
How to get started using this small-footprint object-oriented database in your embedded system programs.
db4o is an open-source, object-oriented database from db4objects. It is embeddable, in the sense that the entire db4o engine is supplied as a single library that links into your application. Versions of db4o exist for Java and .NET/Mono. Consequently, it's an ideal OODBMs engine for Linux applications written in either the Java or .NET frameworks. In this article, the examples provided have been written in C# and tested in Mono running on an Ubuntu Linux system. (We also ran the applications on a Monoppix system.)
Besides being an open-source library—so you can download it instantly and begin experimenting with its capabilities—db4o's other outstanding characteristic is its terse, easily grasped API. In most cases, you'll use methods drawn from a set of nine fundamental calls. In addition, the library's memory footprint is modest, making it ideal for resource-constrained applications (though by no means is db4o incapable of enterprise-level work).
Despite its small footprint and uncomplicated programming interface, db4o provides all the features you'd expect from a commercial database engine: it allows multiuser access, any access on the database is invisibly wrapped in a transaction and all operations adhere to ACID principles (atomicity, consistency, isolation and durability).
Unlike some object-oriented and object-relational database systems, db4o does not require you to pass your code through an instrumentation pre- or post-compilation step. Nor must classes whose objects are to be made persistent be derived from a special persistence-aware superclass. db4o is happy to work with ordinary objects, and you need not inform it of an object's structure before you store that object into a db4o database.
As we hope to show, this provides us with some unexpected capabilities.
Suppose our application is a dictionary—a dictionary in the classic sense. That is, the application manipulates a database that stores words and their definitions. In such an application, we might define a class to model dictionary entries as follows:
/*
* DictEntry
*/
using System;
using System.Collections;
namespace PersistentTrees
{
/// <summary>
/// DictEntry class
/// A dictionary entry
/// </summary>
public class DictEntry
{
private string theWord;
private string pronunciation;
private ArrayList definitions;
public DictEntry()
{
}
// Create a new Dictionary Entry
public DictEntry(string _theWord,
string _pronunciation)
{ theWord = _theWord;
pronunciation = _pronunciation;
definitions = new ArrayList();
}
// Add a definition to this entry
// Note that we do not check for duplicates
public void add(Defn _definition)
{
definitions.Add(_definition);
}
// Retrieve the number of definitions
public int numberOfDefs()
{
return definitions.Count;
}
// Clear the definitions array
public void clearDefs()
{
definitions.Clear();
definitions.TrimToSize();
}
// Properties
public string TheWord
{
get { return theWord; }
set { theWord = value; }
}
public string Pronunciation
{
get { return pronunciation; }
set { pronunciation = value; }
}
// Get reference to the definitions
public ArrayList getDefinitions()
{
return definitions;
}
}
}
A DictEntry object consists of three elements: the word itself, its pronunciation and a list of definitions. Meanwhile, a class for describing definition objects might look like this:
/*
* Defn
*
*/
using System;
namespace PersistentTrees
{
/// <summary>
/// Description of Class1.
/// </summary>
public class Defn
{
public static int NOUN = 1;
public static int PRONOUN = 2;
public static int VERB = 3;
public static int ADJECTIVE = 4;
public static int ADVERB = 5;
public static int CONJUNCTION = 6;
public static int PARTICIPLE = 7;
public static int GERUND = 8;
private int pos;
private string definition;
public Defn(int _pos,
string _definition)
{
pos = _pos;
definition = _definition;
}
// Properties
public int POS
{
get { return pos; }
set { pos = value; }
}
public string Definition
{
get { return definition; }
set { definition = value; }
}
}
}
So, a Defn object includes an integer member indicating the part of speech and a string member that holds the text for the definition. This structure allows us to associate multiple definitions with a single entry in the dictionary.
Storing such items into a db4o database is marvelously simple. Assume that we want to add the word float to our dictionary and provide it with three definitions:
Defn _float1 = new Defn(VERB, "To stay on top of a liquid.");
Defn _float2 = new Defn(VERB, "To cause to float.");
Defn _float3 = new Defn(NOUN, "Anything that stays on top of water.");
DictEntry _float = new DictEntry("float", "flote");
_float.add(_float1);
_float.add(_float2);
_float.add(_float3);
At this point, we have a DictEntry object, _float, whose list of definitions includes three items.
