
E-books are a disappointing flurry of vendor-specific formats. Get them converted to HTML to view on your choice of device.
Books in digital format, also known as e-books, can be read on devices lacking the power and screen space to afford a regular Web browser. Several publishers, not to mention projects such as Project Gutenberg, have provided thousands of new and classic titles in digital format. The problem is both the hardware—be it generic PDAs or dedicated devices—and the whole e-book publishing industry are much more fragmented than are PCs and Web browsers. Therefore, it is probable that the e-book you recently bought will not be readable ten years from now—nor tomorrow, should you decide to use a laptop or change PDAs. To help combat this fragmentation, this article discusses some existing command-line tools that can convert the most popular e-book formats to ASCII or HTML.
Practically no tools exist now to export e-book formats to PDF or OpenDocument, the new OASIS standard used in OpenOffice.org, but this is not necessarily a big deal. Once text is in ASCII or HTML format, it easily can be moved to plain-text or PDF format by using a text browser such as w3m or programs such as html2ps. If you go this route for conversion, you are able to do it today, and because it's an open format, 20 years from now too.
On PalmOS, the original and most common e-book format is PalmDoc, also called AportisDoc or simply Doc, even though it has nothing to do with Microsoft Word's .doc format. Doc, recognizable by the extensions .pdb (Palm Database) or .prc (Palm Resource Code), basically is a PalmPilot database composed of records strung together. This standard has spun off several variants, including MobiPocket, which adds embedded HTML markup tags to the basic format.
Each Palm e-book is divided into three sections: the header, a series of text records and a series of bookmark records. Normally, the header is 16 bytes wide. Some Doc readers may extend the width at run time to hold additional custom information. By default, the header contains data such as the total length of the uncompressed text, the position currently viewed in the document and an array of two-byte unsigned integers giving the uncompressed size of each text record. Usually, the maximum size for this kind of records is 4,096 bytes, and each one of them is compressed individually.
The bookmark records are composed of a 16-byte name and a 4-byte offset from the beginning of text. Because bookmarks are optional, many Doc e-books don't contain them, and most Doc readers support alternative—that is, non-portable—methods to specify them. Other reader-specific extensions might include category, version numbers and links between e-books. Almost always, this information is stored outside the .pdb or .rc file. Therefore, you should not expect to preserve this kind of data when converting your e-books.
Pyrite Publisher, formerly Doc Toolkit, is a set of content conversion tools for the Palm platform. Currently, only some text formats can be converted, but functionality can be extended to support new ones by way of Python plugins. Pyrite Publisher can download the documents to convert directly from the Web; it also can download set bookmarks directly to the output database. The package, which requires Python 2.1 or greater, can be used from the command line or through a wxWindows-based GUI. The software is available for Linux and Windows in both source and binary format. Should you choose the latter option, remember that compiled versions expect Python to be in /usr. The Linux version can install converted files straight to the PDA using JPilot or pilot-link.
Pyrite installed and ran flawlessly on Fedora Core 2. Unlike the other command-line converters presented below, however, Pyrite can save only in ASCII format, not in HTML. The name of the executable is pyrpub. The exact command for converting .pdb files uses this syntax:
pyrpub -P TextOutput -o don_quixote.txt \ Don_Quixote.pdb
Pyrite can be enough if all you want to do is quickly index a digital library. On the other hand, it is almost trivial to reformat the result to make it more readable in a browser. The snippet of Perl code in Listing 1, albeit ugly, was all it took to produce the version of Don Quixote shown in Figure 1.

Figure 1. A PalmDoc file converted to HTML for viewing in a browser.
The script loads the whole ASCII text previously generated with Publisher, and every time it finds two new lines in a row, it replaces them with HTML paragraph markers. The result then is printed to standard output and properly formatted as basic HTML. To change justification, fonts and colors, you simply need to paste your favourite stylesheet right after the <html><body> line.
OpenOffice.org 2.0, expected to be released in spring 2005, will be able to save text in .pdb format. If it also is able to read such files, its mass conversion feature (File→AutoPilot→Document Converter) would solve the problem nicely. I have tried to do this with the 1.9.m65 preview, but all I got was a General input/output error pop-up message. Hopefully, this functionality will be added to future versions.
Pyrite Publisher is designed mainly to go from normal HTML or text files to the Palm platform, not the other way around. The procedure discussed above is not really scalable to scenarios such as converting a great quantity of Palm e-books to customized HTML, with hyperlinks and metadata included. In such cases, the best solution might be a Perl script combining the standard XML or HTML modules for this language with the P5-Palm bundle; these are available from the Comprehensive Perl Archive Network (see the on-line Resources). The P5-Palm set of modules includes classes for reading, processing and writing the .pdb and .prc database files used by PalmOS devices.
