
When Web traffic became a major use of the organization's network, this university put in a control system to track and limit access, using the open-source Squid caching system.
Internet access is one of the major and most demanded services in the computer network of any organization. Olifer and Olifer, in Computer Networks: Principles, Technologies and Protocols write that during the past 10–15 years, the 80/20 split between internal and outgoing traffic has turned over, and the split is now 80% outgoing (see the on-line Resources). The speed of access, the number of services and the volume of available content increase permanently. And the actuality of the Internet user access control task grows up. This problem is quite old, but now some of its aspects are changing. In this article, we consider the variants of its modern solution in the example of the computer network at Bashkir State Pedagogical University (BSPU).
First, we proposed some initial requirements for the Internet access control and management system:
User account support and management.
User traffic accounting and control.
Three types of user traffic limitation: per month, per week and per day.
Support for mobile users—people who use different computers each time they access the Internet, such as students.
Daily and weekly statistics and system condition Web and e-mail reports.
Web-based statistics and system management.
Apparently, these requirements do not specify the system implementation stage in any way and hence do not limit our “fantasy” in this aspect. Therefore, we have done a general consideration of the problem and how to solve it. In the rest of this article, we discuss the ideas and reasoning that led us to our final decision.
Let us revisit the Internet access process itself, with the example of the most popular World Wide Web (WWW) service:
The user runs the browser and enters the required URL.
The browser establishes the connection either directly with the WWW server via the gateway, which makes the network address translation or other network packet manipulations, or with the proxy server, which analyses the client request thoroughly and looks through its cache for the required information. If there is no such information or if it is outdated, the proxy server connects with the WWW server in its own name.
The obtained information is returned to the client.
The browser ends the connection or enters the keep-alive state.
Figure 1 shows the scheme of Internet user access organization.
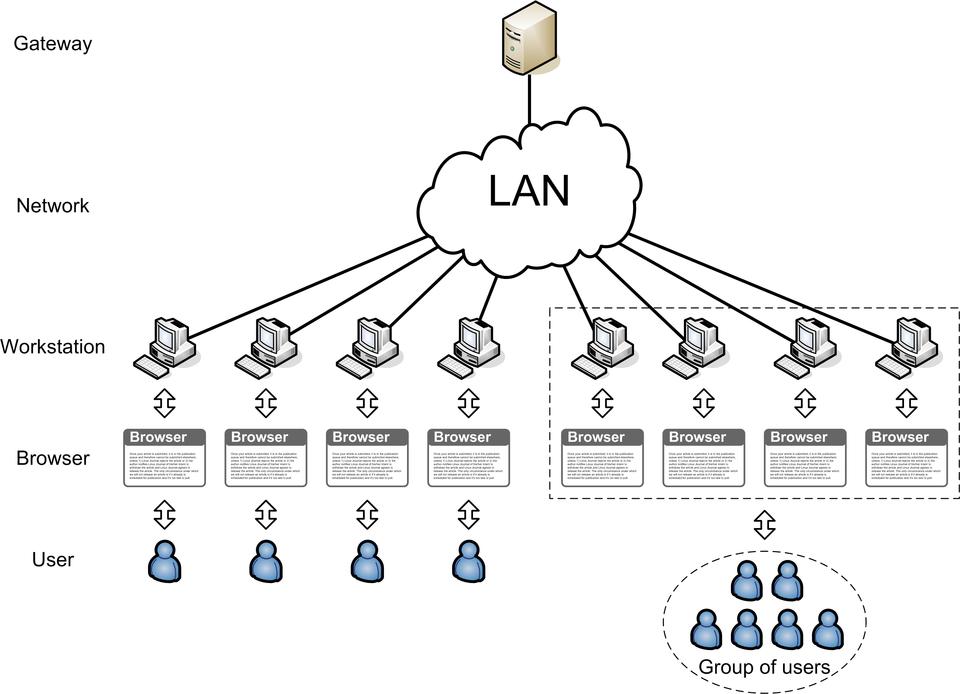
Figure 1. Internet User Access Organization
The main elements of the scheme are the user; client software, including browser and operating system; workstation and other client hardware; network equipment; and the gateway (or proxy server). Other user authorization servers, such as Microsoft Windows domain controllers, OpenLDAP or NIS also may exist in the network.
As Figure 1 shows, the relation between the users and the workstations can be of the one-to-one or the many-to-many type. For instance, members of the university staff are mostly equipped with their own computers.
The main aspects of the problem are user traffic accounting, user authentication, user access control and management and reporting.
These aspects are quite independent of one another and each of them has several ways of implementation. The functions of authentication, traffic accounting and access control may be assigned to any element of the scheme above. And, the best solution will concentrate all of the functions in the single module or in the single access scheme element.
