
The Linux 2.6 kernel has improved Linux's storage capabilities with advances such as the anticipatory I/O scheduler and support for storage arrays and distributed filesystems.
Storage has changed rapidly during the last decade. Prior to that, server-class disks were proprietary in all senses of the word. They used proprietary protocols, they generally were sold by the server vendor and a given server generally owned its disks, with shared-disk systems being few and far between.
When SCSI moved up from PCs to mid-range servers in the mid 1990s, things opened up a bit. The SCSI standard permitted multiple initiators (servers) to share targets (disks). If you carefully chose compatible SCSI components and did a lot of stress testing, you could build a shared SCSI disk cluster. Many such clusters were used in datacenter production in the 1990s, and some persist today.
One also had to be careful not to exceed the 25-meter SCSI-bus length limit, particularly when building three- and four-node clusters. Of course, the penalty for exceeding the length is not a deterministic oops but flaky disk I/O. This limitation required that disks be interspersed among the servers.
The advent of FibreChannel (FC) in the mid-to-late 1990s improved this situation considerably. Although compatibility was and to some extent still is a problem, the multi-kilometer FC lengths greatly simplified datacenter layout. In addition, most of the FC-connected RAID arrays export logical units (LUNs) that can, for example, be striped or mirrored across the underlying physical disks, simplifying storage administration. Furthermore, FC RAID arrays provide LUN masking and FC switches provide zoning, both of which allow controlled disk sharing. Figure 1 illustrates an example in which server A is permitted to access disks 1 and 2 and server B is permitted to access disks 2 and 3. Disks 1 and 3 are private, while disk 2 is shared, with the zones indicated by the grey rectangles.
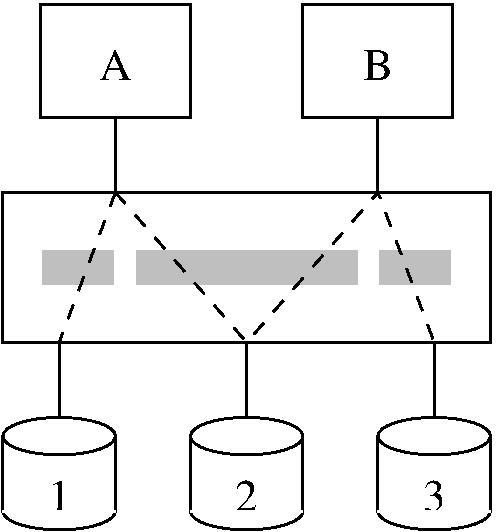
Figure 1. FibreChannel allows for LUN masking and zoning. Server A can access disks 1 and 2, and server B can access 2 and 3.
This controlled sharing makes block-structured centralized storage much more attractive. This in turn permits distributed filesystems to provide the same semantics as do local filesystems, while still providing reasonable performance.
Modern inexpensive disks and servers have reduced greatly the cost of large server farms. Properly backing up each server can be time consuming, however, and keeping up with disk failures can be a challenge. The need for backup motivates centralizing data, so that disks physically located on each server need not be backed up. Backups then can be performed at the central location.
The centralized data might be stored on an NFS server. This is a reasonable approach, one that is useful in many cases, especially as NFS v4 goes mainstream. However, servers sometimes need direct block-level access to their data:
A given server may need a specific filesystem's features, such as ACLs, extended attributes or logging.
A particular application may need better performance or robustness than protocols such as NFS can provide.
Some applications may require local filesystem semantics.
In some cases, it may be easier to migrate from local disks to RAID arrays.
However, the 2.4 Linux kernel presents some challenges in working with large RAID arrays, including storage reconfiguration, multipath I/O, support for large LUNs and support for large numbers of LUNs. The 2.6 kernel promises to help in many of these areas, although there are some areas of improvement left for the 2.7 development effort.