RocketBook e-books have several interesting characteristics, including support for compressed HTML files and indexes containing a summary of paragraph formatting and the position of the anchor names. These and many more details on .rb file internals are explained in the RB format page listed in the on-line Resources. Rbmake Rocket Ebook and Mobipocket files can be disassembled with a set of command-line tools called Rbmake. Its home page offers source code, binary packages, a mailing list and contact information to report bugs. To use rbmake, you need libxml2, version 2.3.1 or higher; the pcre (Perl-Compatible Regular Expressions) library; and zlib, to handle compression. To compile from source—at least on Fedora Core 2—it also is necessary to install separately the pcre-devel package.
A nice feature of Rbmake is the source code is structured in a modular manner. An entire library of object-oriented C routines can be compiled and linked independently from the rest of the package from any other program dealing with .rb files. In this way, should you want to write your own super-customized Rocket Ebook converter or simply index all of your e-books into a database, you would need to use only the piece that actually knows how to read and write the .rb format, the RbFile class. This chunk of code opens the file, returns a list of the sections composing the book and uncompresses on the fly only the ones actually required by the main program. Should you need them, the library also includes functions to match and replace parts of the content through Perl-compatible regular expressions.
The Rbmake tools should compile quickly and without problems on any modern GNU/Linux distribution. Exhaustive HTML documentation also is included in the source tarball. The binary file able to generate HTML files is called rbburst. It extracts all the components—text, images and an info file—present in the original .rb container. Figure 2 shows, in two separate Mozilla Windows, the cover page and the table of contents of the file generated by rbburst when run on The Invisible Man by H. G. Wells.
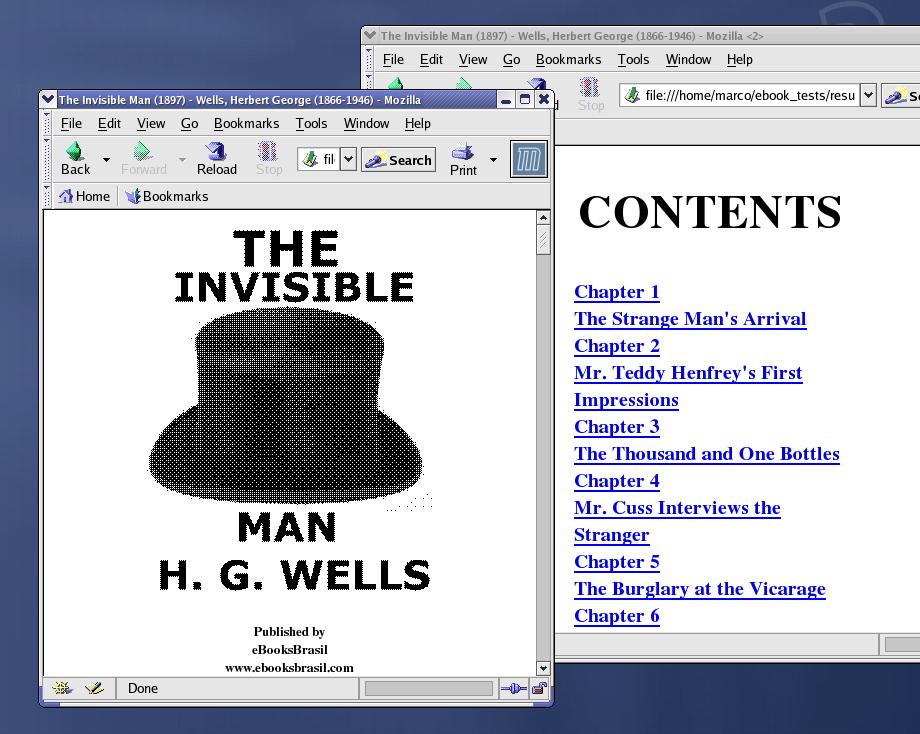
Figure 2. Rbmake extracts all the components of a RocketBook file, including text and images.
Microsoft's Reader files, recognizable by the .lit extension, have many of the characteristics of traditional books, including pagination, highlighting and notes. They also support keyword searching and hyperlinks, but they are locked in to one reader platform.
The tool for converting these files is called, simply, Convert Lit. Running the program with the -help option lists, according to UNIX tradition, all the available command-line options. This program has three modes of operation: explosion, downconversion and inscribing. Explosion is the one needed to convert an existing .lit file to an OEBPS-compliant package. OEBPS (Open eBook Publication Structure) is covered later in the article.
Figure 3 shows a version of Shakespeare's A Midsummer's Night Dream obtained by using explosion from the Convert Lit program. Downconversion is the opposite process; it generates a .lit file for use by a Microsoft Reader-compliant device. Inscribing is when the downconversion attaches a user-defined label to the .lit file. The exact syntax is explained on the program's home page (see Resources).
