
Second-generation Beowulf clusters offer single-process I/O space, thin slave nodes, GUI utilities and more for adaptability and manageability.
Imagine, for a moment, if you will, driving your car into a full-service gas station—a near anachronism—pulling up to the attendant and saying, “Fill'er up, check the oil and wipers, and...give me 20 more horsepower, would you?” The attendant, not phased by the request, looks at you and says, “Would you like four-wheel drive with that? I hear it might snow tonight.” You think for a moment and respond positively—four-wheel drive would be good to have.
If only automobiles, and Beowulf clusters, were so adaptable. Yet, the single most important distinguishing feature of Beowulf 2 technology is adaptability—the ability to add more computing power to meet changing needs. To understand and appreciate how Beowulf technology has become so adaptable, an understanding of Beowulf 1 is in order.
As we all know by now, the original concept for Beowulf clusters was conceived by Donald Becker while he was at NASA Goddard in 1994. The premise was that commodity computing parts could be used, in parallel, to produce an order of magnitude leap in computing price/performance for a certain class of problems. The proof of concept was the first Beowulf cluster, Wiglaf, which was operational in late 1994. Wiglaf was a 16-processor system with 66MHz Intel 80486 processors that were later replaced with 100MHz DX4s, achieving a sustained performance of 74Mflops/s (74 million floating-point operations per second). Three years later, Becker and the CESDIS (Center of Excellence in Space Data and Information Services) team won the prestigious Gordon Bell award. The award was given for a cluster of Pentium Pros that were assembled for SC'96 (the 1996 SuperComputing Conference) that achieved 2.1Gflops/s (2.1 billion floating-point operations per second). The software developed at Goddard was in wide use by then at many national labs and universities.
The first generation of Beowulf clusters had the following characteristics: commodity hardware, open-source operating systems such as Linux or FreeBSD and dedicated compute nodes residing on a private network. In addition, all of the nodes possessed a full operating system installation, and there was individual process space on each node.
These first-generation Beowulfs ran software to support a message-passing interface, either PVM (parallel virtual machine) or MPI (message-passing interface). Message-passing typically is how slave nodes in a high-performance computing (HPC) cluster environment exchange information.
Some common problems plagued the first-generation Beowulf clusters, largely because the system management tools to control the new clusters did not scale well because they were more platform- or operating-specific than the parallel programming software. After all, Beowulf is all about running high-performance parallel jobs, and far less attention went into writing robust, portable system administration code. The following types of problems hampered early Beowulfs:
Early Beowulfs were difficult to install. There was either the labor-intensive, install-each-node-manually method, which was error-prone and subject to typos, or the more sophisticated install-all-the-nodes-over-the-network method using PXE/TFTP/NFS/DHCP—clearly getting all one's acronyms properly configured and running all at once is a feat in itself.
Once installed, Beowulfs were hard to manage. If you think about a semi-large cluster with dozens or hundreds of nodes, what happens when the new Linux kernel comes out, like the 2.4 kernel optimized for SMP? To run a new kernel on a slave node, you have to install the kernel in the proper space and tell LILO (or your favorite boot loader) all about it, dozens or hundreds of times. To facilitate node updates the r commands, such as rsh and rcp, were employed. The r commands, however, require user account management accessibility on the slave nodes and open a plethora of security holes.
It was hard to adapt the cluster: adding new computing power in the form of more slave nodes required fervent prayers to the Norse gods. To add a node, you had to install the operating system, update all the configuration files (a lot of twisty little files, all alike), update the user space on the nodes and, of course, all the HPC code that had configuration requirements of its own—you do want PBS to know about the new node, don't you?.
It didn't look and feel like a computer; it felt like a lot of little independent nodes off doing their own thing, sometimes playing together nicely long enough to complete a parallel programming job.
In short, for all the progress made in harnessing the power of commodity hardware, there was still much work to be done in making Beowulf 1 an industrial-strength computing appliance. Over the last year or so, the Rocks and OSCAR clustering software distributions have developed into the epitome of Beowulf 1 implementations [see “The Beowulf State of Mind”, LJ May 2002, and “The OSCAR Revolution”, LJ June 2002]. But if Beowulf commodity computing was to become more sophisticated and simpler to use, it was going to require extreme Linux engineering. Enter Beowulf 2, the next generation of Beowulf.
The hallmark of second-generation Beowulf is that the most error-prone components have been eliminated, making the new design far simpler and more reliable than first-generation Beowulf. Scyld Computing Corporation, led by CTO Don Becker and some of the original NASA Beowulf staff, has succeeded in a breakthrough in Beowulf technology as significant as the original Beowulf itself was in 1994. The commodity aspects and message-passing software remain constant from Beowulf 1 to Beowulf 2. However, significant modifications have been made in node setup and process space distribution.