Because most RAID arrays allow LUNs to be created, removed and resized dynamically, it is important that the Linux kernel to react to these actions, preferably without a reboot. The Linux 2.6 kernel permits this by way of the /sys filesystem, which replaced the earlier /proc interfaces. For example, the following command causes the kernel to forget about the LUN on busid 3, channel 0, target 7 and LUN 1:
echo "1" > \ /sys/class/scsi_host/host3/device/3:0:7:1/delete
The busid of 3 is redundant with the 3 in host3. This format also is used, however, in contexts where the busid is required, such as in /sys/bus/scsi/devices.
To later restore only that particular LUN, execute:
echo "0 7 1" > /sys/class/scsi_host/host3/scan
To resize this same LUN, use:
echo 1 > /sys/bus/scsi/devices/3:0:7:1/rescan
To scan all channels, targets and LUNs, try:
echo "- - -" > /sys/class/scsi_host/host3/scan
and to scan only one particular target, enter:
echo "0 7 -" > /sys/class/scsi_host/host3/scan
Although this design is not particularly user-friendly, it works fine for automated tools, which can make use of the libsys library and the systool utility.
One of FC's strengths is it permits redundant paths between servers and RAID arrays, which can allow failing FC devices to be removed and replaced without server applications even noticing that anything happened. However, this is possible only if the server has a robust implementation of multipath I/O.
One certainly cannot complain about a shortage of multipath I/O implementations for the Linux 2.4 kernel. The reality is quite the opposite, as there are implementations in the SCSI mid-layer, in device drivers, in the md driver and in the LVM layer.
In fact, too many I/O implementations in 2.6 can make it difficult or even impossible to attach different types of RAID arrays to the same server. The Linux kernel needs a single multipath I/O implementation that accommodates all multipath-capable devices. Ideally, such an implementation continuously would monitor all possible paths and determine automatically when a failed piece of FC equipment had been repaired. Hopefully, the ongoing work on device-mapper (dm) multipath target will solve these problems.
Some RAID arrays allow extremely large LUNs to be created from the concatenation of many disks. The Linux 2.6 kernel includes a CONFIG_LBD parameter that accommodates multiterabyte LUNs.
In order to run large databases and associated applications on Linux, large numbers of LUNs are required. Theoretically, one could use a smaller number of large LUNs, but there are a number of problems with this approach:
Many storage devices place limits on LUN size.
Disk-failure recovery takes longer on larger LUNs, making it more likely that a second disk will fail before recovery completes. This secondary failure would mean unrecoverable data loss.
Storage administration is much easier if most of the LUNs are of a fixed size and thus interchangeable. Overly large LUNs waste storage.
Large LUNs can require longer backup windows, and the added downtime may be more than users of mission-critical applications are willing to put up with.
The size of the kernel's dev_t increased from 16 bits to 32 bits, which permits i386 builds of the 2.6 kernel to support 4,096 LUNs, though at the time of this writing, one additional patch still is waiting to move from James Bottomley's tree into the main tree. Once this patch is integrated, 64-bit CPUs will be able to support up to 32,768 LUNs, as should i386 kernels built with a 4G/4G split and/or Maneesh Soni's sysfs/dcache patches. Of course, 64-bit x86 processors, such as AMD64 and the 64-bit ia32e from Intel, should help put 32-bit limitations out of their misery.
Easy access to large RAID arrays from multiple servers over high-speed storage area networks (SANs) makes distributed filesystems much more interesting and useful. Perhaps not coincidentally, a number of open-source distributed filesystem are under development, including Lustre, OpenGFS and the client portion of IBM's SAN Filesystem. In addition, a number of proprietary distributed filesystems are available, including SGI's CXFS and IBM's GPFS. All of these distributed filesystems offer local filesystem semantics.
In contrast, older distributed filesystems, such as NFS, AFS and DFS, offer restricted semantics in order to conserve network bandwidth. For example, if a pair of AFS clients both write to the same file at the same time, the last client to close the file wins—the other client's changes are lost. This difference is illustrated in the following sequence of events:
Client A opens a file.
Client B opens the same file.
Client A writes all As to the first block of the file.
Client B writes all Bs to the first block of the file.
