": {"rate": "1.22"}}
$
Output 2:
$ curl localhost:17010/client2/get-rate -d ' <request><year>2013</year><month>09</month><day>03</day></request>' <response> <zato_env> <cid>K295602460207582970321705053471448424629</cid> <result>ZATO_OK</result> </zato_env> <item> <rate>1.22</rate> </item> </response> $
Output 3:
$ curl localhost:17010/client3/get-rate \
-H "SOAPAction:get-rates" -d '
<soapenv:Envelope xmlns:soapenv=
↪"http://schemas.xmlsoap.org/soap/envelope/"
>
<soapenv:Body>
<z:request>
<z:year>2013</z:year>
<z:month>09</z:month>
<z:day>03</z:day>
</z:request>
</soapenv:Body>
</soapenv:Envelope>'
<?xml version='1.0' encoding='UTF-8'?>
<soap:Envelope
↪
↪xmlns="https://zato.io/ns/20130518">
<soap:Body>
<response>
<zato_env>
<cid>K175546649891418529601921746996004574051</cid>
<result>ZATO_OK</result>
</zato_env>
<item>
<rate>1.22</rate>
</item>
</response>
</soap:Body>
</soap:Envelope>
$
IRA (Interesting, Reusable, Atomic) is the key you should always keep in mind when designing services that are to be successful.
Both the services presented in the article meet the following criteria:
I: focus on providing data interesting to multiple parties.
R: can take part in many processes and be accessed through more than one method.
A: focus on one job only and do it well.
In this vein, Zato makes it easy for you to expose services over many channels and to incorporate them into higher-level integration scenarios, thereby increasing their overall attractiveness (I in IRA) to potential client applications.
It may be helpful to think of a few ways not to design services:
Anti-I: update-cache could be turned into two smaller services. One would fetch data and store it in an SQL database; the other would grab it from SQL and put it into Redis. Even if such a design could be defended by some rationale, neither of the pair of services would be interesting for external applications. A third service wrapping these two should be created and exposed to client apps, in the case of it being necessary for other systems to update the cache. In other words, let's keep the implementation details inside without exposing them to the whole world.
Anti-R: hard-coding nontrivial parameters is almost always a poor idea. The result being that a service cannot be driven by external systems invoking it with a set of arguments. For instance, creating a service that is limited to a specific year only ensures its limited use outside the original project.
Anti-A: returning a list of previous queries in response to a request may be a need of one particular client application, but contrary to the needs of another. In cases when a composite service becomes necessary, it should not be obliged upon each and every client.
Designing IRA services is like designing a good programming interface that will be released as an open-source library and used in places that can't be predicted initially.
Zato it not only about IRA but also about codifying common admin and programming tasks that are of a practical nature:
Each config file is versioned automatically (https://zato.io/docs/admin/guide/install-config/overview.html#config-files-are-versioned) and kept in a local bzr repository (bazaar-vcs.org), so it's always possible to revert to a safe state. This is completely transparent and needs no configuration nor management.
A frequent requirement before integration projects are started, particularly if certain services already are available on the platform, is to provide usage examples in the form of message requests and responses. Zato lets you specify that one-in-n invocations of a service be stored for a later use, precisely so that such requirements can be fulfilled by admins quickly.
Two popular questions asked regarding production are: 1) What are my slowest services? and 2) Which services are most commonly used? To answer these, Zato provides statistics (https://zato.io/docs/stats/guide.html) that can be accessed via Web admin, CLI or API. Data can be compared over arbitrary periods or exported to CSV as well.
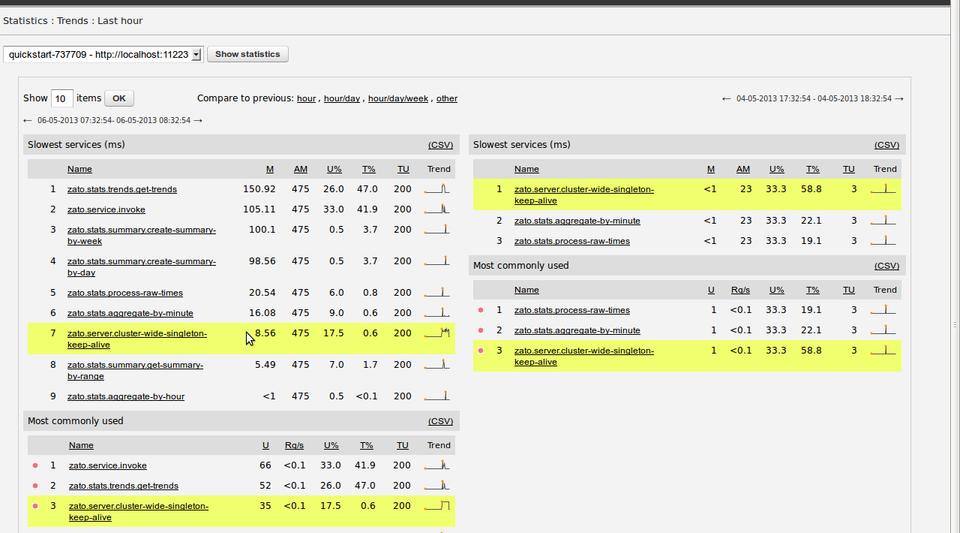
Figure 7. Sample Statistics
Despite being a relatively new project, Zato is already a lightweight yet complete solution that can be used in many integration and back-end scenarios. Regardless of the project's underlying integration principles, such as SOA or REST, the platform can be used to deliver scalable architectures that are easy to use, maintain and extend.