At the very heart of the second-generation Beowulf solution is BProc, short for Beowulf Distributed Process Space, which was developed by Erik Arjan Hendriks of Los Alamos National Lab. BProc consists of a set of kernel modifications and system calls that allows a process to be migrated from one node to another. The process migrates under the complete control of the application itself—the application explicitly decides when to move over to another node and initiates the process via an rfork system call. The process is migrated without its associated file handles, which makes the process lean and quick. Any required files are re-opened by the application itself on the destination node, giving complete control to the application process.
Of course, the ability to migrate a process from one node to another is meaningless without the ability to manage the remote process. BProc provides such a method by putting a “ghost process” in the master node's process table for each migrated process. These ghost processes require no memory on the master—they merely are placeholders that communicate signals and perform certain operations on behalf of the remote process. For example, through the ghost process on the master node, the remote process can receive signals, including SIGKILL and SIGSTOP, and fork child processes. Since the ghost processes appear in the process table of the master node, tools that display the status of processes work in the same familiar ways.
The elegant simplicity of BProc has far-reaching effects. The most obvious effect is the Beowulf cluster now appears to have a single-process space managed from the master node. This concept of a single, cluster-wide process space with centralized management is called single-system image or, sometimes, single-system illusion because the mechanism provides the illusion that the cluster is a single-compute resource. In addition, BProc does not require the r commands (rsh and rlogin) for process management because processes are managed directly from the master. Eliminating the r commands means there is no need for user account management on the slave nodes, thereby reducing a significant portion of the operating system on the slaves. In fact, to run BProc on a slave node, only a couple of dæmons are required to be present on the slave: bpslave and sendstats.
Scyld has completely leveraged BProc to provide an expandable cluster computing solution, eliminating everything from the slave nodes except what is absolutely required in order to run a BProc process. The result is an ultra-thin compute node that has only a small portion of Linux running—enough to run BProc. The power of BProc and the ultra-thin Scyld node, taken in conjunction, has great impact on the way the cluster is managed. There are two distinguishing features of the Scyld distribution and of Beowulf 2 clusters. First, the cluster can be expanded by simply adding new nodes. Because the nodes are ultra-thin, installation is a matter of booting the node with the Scyld kernel and making it a receptacle for BProc migrated processes. Second, version skew is eliminated. Version skew is what happens on clusters with fully installed slave nodes. Over time, because of nodes that are down during software updates, simple update failures or programmer doinking, the software on the nodes that is supposed to be in lockstep shifts out of phase, resulting in version skew. Since only the bare essentials are required on the nodes to run BProc, version skew is virtually eliminated.
Of course, having the ability to migrate processes to thin nodes is not a solution in itself. Scyld provides the rest of the solution as part of the special Scyld Beowulf distribution, which includes features such as:
BeoMPI: a message-passing library that meets the MPI standard, is derived from the MPICH (MPI Chameleon) Project from Argonne National Lab and is modified specifically for optimization with BProc.
BeoSetup: a GUI for creating BeoBoot floppy boot images for slave nodes.
Beofdisk: a utility for partitioning slave node hard drives.
BeoStatus: a GUI for monitoring the status of the cluster.
Let's take a look at how to use these tools while building a Scyld Beowulf cluster.
You can purchase the Scyld Beowulf Professional Edition (www.scyld.com) that comes with a bootable master node installation CD, documentation and one year of support. The Professional Edition is spectacular and supports many advanced cluster software tools such as the parallel virtual filesystem (PVFS). Alternatively, you can purchase a Scyld Basic Edition CD for $2.95 at Linux Central (www.linuxcentral.com). The Basic Edition is missing some of the features present in the Professional Edition and arrives without documentation or support. I've built clusters with both without any problems.
It's important that you construct your Beowulf similar to Figure 1, which illustrates the general Beowulf (1 and 2) layout. The master node has two network interfaces that straddle the public network and the private compute node LAN. Scyld Beowulf assumes you've configured the network so that eth0 on the master is the public network interface and eth1 is the interface to the private compute node network. To begin the installation, take your Scyld CD, put it in the master node's CD drive and power-cycle the machine.
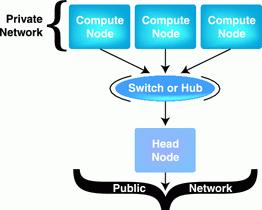
Figure 1. General Beowulf Layout
You'll discover that the Scyld Beowulf master node installation is almost identical to a Red Hat Linux installation. At the boot prompt, type install to trigger a master node installation. Allowing the boot prompt to time out will initiate a slave node installation by default.
