
Obsession with Big Data has gotten out of hand. Here's how.
I'm writing this on September 11, 2014, 13 years after the famous day when terrorist hijackers flew planes into buildings, killing thousands and changing the world for the worse. I also spent the last three days getting hang time with Bill Binney (en.wikipedia.org/wiki/William_Binney_%28U.S._intelligence_official%29), who says the 9/11 attacks could have been prevented. Bill makes this claim because he led an NSA project designed to find clues and put them together. It was called ThinThread (en.wikipedia.org/wiki/ThinThread). The NSA discontinued ThinThread three weeks before the attacks, opting eventually to go with another project called Trailblazer (en.wikipedia.org/wiki/Trailblazer_Project#Background). Bill says ThinThread would have cost $9 million to deploy. Trailblazer ended up costing hundreds of millions of dollars and sucked (https://en.wikipedia.org/wiki/Trailblazer_Project#Whistleblowing).
Like its successors, such as PRISM (en.wikipedia.org/wiki/PRISM_%28surveillance_program%29), Trailblazer was all about collecting everything it could from everywhere it could. “At least 80% of all audio calls, not just metadata”, Bill tells us (www.theguardian.com/commentisfree/2014/jul/11/the-ultimate-goal-of-the-nsa-is-total-population-control), “are recorded and stored in the US. The NSA lies about what it stores.” At the very least, revelations by Bill and other sources (such as Edward Snowden and Chelsea Manning) make it clear that the Fourth Amendment (https://en.wikipedia.org/wiki/Probable_cause) no longer protects American citizens from unreasonable searches and seizures. In the era of Big Data everywhere, it's reasonable to grab all of it.
Surveillance also has a chilling effect on what we say. Talk about ________ and the Feds might flag you as a ________. Among other things, Edward Snowden and Glenn Greenwald (https://en.wikipedia.org/wiki/Glenn_Greenwald) revealed that Linux Journal has been placed (www.linuxjournal.com/content/nsa-linux-journal-extremist-forum-and-its-readers-get-flagged-extra-surveillance) under suspicion (www.linuxjournal.com/content/stuff-matters) by an NSA program called XKeyscore (https://en.wikipedia.org/wiki/XKeyscore). As a reader, you're probably already on some NSA list. I'd say “be careful”, but it's too late.
The differences between ThinThread and what the NSA now does are ones of method and discretion. ThinThread's method was to watch for suspect communications in real time on international data pipes, and to augment or automate the work of human analysts whose job was finding bad actors doing bad things while also protecting people's rights to privacy. The scope of data collected by the NSA since then has veered toward the absolute. In sworn testimony (https://publicintelligence.net/binney-nsa-declaration), in support of the Electronic Frontier Foundation's suit (https://www.eff.org) against the NSA (Jewel v. NSA, https://www.eff.org/cases/jewel), Bill said this about the size of the agency's data processing and storage plans:
The sheer size of that capacity indicates that the NSA is not filtering personal electronic communications such as email before storage but is, in fact, storing all that they are collecting. The capacity of NSA's planned infrastructure far exceeds the capacity necessary for the storage of discreet, targeted communications or even for the storage of the routing information from all electronic communications. The capacity of NSA's planned infrastructure is consistent, as a mathematical matter, with seizing both the routing information and the contents of all electronic communications.
So the NSA has been into Big Data since at least a decade before the term came into common use (Figure 1).
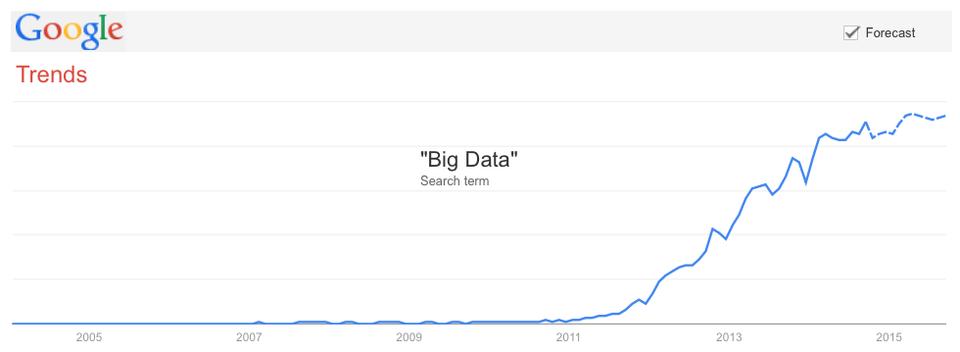
Figure 1. Big Data Trends (Source: Google Trends, September 11, 2014)
The year 2011 was, not coincidentally, when McKinsey (www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation) and Big Tech Vendors began driving the demand for Big Data solutions with aggressive marketing of the meme.
