
A common set of file formats has the potential to be the most meaningful advancement for free software on the desktop.
Desktop integration begins with documents, not with any toolkit or bundle of applications. If files can be read and written by every application, users can communicate, work together and become integrated. In this sense, the OASIS XML format for office documents has the potential to be one of the most meaningful advances in free computing.
OASIS stands for Organization for the Advancement of Structured Information Standards. Formerly SGML Open, this nonprofit consortium, which includes such companies as IBM, Sun and Boeing, aims to create open standards for almost any kind of structured information. The one we cover here is an XML-based format common to all kinds of office files—text, spreadsheets, presentations and more.
The significance of an effort of this caliber to promote a file format, rather than any specific desktop, application or the Linux kernel itself, cannot be underestimated. Free as in free formats is even more important than free software. Only with them and the internal structuring that comes from XML can data be exchanged, with new or different programs without any need for converters, or be directly edited, indexed, analyzed and exchanged between heterogeneous groups or servers—like Web services without the hype. Data will start belonging exclusively to end users.
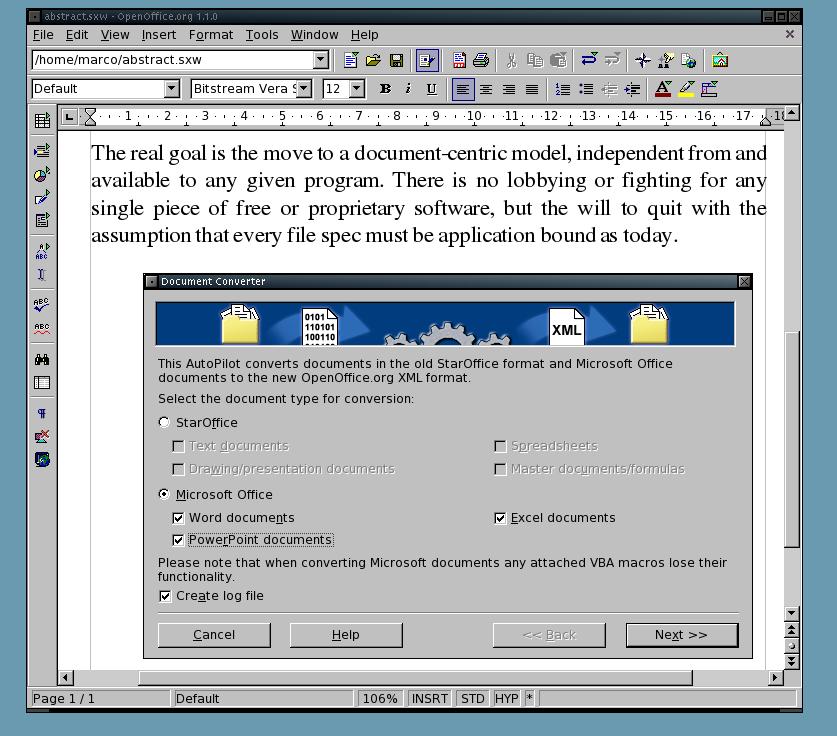
Figure 1. Switching to OASIS and never going back: OpenOffice.org can convert all your closed-format documents to the new standard with only a few clicks.
The OASIS Office Technical Committee had its first meeting in February 2003. The official file format should be voted on in February 2004. After the approval, Phase 2 will start; its main goal will be to extend the base specification to additional areas of application. The real goal is the move to a document-centric model, independent from and available to any given program, regardless of its license. The Technical Committee is determined to quit with the assumption that every file spec must be application-bound, as today.
Some farsighted public administrations already have started to think in this way. The Swedish Agency for Public Management says, “[We] should also follow and if possible support work that takes place in OASIS....An open file format for office software is of great importance for increased interoperability” (www.openoffice.org/servlets/ReadMsg?msgId=585772&listName=discuss). At the European Union level, IDA (Interchange of Data between Administrations) decided in 2003 to carry out exploratory work on open document formats and on how public administrations could persuade software vendors to support them.