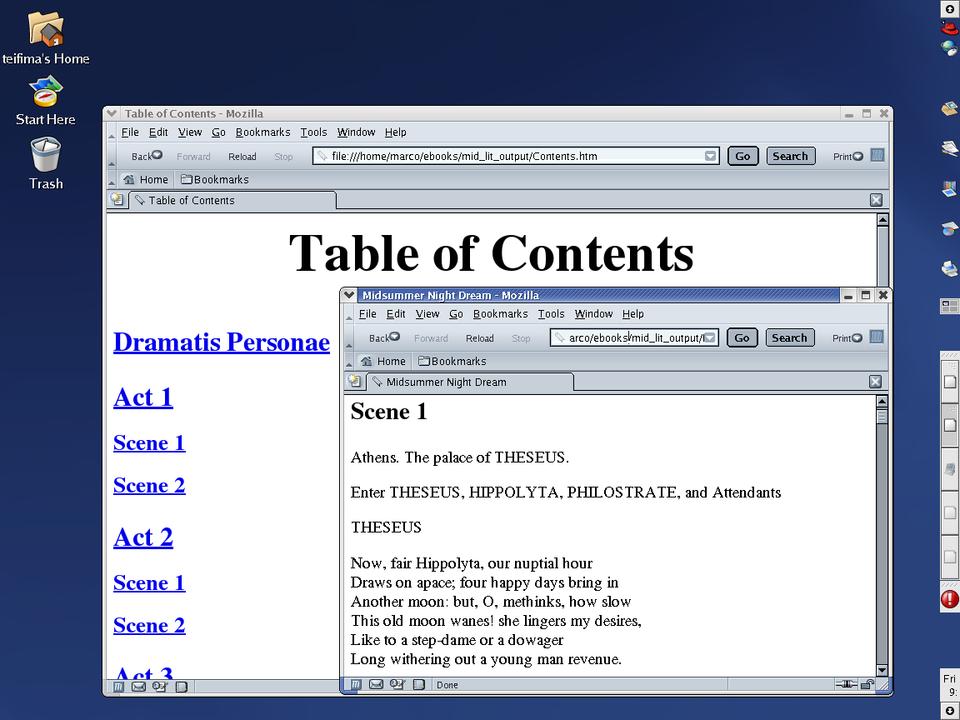
Figure 3. Convert Lit creates a readable HTML file with a hyperlinked table of contents.
We already mentioned that Convert Lit creates an OEBPS package made of different files. Here is the complete list for the example above: Contents.htm, copyright.html, ~cov0024.htm, cover.jpg, MidSummerNightDream.opf, MobMids.html, PCcover.jpg, PCthumb.jpg, stylesheet.css and thumb.jpg. HTML, CSS and JPG files were to be expected, but what is the .opf file? It is an XML container describing the structure and several portions of the original book's metadata. The extension OPF stands for open electronic book package format. The OPF file contains references to the other pieces of the e-book, as well as descriptions of their attributes. To have a clearer idea of its role, a short excerpt of MidSummerNightDream.opf is shown in Listing 2.
The practical consequence of this is Convert Lit could be useful even if you wanted to leave all of your collection in a proprietary format. You still could run the program on all your .lit e-books and delete everything but the .opf files. Then, any quick script or full-blown XML parsing utility could scan them and index everything into the database of your choice.
Convert Lit also removes digital rights management (DRM) infections from e-book files using the older DRM1 version. And if you have Microsoft Reader e-books, you likely have a Microsoft Windows system and a licensed copy of Microsoft Reader. According to the Convert Lit Web site, you can build and run Convert Lit on Windows to first convert new DRM5 e-books to DRM1, using the Windows DRM library.
In general, we have discussed only command-line processing in this article. If, however, you have a whole collection of e-books in different formats, you can convert them all at one time with a simple shell script. As we already have shown, once the text is in ASCII or HTML format, the sky is the limit. You can add one or two lines to the loop to index with glimpse or ht::dig, print everything in one single PostScript book and much more.
A solution for putting e-books, at least the ones you will be able to get in the near future, into an open format is in the works. It is the Open eBook Publication Structure (OEBPS). Its goal is to provide an XML-based specification, based on existing open standards, for providing content to multiple e-book platforms. OEBPS, which has reached version 1.2, is maintained by the Open eBook Forum, a group of over 85 organizations—hardware and software companies, publishers, authors and users—involved in electronic publishing. OEBPS itself does not directly address DRM. However, an OeBF Rights and Rules Working Group is studying these issues “to provide the electronic publishing community with a consistent and mutually supporting set of specifications”. Time will tell what will come from this.
In any case, the open standards on which OEBPS is built already are well established. Besides XML, Unicode, XHTML and selected parts of the CSS1 and CSS2 specifications are represented. Unicode is a family of encodings that enables computers to handle without ambiguity tens of thousands of characters. XHTML is the reformulation of HTML 4 as XML. In a nutshell, OEBPS could be described as nothing more than an e-book optimized extension of XHTML—something that won't go away when some company goes out of business. Graphics can be in PNG or JPEG formats. Metadata, including author, title, ISBN and so on, will be managed through the Dublin Core vocabulary.
OEBPS has the potential to preserve all your e-books and make sure that the ones you download or buy will not vanish if any hardware or software company goes the way of the dodo. However, DRM schemes applied on top of these “open” e-books still could lock your content in to one vendor. As long as you can obtain OEBPS e-books without DRM, OEBPS is the best way to guarantee that even if all current e-book hardware disappeared, your collection would remain usable.
Resources for this article: /article/8208.