Client B writes all Bs to the second block of the file.
Client A writes all As to the second block of the file.
Client A closes the file.
Client B closes the file.
With local-filesystem semantics, the first block of the file contain all Bs and the second block all As. With last-close semantics, both blocks contain all Bs.
This difference in semantics might surprise applications designed to run on local filesystems, but it greatly reduces the amount of communication required between the two clients. With AFS last-close semantics, the two clients need to communicate only when opening and closing. With strict local semantics, however, they may need to communicate on each write.
It turns out that a surprisingly large fraction of existing applications tolerate the difference in semantics. As local networks become faster and cheaper, however, there is less reason to stray from local filesystem semantics. After all, a distributed filesystem offering the exact same semantics as a local filesystem can run any application that runs on the local filesystem. Distributed filesystems that stray from local filesystem semantics, on the other hand, may or may not do so. So, unless you are distributing your filesystem across a wide-area network, the extra bandwidth seems a small price to pay for full compatibility.
The Linux 2.4 kernel was not entirely friendly to distributed filesystems. Among other things, it lacked an API for invalidating pages from an mmap()ed file and an efficient way of protecting processes from oom_kill(). It also lacked correct handling for NFS lock requests made to two different servers exporting the same distributed filesystem.
Suppose that two processes on the same system mmap() the same file. Each sees a coherent view of the other's memory writes in real time. If a distributed filesystem is to provide local semantics faithfully, it needs to combine coherently the memory writes of processes mmap()ing the file from different nodes. These processes cannot have write access simultaneously to the file's pages, because there then would be no reasonable way to combine the changes.
The usual solution to this problem is to make the nodes' MMUs do the dirty work using so-called distributed shared memory. The idea is only one of the nodes allows writes at any given time. Of course, this currently means that only one node may have any sort of access to a given page of a given file at a time, because a page can be promoted from read-only to writable without the underlying filesystem having a say in the matter.
When some other node's process takes a page fault, say, at offset 0x1234 relative to the beginning of the file, it must send a message to the node that currently has the writable copy. That node must remove the page from any user processes that have it mmap()ed. In the 2.4 kernel, the distributed filesystem must reach into the bowels of the VM system to accomplish this, but the 2.6 kernel provides an API, which the second node may use as follows:
invalidate_mmap_range(inode->mapping, 0x1234, 0x4);
The contents of the page then may be shipped to the first node, which can map it into the address space of the faulting process. Readers familiar with CPU architecture should recognize the similarity of this step to cache-coherence protocols. This process is quite slow, however, as data must be moved over some sort of network in page-sized chunks. It also may need to be written to disk along the way.
Challenges remaining in the 2.6 kernel include permitting processes on multiple nodes to map efficiently a given page of a given file as read-only, which requires that the filesystem be informed of write attempts to read-only mappings. In addition, the 2.6 kernel also must permit the filesystem to determine efficiently which pages have been ejected by the VM system. This allows the distributed filesystem to do a better job of figuring out which pages to evict from memory, as evicting pages no longer mapped by any user process is a reasonable heuristic—if you efficiently can work out which pages those are.
The current implementation of NFS lockd uses a per-server lock-state database. This works quite well when exporting a local filesystem, because the locking state is maintained in RAM. However, if NFS is used to export the same distributed filesystem from two different nodes, we end up with the situation shown in Figure 2. Both nodes, running independent copies of lockd, could hand out the same lock to two different NFS clients. Needless to say, this sort of thing could reduce your application's uptime.