The standard conforms to general W3C specifications for XML technologies and covers every aspect of document usages. User interaction, for example, is described in XML schema templates, which operate like traditional API functions. Even they, however, now are independent of any single application.
A text format can be much bigger and more inefficient than an equally free but binary one. Even when the performance hit would be noticeable, however, the benefits simply are too great to give up. In itself, an OASIS office file (be it text, presentation or spreadsheet) is a zip archive: the compression format chosen is a compromise of efficiency, speed of accessing internal parts and algorithm license. Unzipping it, we first find five XML files: styles.xml, presentation and formatting; contents.xml, actual contents; settings.xml, application settings such as zoom level and printer; meta.xml, language and uncoding metadata; and manifest.xml, an explanation of what all the other files are and their relative paths.
Other components (each in a predefined folder, so that even virus scanners have an easier time) may be macros, their dialogs and objects, such as charts or formulas.
Because the standard imposes that all pieces must be present in the zip archive, no information is lost: content, layout and everything else always travel together. Unlike some proprietary offerings in the same space, there is no restriction on which application must be employed to make full use of a document. WYSIWYG results are possible and can be specified fully or replaced in the styles.xml file. At the same time, however, content and presentation are decoupled; hence, content and nothing else is attainable by any application, for any conceivable use. kfile-plugin-ooo, for example, extracts all the metadata embedded in the new file format. The end user then can read, search by metadata or modify all this information straight from KOffice or Konqueror. This plugin also is included in the latest KOffice source trees.
Text format and internal structure make decades of UNIX experience in processing and generating text come back with a vengeance to tame complex, WYSIWYG office documents of every kind. Shell one-liners, Web spiders and so on can query and process directly, much like a database engine, single documents or whole classes of them. Viewing attached presentations as text in mutt or industry-level content management systems becomes easier. As a proof of concept, I was able to get the (admittedly rough) outline of Listing 1 from a presentation simply by typing:
# tr "<" "\012" < content.xml | grep ^text \ | cut '-d>' -f2, | uniq
Encryption obviously is supported, and any paragraph can have an identity attribute. Through this feature, different users can be granted access to different parts of the same document based on their privileges. The default text encoding is UTF-8, even if other ones can be chosen. Suggestions to improve the standard can be posted to office-comments@lists.oasis-open.org.
This design and implementations are all well and good, but users need some application to use it. What is available? Absolutely complete compatibility is possible only with software designed from scratch or with software that has been modified thoroughly to achieve it. In general, existing programs and their developers may have to compromise between the standard and their current concept of the perfect structure of the perfect document. For example, margins are a section or page property in some applications and a paragraph property in others.
This said, the users of OpenOffice.org will have the easiest time; the OASIS standard is built on and almost will be equal to the current OOo formats. AbiWord has both import and less-advanced export filters, but they are not 100% complete. Contributions to improve them are extremely welcome. This program also offers end users the option to use OOo as the default file format. The plan for KOffice, after improving the filters for version 1.3, is to start the switch to OASIS as the native format of future releases. David Faure, one of the chief KOffice developers, also is a member of the Technical Committee, and he foresees no real obstacles to a complete support of the standard, in spite of the frame-oriented rather than page-oriented paradigm used in KOffice.

Figure 2. KOffice is ready to switch to OASIS fully. The internal structure already is stored in XML format, including metadata, and is searchable with external plugins.
SIAG offers some support for reading text and spreadsheet files through external applications, but nothing is available for writing. Emacs surely will come up with its own OASIS mode sooner or later, and WordPerfect also is officially represented in the Technical Committee. In short, things look good. Choice already is offered, and the only things left are to set OASIS as the default save format and to refuse to receive or send files in proprietary formats.
A lot of code already is available to study and reuse for processing the OASIS file format. Whatever you choose, don't forget the standard itself and the main point—format and applications shall remain separated. If you want to improve the first, submit proposals as explained above. If you want faster or more featureful code, do it yourself or help the developer(s) of the corresponding application without touching the format or inventing a new one.