The pitch went like this: the world is turning into data, in quantities exploding at an exponential rate. It is essential to get in front of that wave and take advantage of it, or to risk drowning in it. With Big Data, you can “unlock value”, “gain insights”, “improve performance”, “improve research”, “segment marketing and services”, “improve decision-making”. And, of course, “save lives”.
Lots of the pitching talked about science and health, where the advantages of more data always have been obvious. On the science side, that imperative surely helped sway the NSA toward Trailblazer and PRISM and away from ThinThread, which was about doing more with less. But now the Big Data meme is hitting a plateau, as you can see in the graph in Figure 1. There is also a backlash against it (www.economist.com/blogs/economist-explains/2014/04/economist-explains-10), given the degree to which we also are surveilled by marketers. In “How Big Data is Like Big Tobacco—Part 1” (www.forbes.com/sites/sap/2014/08/26/how-big-data-is-like-big-tobacco-part-1), Tim Walsh, SAP's Global Vice President, Customer Engagement and Commerce, writes this for Forbes:
Big Data is running down a similar path. Deception? Check. Users are only now realizing on a broad basis that many companies are watching, recording and manipulating them constantly. It's not just what you buy. That's primitive stuff. Every site you visit, everything you “like”, every person you interact with online, every word you type in “free” email or chat service, every picture you take (yes, including those you thought were instantly deleted), every physical place you go with that mobile device, the middle of the night drunken surfing—yes, yes and yes.
And it's not just online activity. Remember, companies have been at this for decades. All the publicly available information is now being tied together with your digital life to deliver an incredibly intimate picture of who you are and what you are likely to want, spend, do. Just leave it to Big Data to make the predictions. (What's the best way to make an accurate prediction? Manipulate the outcome!)
Anyone not living in a gun shack has a profile that runs to literally thousands of data elements. You don't need to be a Facebook addict to have a file 6 inches thick that carries your purchase history, voter registration, residence, major credit events, network of friends, etc. That list is growing exponentially because now the cottage data industry has become Big Data, with limitless resources. Increasingly, Big Data isn't even bothering to ask user consent for any of this. As they say: “Not paying for the product? You are the product.” The government (US and EU) is taking notice and taking action. Users feel deceived and governments have picked up the scent.
In “Eight (No, Nine!) Problems With Big Data” in The New York Times (www.nytimes.com/2014/04/07/opinion/eight-no-nine-problems-with-big-data.html?_r=1), Gary Marcus and Ernest Davis lay out more issues:
“...although big data is very good at detecting correlations, especially subtle correlations that an analysis of smaller data sets might miss, it never tells us which correlations are meaningful.”
“...big data can work well as an adjunct to scientific inquiry but rarely succeeds as a wholesale replacement.”
“...many tools that are based on big data can be easily gamed.”
“...even when the results of a big data analysis aren't intentionally gamed, they often turn out to be less robust than they initially seem.”
“...the echo-chamber effect, which also stems from the fact that much of big data comes from the web.”
“...the risk of too many correlations.”
“...big data is prone to giving scientific-sounding solutions to hopelessly imprecise questions.”
“...big data is at its best when analyzing things that are extremely common, but often falls short when analyzing things that are less common.”
“...the hype.”
Another problem: it tends not to work. In “Where Big Data Fails...and Why” (blog.primal.com/where-big-data-failsand-why), Peter Sweeney explains how increasing the size of the data and complexity of the schema (expressiveness and diversity of knowledge) results in poor price/performance toward achieving marketing's holy grail of “personalized media”. His bottom line: “These analytical approaches inevitably break down when confronted with the small data problems of our increasingly complex and fragmented domains of knowledge.”