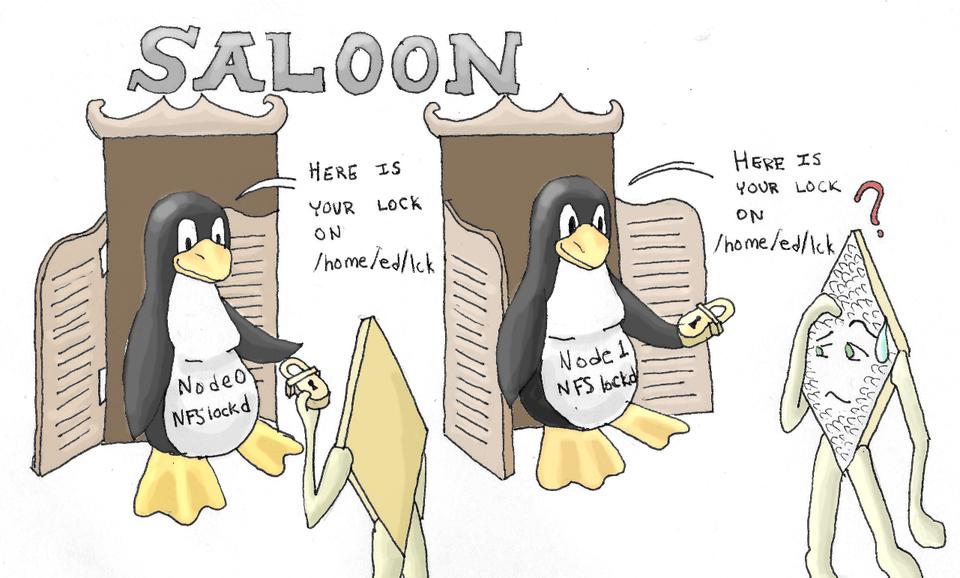
Figure 2. One lock, two clients, big trouble.
One straightforward way of fixing this is to have lockd acquire a lock against the underlying filesystem, permitting the distributed filesystem to arbitrate concurrent NFS lock requests correctly. However, lockd is single-threaded, so if the distributed filesystem were to block while evaluating the request from lockd, NFS locking would be stalled. And distributed filesystems plausibly might block for extended periods of time while recovering from node failures, retransmitting due to lost messages and so on.
A way to handle this is to use multithread lockd. Doing so adds complexity, though, because the different threads of lockd must coordinate in order to avoid handing out the same lock to two different clients at the same time. In addition, there is the question of how many threads should be provided.
Nonetheless, patches exist for these two approaches, and they have seen some use. Other possible approaches include using the 2.6 kernel's generic work queues instead of threads or requiring the underlying filesystem to respond immediately but permitting it to say “I don't know, but will tell you as soon as I find out”. This latter approach would allow filesystems time to sort out their locks while avoiding stalling lockd.
Some distributed filesystems use special threads whose job it is to free up memory containing cached file state no longer in use, similar to the manner in which bdflush writes out dirty blocks. Clearly, killing such a thread is somewhat counterproductive, so such threads should be exempt from the out-of-memory killer oom_kill().
The trick in the 2.6 kernel is to set the CAP_SYS_RAWIO and the CAP_SYS_ADMIN capabilities by using the following:
cap_raise(current->cap_effective,
CAP_SYS_ADMIN|CAP_SYS_RAWIO);
Here, current indicates the currently running thread. This causes oom_kill() to avoid this thread, if it does choose it, to use SIGTERM rather than SIGKILL. The thread may catch or ignore SIGTERM, in which case oom_kill() marks the thread so as to refrain from killing it again.
It appears that storage systems will continue to change. The fact that LAN gear is much less expensive than SAN gear augurs well for iSCSI, which runs the SCSI protocol over TCP. However, widespread use of iSCSI raises some security issues, because failing to disable IP forwarding could let someone hack your storage system. Some believe that serial ATA (SATA) is destined to replace SCSI in much the same way that SCSI itself replaced proprietary disk-interface protocols. Others believe that RAID arrays will be replaced by object stores or object-store targets, and in fact there is an emerging standard for such devices. Either way, interfacing to storage systems will continue to be challenging and exciting.
I owe thanks to the Linux community but especially to Daniel Phillips and Hugh Dickins for most excellent discussions and to Mike Anderson and Badari Pulavarty for their explanations of recent 2.6 kernel capabilities and their review of this paper. I also am grateful to Bruce Allan and Trond Myklebust for their thoughts on resolving the NFS lockd issue.