Several standalone filters already are available to move back and forth between OASIS/OOo files (or XML in general) and other formats. The utilities RTF2XML, ooo2txt, SIAG, O3read, o3totxt, o3tohtml, OOo2sDbk, Writer2LaTeX and soffice2html (see Resources) cover together RTF, (X)HTML, LaTeX, DocBook and, of course, plain text.
CPAN hosts several Perl modules useful for OASIS-related processing. OpenOffice::Parse::SXC parses OOo spreadsheets, making the text value of each cell (but nothing else) available for the main script. It comes with a utility to convert OOo spreadsheets to CSV format. Another Perl module, XML::Excel can transform Excel spreadsheets into plain XML, dumping them into an intermediate structure for custom processing, if necessary. On the server side, Apache::AxKit::Provider::OpenOffice extracts the content of text (.sxw) files.
Tcl has linters, DOMs and XSLT interfaces, as well as an API that allows switching to different parsers with no changes to the application code. When nothing else is available, a native Tcl parser is used; otherwise the developer can take advantage of both Expat and Libxml (see below).
PDA developers have a dedicated project, related to OASIS quite directly, called XMerge that currently is developed in Java for Palm and Pocket PC. Its purpose is to allow the editing of OOo documents (maybe previously converted to a more limited format) with PDA native applications, in such a way that any changes can be merged back into the original format without loss of style, formatting and so on.
At a lower level, what is needed to manage OASIS files in a larger application, where the source language usually is C or C++ and the performance must be maximized? First of all, the program must include the proper library to compress and uncompress zipped files. This is not an OASIS-specific issue, so we won't deal with it further.
Once the single XML files are available, they have to be loaded in a way that understands and makes accessible the internal structure, that is, the relationships among the several elements. Once this step has been performed, data can be converted or processed in any manner. A lot of tools for this already exist. Several of them are designed to support general XML rather than OASIS, but the difference is quite a bit smaller than one might expect. And this situation is expected to improve soon after the standard is released.
Expat is a popular XML parser written in C that is basic and lacks a validation capability but still is the fastest one around. It also has front ends for practically every language. A more featureful library that supports DTD validation and is designed specifically for GNOME is Libxml. Like Expat, Libxml is written in C, is portable and can be used within a lot of languages. The Xerces parser, in Java, also can generate and validate XML documents.
In the Qt/KDE field, developers have at their disposal, besides the OOo plugin already mentioned, the related Qt classes and DOM implementation (QDom) to write or parse XML, as well as the KOffice DTD. At the time of this writing, these tools still target the KOffice XML format, but they are expected to converge on the OASIS standard.
For security-conscious developers, the easiest starting point is the C XML security library (XMLsec), based on LibXML2, which supports both signing and encryption of XML material. SAXEcho is a (mostly) Java program that attaches itself to a running OpenOffice.org document to show the XML tree representation of the current document. It also validates or modifies the document operating directly on XML nodes, plus several other nifty things.
The parsers described above build an internal tree representation of the document. What should one do when developing applications that must deal with large documents? Keep in mind that large here means too big to fit into memory, which is not so big if this format must be usable even for low-end desktop applications.
The current solutions in this space follow the so-called SAX (simple API for XML) approach: instead of building the whole tree of a document in one fell swoop and keeping it there for further processing, go step by step. A SAX parser reads the document and, instead of keeping it all in memory, generates an event every time it finds something worthwhile. The parser then passes the event to event handlers that interact with the application. The something worthwhile can be XML document-type definitions, errors or elements of the actual content. A good starting point for SAX-based programming is the SAX Project. SAX2 already is supported in Java through JAXP and in Perl through the Orchard Project, which is quite stable, not to mention fast and lightweight, as far as SAX and XML processing are concerned.
All the research done for this article confirmed one of my first impressions: so far, the free software/open-source software approach to guarantee information interchange has been to develop cross-platform applications, which are difficult to maintain and optimize for each target environment. Now it looks like we are starting to do the right thing, which is to define truly Free, standard, toolkit-independent, cross-platform formats that leave everyone free to create any possible front end to read and write them.
Thanks above all to Gary Edwards and David Faure for all the material and explanations. Pierre Souchay (kfile-plugin-ooo) and the AbiWord developers also were very helpful.
