
The four basic performance-tuning steps to improve an existing application's performance.
A fellow developer and I have been working on a data collection application primarily written in Perl. The application retrieves measurement files from a directory, parses the files, performs some statistical calculations and writes the results to a database. We needed to improve the application's performance so that it would handle a considerable load while being used in production.
This paper introduces four performance-tuning steps: identification, benchmarking, refactoring and verification. These steps are applied to an existing application to improve its performance. A function is identified as being a possible performance problem, and a baseline benchmark of that function is established. Several optimizations are applied iteratively to the function, and the performance improvements are compared against the baseline.
The first task at hand in improving the performance of an application is to determine what parts of the application are not performing as well as they should. In this case I used two techniques to identify potential performance problems, code review and profiling.
A performance code review is the process of reading through the code looking for suspicious operations. The advantage of code review is the reviewer can observe the flow of data through the application. Understanding the flow of data through the application helps identify any control loops that can be eliminated. It also helps identify sections of code that should be further scrutinized with application profiling. I do not advise combining a performance code review with other types of code review, such as a code review for standards compliance.
Application profiling is the process of monitoring the execution of an application to determine where the most time is spent and how frequently operations are performed. In this case, I used a Perl package called Benchmark::Timer. This package provides functions that I use to mark the beginning and end of interesting sections of code. Each of these marked sections of code are identified by a label. When the program is run and a marked section is entered, the time taken within that marked section is recorded.
Adding profiling sections to an application is an intrusive technique; it changes the behavior of the code. In other words, it is possible for the profiling code to overshadow or obscure a performance problem. In the early stages of performance tuning, this may not be a problem because the magnitude of the performance problem will be significantly larger than the performance impact of the profiling code. However, as performance issues are eliminated, it is more likely that a subsequent performance issue will be harder to distinguish. Like many things, performance improvement is an iterative process.
In our case, profiling some sections of the code indicated that a considerable amount of time was being spent calculating statistics of data collected off the machine. I reviewed the code related to these statistics calculations and noticed that a function to calculate standard deviation, std_dev, was used frequently. The std_dev calculation caught my eye for two reasons. First, because calculating the standard deviation requires calculating the mean and the mean of the sum of squares for the entire measurement set, the na�e calculation for std_dev uses two loops when it could be done with one loop. Secondly, I noticed that the entire data array was being passed into the std_dev function on the stack rather than being passed as a reference. I thought these two items together might indicate a performance issue worth examining.
After identifying a function that could be improved, I proceeded to the next step, benchmarking the function. Benchmarking is the process of establishing a baseline measurement for comparison. Creating a benchmark is the only way to know whether a modification actually has improved the performance of something. All the benchmarks presented here are time-based. Fortunately, a Perl package called Benchmark was developed specifically for generating time-based benchmarks.
I copied the std_dev function (Listing 1) out of the application and into a test script. By moving the function to a test script, I could benchmark it without affecting the data collection application. In order to get a representative benchmark, I needed to duplicate the load that existed in the data collection application. After examining the data processed by the data collection application, I determined that a shuffled set of all the numbers between 0 and 999,999 would be adequate.
In order to yield a reliable benchmark, the std_dev function must be repeated several times. The more times the function is run, the more reliable or consistent the benchmark will be. The number of times to repeat the benchmark can be set specifically with the Perl Benchmark package. For example, run this benchmark 10,000 times. Alternatively, the package accepts a time duration, in which case the benchmark is repeated as many times as possible within the allotted time. All benchmarks shown in this article use an iteration parameter of 10 seconds. Calculating the standard deviation of 1,000,000 data elements for at least 10 seconds produced the result:
12 wallclock secs (10.57 usr + 0.02 sys
= 10.59 CPU) @ 0.28/s (n = 3)
This information indicates that the benchmark measurement took 12 seconds to run. The benchmark tool was able to execute the function 0.28 times per second or, taking the inverse, 3.5 seconds per iteration. The benchmark utility was able to execute the function only three times (n = 3) in the allotted 10 CPU seconds. Throughout this paper, results are measured using seconds per iteration (s/iter). The lower the number, the better the performance. For example, an instantaneous function call would take 0 s/iter, and a really bad function call would take 60 s/iter. Now that I have a baseline measurement of the std_dev performance, I can measure the effects of refactoring the function.
Although three samples are enough to identify issues with the std_dev calculation, a more in-depth performance analysis should have more samples.