Access control can be implemented on the client side or on the server side. Client-side access control requires using the special client software, which also can authenticate the users. And, there are two ways of server-side access control implementation: firewall and proxy server. Firewall access control has the problem of user authentication. The network packets include only the IP addresses, which are not bound to user names. In the case of using a firewall, this problem has two solutions: use of VPN, which has its own user authentication mechanism and dynamic user-to-IP assignment control. This is possible with some external tools.
The simpler solution, however, is the use of the proxy server, which supports user authentication using the browser. There are three methods of browser authentication:
Basic authentication—a simple and widely distributed scheme, which is supported by the majority of Internet browsers and proxy servers. Its main disadvantage is that the user password is sent over the network with no encryption.
Digest authentication is a more reliable scheme, which uses password hashes for security. Its main imperfection is the lack of special software support.
NTLM authentication is specific for the Microsoft product network infrastructure. Nevertheless, this authentication scheme is acceptable and, furthermore, desirable in many computer networks, including Windows workstations, which are prevalent in Russia as far as we know. The main advantage here is the possibility of the integration of the proxy authentication scheme with Windows and Samba domain controllers.
The task analysis and some of the ideas above led us to the development of two systems:
VPN using PPTP based on the firewall internal features. Historically, the VPN server used FreeBSD, hence, we used the ipfw firewall interface and mpd ported application as a PPTP server. Traffic control is made using the free, distributable NetAMS system.
Squid-based Internet user access control and management system.
The first system was developed by Vladimir Kozlov and is used to connect the university staff members, who use dedicated computers for Internet access. Its main disadvantage is the requirement of a client-side VPN setup. This is a considerable obstacle in the case when the computer network is distributed and the users are not familiar enough with computers.
The second system was developed by Tagir Bakirov and is used to connect the majority of university users, who have no constant computer for Internet access. The complexity of the development was the main drawback of this solution. Next, we discuss the implementation of the second solution in detail.
Before we start, we should mention that the file paths here are always relative to the Squid source base catalog, which, in our case, is /usr/local/src/squid-2.5STABLE7/. The detailed information of getting, compiling and using Squid can be obtained from the Squid site.
Let us now consider some characteristics of Squid, taken from the Squid Programming Guide.
Squid is a single-process proxy server. Every client HTTP request is handled by the main process. Its execution progresses as a sequence of callback functions. The callback function is executed when I/O is ready to occur or some other event has happened. As a callback function completes, it registers the next callback function for the subsequent I/O.
At the core of Squid are the select(2) or the poll(2) system calls, which work by waiting for I/O events on a set of file descriptors. Squid uses them to process I/O on all open file descriptors. comm_select() is the function that issues the select() system call. It scans the entire fd_table[] array looking for handler functions. For each ready descriptor, the handler is called. Handler functions are registered with the commSetSelect() function. The close handlers normally are called from comm_close(). The job of the close handlers is to deallocate data structures associated with the file descriptor. For this reason, comm_close() normally must be the last function in a sequence.
An interesting Squid feature is the client per-IP address database support. The corresponding code is in the file src/client_db.c. The main idea is the hash-indexed table, client_table, consisting of the pointers to ClientInfo structures. These structures contain different information on the HTTP client and ICCP proxy server connections, for example, the request, traffic and time counters. The following is the respective code from the file src/structs.h:
struct _ClientInfo {
/* must be first */
hash_link hash;
struct in_addr addr;
struct {
int result_hist[LOG_TYPE_MAX];
int n_requests;
kb_t kbytes_in;
kb_t kbytes_out;
kb_t hit_kbytes_out;
} Http, Icp;
struct {
time_t time;
int n_req;
int n_denied;
} cutoff;
/* number of current established connections */
int n_established;
time_t last_seen;
};
Here are some important global and local functions for managing the client table:
clientdbInit()—global function that initializes the client table.
clientdbUpdate()—global function that updates the record in the table or adds a new record when needed.
clientdbFreeMemory()—global function that deletes the table and releases the allocated memory.
clientdbAdd()—local function that is called by the function clientdbUpdate() and adds the record into the table and schedules the garbage records collecting procedure.
clientdbFreeItem()—local function that is called by the function clientdbFreeMemory() and removes the single record from the table.
clientdbSheduledGC(), clientdbGC() and clientdbStartGC()—local functions that implement the garbage records collection procedure.
By parallelizing the requirements to the developed system and the possibilities of the existing client database, we can say that some key basic features already are implemented, except the client per-user name indexing. The other significant shortcoming of the existing client statistic database is that the information is refreshed after the client already has received the entire requested content.