Step through the simple installation procedure as you would for Red Hat Linux. For first-time cluster builders, we're going to recommend (and assume here) that you select a GNOME controller installation instead of a text-console-only installation. Choosing the GNOME installation will give you access to all the slick GUI Beo* tools integrated into the GNOME desktop environment that make building the rest of the cluster a snap.
After the typical configuration of eth0, you'll come upon the key difference with the Scyld installation: the configuration of eth1 on the master and the IP addresses of the compute nodes. The installation will prompt you for an IP address (like 192.168.1.1) for eth1 and an IP address range (such as, 192.168.1.2-192.168.x) for your compute nodes. Simple enough, but make sure you select an IP range large enough to give each of your compute nodes its own address.
Continue through the remaining installation steps, such as X configuration. For simplicity's sake, select the graphical login option. Wrap up the master node installation by creating a boot disk, removing the CD (and the boot disk) and rebooting the master node.
Log in to the master as root and the Scyld-customized GNOME desktop is fired up for you, including the BeoSetup and BeoStatus GUIs and a compute node quick install guide.
Initially, all compute nodes require a BeoBoot image to boot, either on a floppy or the Scyld CD. Rather than move the Scyld CD from node to node, I prefer to create several slave node boot images on floppies, one for each slave node. The BeoBoot images are created with the BeoSetup tool by clicking the Node Floppy button in BeoSetup. Insert a blank formatted floppy into the master's floppy drive; click OK to create the BeoBoot boot image and write it to the floppy. Repeat this for as many floppies as you like. Insert the boot floppies into the slave node floppy drives and turn on the power.
What happens next is pretty cool but is hidden from the user (unless you hook up a monitor to a slave node). Each slave node boots the BeoBoot image, autodetects network hardware, installs network drivers and then sends out RARP requests. These RARP requests are answered by the Beoserv dæmon on the master, which in turn sends out an IP address, kernel and RAM disk to each slave node. This process, where the slave node bootstraps itself with a minimal kernel on a floppy disk, which is then replaced with a final, more sophisticated kernel from the master, is dubbed the Two Kernel Monte. The slave node then reboots itself with the final kernel and repeats the hardware detection and RARP steps. Then the slave node contacts the master to become integrated into BProc.
During the kernel monte business, slave node Ethernet MAC addresses will appear in the Unknown Addresses window in BeoSetup on the master. You can integrate them into your cluster by highlighting the addresses, dragging them into the central Configured Nodes column and clicking the Apply button. Once the master finishes integrating the slave nodes into BProc the nodes will be labeled “up”. Node status will appear in BeoStatus as well.
You can partition the slave node hard drives with the default configuration in /etc/beowulf/fdisk:
beofdisk -d beofdisk -w
The -d option tells beofdisk to use the default configuration in /etc/beowulf/fdisk and the -w option writes the tables out to all the slave nodes. You then need to edit /etc/beowulf/fstab to map the swap and / filesystems to the new partitions. Simply comment out the $RAMDISK line in /etc/beowulf/fstab that was used to mount a / filesystem in the absence of a partitioned hard drive, and edit the next two lines to map the swap and / filesystems to /dev/hda2 and /dev/hda3 (/dev/hda1 is reserved as a bootable partition). If you would like to boot from the hard drive, you can write the Beoboot floppy image to the bootable partition like this:
beoboot-install -a /dev/hda1You'll have to add a line in /etc/beowulf/fstab after doing this:
/dev/hda1 beoboot ext2 defaults 0 0Reboot all slave nodes for the partition table changes to take effect:
bpctl -S all -s rebootIt doesn't get much easier than that. Unlike Beowulf 1, building a Scyld Beowulf requires a full Linux installation on only the master node. Nothing is written out to permanent storage on the slave nodes during their installation, making them ultra-thin, easily maintained and quick to reboot.
To test your cluster you can run the high-performance Linpack benchmark included with the distribution from the command line: linpack.
For a little flashier demonstration, launch a visual Mandelbrot set with the included mpi-madel application. Starting mpi-mandel on five nodes from the command line would look like:
NP=5 mpi-mandel
Collectively, the single-process ID space, the ability to migrate quickly processes under control of the application, thin slave nodes and the GUI utilities for building and monitoring a Scyld cluster, provide a cluster solution that distinguishes itself from Beowulf 1 by its completeness, adaptability and manageability. So, the answer is yes, you really can add more horsepower to that cluster.
The authors would like to thank Donald Becker, Tom Quinn and Rick Niles of Scyld Computing Corporation and Erik Arjan Hendriks of Los Alamos National Lab for patiently answering all our questions related to second-generation Beowulf.
Glen Otero has a PhD in Immunology and Microbiology and runs a consulting company called Linux Prophet in San Diego, California.