After establishing the benchmark shown in Listing 1, I refined the std_dev algorithm in two iterations. The first refinement, called std_dev_ref, was to change the parameter passing from “pass by value” to “pass by reference” in both the std_dev function and the mean function that is called by std_dev. The resulting functions are shown in Listing 2. Theoretically, this will increase the performance of both functions by avoiding copying the entire contents of the data array onto the stack before the call to std_dev and the subsequent call to mean.
The second refinement, called std_dev_ref_sum, was to remove the mean function altogether. The mean and the mean of the sum of squares are combined into one loop through the entire data set. This refinement, shown in Listing 3, removes at least two iterations over the data. Table 1 contains a summary of the benchmark times.
As hoped, an incremental improvement between each of the refinements is shown in Table 1. Between the std_dev and std_dev_ref functions there is a 20% improvement, and between std_dev and std_dev_ref_sum functions there is a 158% improvement. This seems to confirm my expectation that pass by reference is faster than pass by value in Perl. Also, as expected, removing two loops through the data improved the performance of the std_dev_ref_sum function. After both of these refinements, the function can calculate the standard deviation of 1,000,000 items in 1.37 seconds. Although this is considerably better than the original, I still think there is room for improvement.
A number of open-source Perl packages are available. Hopefully, I could find a standard deviation calculation that was faster than my best attempt so far. I found and downloaded a statistics package from CPAN called Statistics::Descriptive. I created a function called std_dev_pm that used the Statistics::Descriptive package. The code for this function is shown in Listing 4.
Using this function, however, produced a result of 6.80 s/iter; 48% worse than the baseline std_dev function. This is not altogether unexpected considering that the Statistics::Descriptive package uses an object interface. Each calculation includes the overhead of constructing and destructing a Statistics::Descriptive::Sparse object. This is not to say that Statistics::Descriptive is a bad package. It contains a considerable number of statistical calculations written in Perl and is easy to use for calculations that don't have to be fast. However, for our specific case, speed is more important.
All languages have good and bad qualities. Perl, for example, is a good general-purpose language but is not the best for number-crunching calculations. With this in mind, I decided to rewrite the standard deviation function in C to see if it improved performance.
In the case of the data collection application, it would be counter-productive to rewrite the entire project in C. Quite a few specific Perl utilities make it the best language for most of the application. An alternative to rewriting the application is to rewrite only the functions that specifically need performance improvement. This is done by wrapping a standard deviation function written in C into a Perl module. Wrapping the C function allows us to keep the majority of the program in Perl but allows us to mix in C and C++ where appropriate.
Writing a Perl wrapper over an existing C or C++ interface requires using XS. XS is a tool that is distributed with the Perl package, and it is documented in the perlxs Perl document. You also need some of the information located in the perlguts document. Using XS, I created a Perl package called OAFastStats containing a standard deviation function implemented in C. This function, shown in Listing 5, can then be called directly from Perl. For comparison purposes, this standard deviation function will be called std_dev_OAFast.
The comparison between the baseline standard deviation function and the C function wrapped with XS is presented in Table 2, showing a significant speedup. The C function (std_dev_ref_OAFast) is 1,175% faster than the baseline function (std_dev), and it is 395% faster than the best Perl implementation (std_dev_ref_sum).
During this process I identified a function that probably wasn't performing as well as it could. I was able to achieve several modest performance gains by refining the logic of the calculation in Perl. I also tried using an open-source package, only to find that it was 48% worse than my original function. Finally, I implemented the standard deviation function in C and exposed it to Perl through an XS layer. The C version showed a 1,175% speedup compared to the original Perl version. Improvements are summarized in Figure 1.
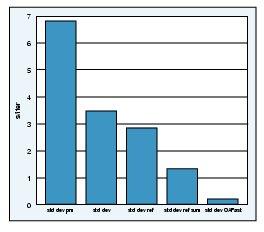
Figure 1. Comparison of All Implementations
In most cases, I have seen Perl performance that rivals C; however, this obviously isn't one of those cases. Perl is a good general-purpose language, and one of its benefits is the ability to step out of the language and implement code in a lower-level language. Don't be afraid of language mix-ins when you really need to improve performance, as long as you understand that there is a maintenance cost. The disadvantage of introducing additional languages is that it will increase the burden for those that must maintain the application in the future. They will need to know C and understand XS functions. However, in our case, the improved performance significantly outweighed the impact of supporting XS.