In our development, we implemented another parallel and independent client per-user database using the code from the src/client_db.c file with some modifications. User statistics are kept in structure ClientInfo_sb. The following is the corresponding code from the file src/structs.h:
#ifdef SB_INCLUDE
#define SB_CLIENT_NAME_MAX_LENGTH 16
struct _ClientInfo_sb {
/* must be the first */
hash_link hash;
char *name;
unsigned int GID;
struct {
long value;
char type;
long cur;
time_t lu;
} lmt;
/* HTTP Request Counter */
int Counter;
};
#endif
The client database is managed by the following global and local functions, quite similar to those listed previously:
clientdbInit_sb()—global function that initializes the client table.
clientdbUpdate_sb()—global function that updates the record in the table, disconnects the client when the limit is exceeded or adds the new record when needed by calling the function clientdbAdd_sb().
clientdbEstablished_sb()—global function that counts the number of client requests and periodically flushes the appropriate record into the file, disconnects the client when the limit is exceeded and adds the new record when needed by calling the function clientdbAdd_sb().
clientdbFreeMemory_sb()—global function that deletes the table and releases the allocated memory.
clientdbAdd_sb()—local function that is called by the function clientdbUpdate_sb() and adds the record into the table and schedules the garbage records collecting procedure.
clientdbFlushItem_sb()—local function that is called by the functions clientdbEstablished_sb() and clientdbFreeItem_sb() and flushes the particular record into the file.
clientdbFreeItem_sb()—local function that is called by the function clientdbFreeMemory_sb() and removes the single record from the table.
clientdbSheduledGC_sb(), clientdbGC_sb() and clientdbStartGC_sb()—local functions that implement the garbage records collecting procedure.
The client database initialization and release are implemented similarly to the original table in the file src/main.c. The main peculiarity of our code is the calls of the functions clientdbUpdate_sb() and clientdbEstablished_sb() in the client-side routines in the file src/client_side.c:
call of the function clientdbUpdate_sb() from the auxiliary function clientWriteComplete(), which is responsible for sending the portions of data to the client.
call of the function clientdbEstablished_sb() from the function clientReadRequest(), which processes the client request.
Listing 1 shows the corresponding fragments of the functions clientWriteComplete() and clientReadRequest() from the file src/client_side.c.
Thus, the mechanism is quite simple. Figure 2 shows the simple client request processing diagram from the point of view of our system. Each client request contains the user authentication information, including the user name. The function clientdbUpdate_sb() searches for the ClientInfo_sb record, which corresponds to the user name obtained from the request. In the case of the absence of such a record, it adds the new ClientInfo_sb record using the information from the authority files. If users exceed their limit, they are disconnected immediately with the function comm_close(). The call of the function clientdbEstablished_sb() is also used to control the number of client requests and to save current user information into the authority files every SB_MAX_COUNT requests. The authority files are called passwd and group analogously to the UNIX files. The passwd file contains the user information, and the group file contains the user group information. Here are the descriptive samples:
`passwd': #<name>:<full name>:<group id>: #<current limit value>:<last limit update time> tagir:Tagir Bakirov:1:6567561:12346237467 `group': #<name>:<full name>:<group id>: #<group limit value>:<group limit type> users:BSPU users:1:10000000:D

Figure 2. Simple Client Request Processing Diagram
There are three types of limit: D (daily), W (weekly) and M (monthly). The passwd and group filenames and paths can be set in the Squid configuration file squid.conf. This was implemented by modifying the structure of the squid.conf template file and the structure of the Squid configuration structure.
Here are the other slight changes in the Squid source code:
Global functions definition in the file src/protos.h.
ClientInfo_sb structure type definition in the file src/typedefs.h.
ClientInfo_sb structure identifier declaration in the structure list in the file src/enums.h.
ClientInfo_sb structure initialization in the memory allocation procedure memInit() in the file src/mem.c.
All of these changes are made analogously to the code, maintaining the original client per-IP database. We hope everything was done right.
Looking through our modifications, you may have noticed that all the code is put into the conditional compilation blocks (#ifdef SB_INCLUDE ... #endif). The variable SB_INCLUDE is declared when the parameter --enable-sbclientdb is included into the command line of the Squid configure script. This was made by recompiling the configure.in script with autoconf after putting in some slight modifications.
In this article, we considered the state of the art in the Internet access control problem. We proposed several methods for its solution and considered the variant based on the Squid proxy server, which has been implemented in the LAN of BSPU. Our solution is not the panacea and possibly has several drawbacks, but it is rather simple, flexible and absolutely free.
We also should say that our Web-programmer, Elmir Mirdiev, is now finishing the implementation of a small PHP-based Web site designed for system management and user statistics reporting. The user-detailed statistics are generated from the Squid logs using the Sarg system.
Other information can be obtained from the source code of the system. You can get the whole modified source code of Squid version 2.5STABLE7 tarball on our site or only the patch file. We will be glad to answer your questions by e-mail.
Resources for this article: /article/8205.