There is nothing more complex and fragmented than a human being—especially if you're a robot who wants to get personal with one. Each of us not only differs from everybody else, but from ourselves, from one moment to the next. So, while big data works well for making generalizations about populations of people, at the individual level it tends to fail. We are also barely revealed by the junk that marketing surveillance systems pick up when they follow us around with cookies, tracking beacons and other intrusive and unwelcome things. Here's how Peter Sweeney lays it out, verbatim:
“The individual interests and preferences of end-users are only partially represented in the media.”
“Individual user profiles and activity do not provide sufficient data for modeling specific interests.”
“Market participants do not produce sufficient data about individual products and services.”
“Media and messaging are only a shadow of the interests of end-users; direct evidence of end-user interests is relatively sparse.”
This is why the popularity of ad blockers (most of which also block tracking) are high, and growing rapidly. This is the clear message of “Adblocking Goes Mainstream” (downloads.pagefair.com/reports/adblocking_goes_mainstream_2014_report.pdf), published on September 9, 2014, by PageFair (https://pagefair.com) and Adobe. Here are some results, verbatim:
“In Q2 2014 there were approximately 144 million monthly active adblock users globally (4.9% of all internet users); a number which has increased 69% over the previous 12 months.”
“Google Chrome is bringing ad blocking to the masses and seeing the largest increase of adblockers, up by 96% to approximately 86 million monthly active users between Q2 2013 and Q2 2014.”
“Share of ads blocked by 'end-user installed' browsers is 4.7x higher than by 'pre-installed' browsers.”
“Adblock adoption is happening all over the world—Poland, Sweden, Denmark, and Greece are leading the way with an average of 24% of their online populations using adblocking software in Q2 2014.”
“Countries like Japan, Spain, China and Italy are catching up; with their percentage of online populations that use adblock plug-ins growing as much as 134% over the last 12 months.”
This is the market talking. So is what's shown in Figure 2.
Figure 2. Privacy Extensions
Figure 2 shows all the extensions for ad and tracking blocking I've added in Firefox.
I may be an extreme case (my interest in this stuff is professional, so I check everything out), but few of us like being spied on, or what being spied on does to us—whether it's biting our tongues or leading us to reject the very thing that pays for the free goods we enjoy on the Web.
There are legal and policy solutions to the problem of government surveillance. On the legal front we have the EFF and others, filing suits against the government (https://www.eff.org/nsa-spying) and making clear arguments on the open Web. On the policy front we have our votes, plus the combined efforts of the EFF, StandAgasinstSpying (https://standagainstspying.org), DemandProgress (demandprogress.org/campaigns), Sunlight Foundation (sunlightfoundation.com) and others.
On the business side, we have the clear message that ad and tracking blocking sends, plus the high cost of Big Data-based surveillance—which at some point will start making an ROI argument against itself. My own favorite argument against surveillance-based advertising is the one for old-fashioned brand advertising. This is what Don Marti (our former Editor-in-Chief, zgp.org/%7Edmarti) has been doing lately. For example (zgp.org/%7Edmarti/business/monkey-badger/#.VBoCi0u0bwI):
Your choice to protect your privacy by blocking those creepy targeted ads that everyone hates is not a selfish one. You're helping to re-shape the economy. You're helping to move ad spending away from ads that target you, and have more negative externalities, and towards ads that are tied to content, and have more positive externalities.
The most positive externality, for us here at Linux Journal—and for journalism in general—is journalism itself. Brand advertising isn't personal. It's data-driven only so far as it needs to refine its aim toward populations. For example, people who dig Linux. Brand advertising supports editorial content in a nice clean way: by endorsing it and associating with it.
By endorsing journalism for exactly what it does, brand advertising is a great supporter. (It supports a lot of crap too, but that's beside the point here.) On the other hand, surveillance-driven personalized advertising supports replacing journalism with click-bait.
Don has a simple solution:
So let's re-introduce the Web to advertising, only this time, let's try it without the creepy stuff (zgp.org/targeted-advertising-considered-harmful/#what-next-solutions). Brand advertisers and web content people have a lot more in common than either one has with database marketing. There are a lot of great opportunities on the post-creepy web, but the first step is to get the right people talking.
So, if you advertise something Linux-y, call our sales department.