First, we open the database itself. A db4o database is modeled by an ObjectContainer object, and we can open (or create, if it doesn't exist) an ObjectContainer with:
ObjectCointainer db = Db4o.openFile("<filename>");
where <filename> is the path to the file that holds the persistent content of the ObjectContainer. You put an object into the ObjectContainer using the set() method. So, we can store our new definition with:
db.set(_float);
which, believe it or not, is just about all you need to know about the set() method. That one call stores not only the _float DictEntry object, but all of its contained Defn objects as well. When you call db4o's set() method, the db4o engine invisibly spiders through the object's references, persisting all the child objects automatically. Just pass set() the root object of a complicated object tree, and the whole shebang is stored at one shot. You don't have to tell db4o about your object's structure; it discovers it automatically.
To retrieve an object from an ObjectContainer, we locate it with the help of db4o's QBE (query by example) mechanism. A QBE-style query is guided by an example, or template, object. More specifically, you perform a query by creating a template object, populating its fields with the values you want matched, showing the template object to the query system and saying, “See this? Go get all the objects that look like this one.”
So, assuming you want to retrieve our definitions for float, the process looks something like this:
// Create template
DictEntry DTemplate = new DictEntry("float", "");
// Execute QBE
ObjectSet results = db.get(DTemplate);
// Iterate through results set
while(results.hasNext())
{
DictEntry _entry = (DictEntry)results.next();
... process the DictEntry object ...
}
First, we create the template object, filling the fields we're interested in with the values we want matched. Fields that shouldn't participate in the query are filled with zero, the empty string, or null—depending on the data type. (In the above example, we're simply looking for the word float in the dictionary. We put an empty string in the pronunciation field for the templater object constructor, because the pronunciation is irrelevant to the query.)
Then, we execute the query by calling the ObjectContainer's get() method, with the template object passed in as the single argument. The query returns an ObjectSet, through which we can iterate to retrieve the results of the match.
At this point, we can easily create a database, fill it with words and definitions, and retrieve them using db4o's QBE mechanism. But, what if we want to experiment with different indexing-driven retrieval mechanisms? Because the database preserves relationships among the persistent objects, we can create custom indexing and navigation structures, place them in the database as well and “wire” our data objects into those structures.
We illustrate how simple this is by creating two dissimilar indexing schemes.
First, we create a binary tree. Each node of the tree carries as its payload a key/data pair. The key will be a text word from the dictionary, and the associated data item will be a reference to the DictEntry object in the database. So, we can fetch the binary tree from the database, execute a search for a specific word in the dictionary and fetch the matching DictEntry object (if found).
The architecture and behavior of binary trees are well known, so we won't go into much detail about them here. (In fact, many frameworks now provide them as standard data structures. We've created an explicit one to show how easily it can be stored in the database.) Our implementation appears in Listing 1. It is rudimentary, supporting only insertion and searching. It doesn't guarantee a balanced tree, but it serves for the purposes of illustration. The TreeNode class, which defines the structure of nodes within the binary tree, appears in Listing 2. (Note, we'll explain the purpose of the calls to db.activate() in Listing 1 shortly.)
Next, I create a trie, an indexing data structure specialized for searching text words. It is built as a series of nodes arranged in levels—each level holds a set of characters and associated pointers such that the characters on the topmost (or, root) level correspond to letters in a word's first character position; characters in the second level correspond to letters in the second character position, and so on. References associated with each character serve to “string” characters like beads on a thread, so that following a thread from the root down into the tree spells out the word being searched for.
If this is difficult to visualize, the illustration in Figure 1 should help.
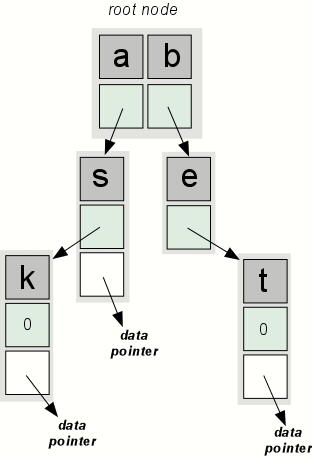
Figure 1. A trie. In a trie index, individual characters within a word are stored at different node levels. This particular trie holds three words: as, ask and bet. The data pointers are actually references to the DictEntry objects associated with the corresponding words.
Inserting a new word into a trie is relatively simple. Starting with the first matching character, you examine the root node to see whether that character exists. If not, add it, and from that point on, the algorithm inserts new nodes (each initialized with a subsequent letter) as it works through the target word. If the character does exist, the algorithm follows the associated pointer to the next level, and the examination process repeats. Ultimately, you've accounted for each character in the word, and the node you're on is the node on which you attach the data reference.
Searching a trie is equally simple. Start at the root, and look for the first character. If the character is found, follow the associated reference to the next node; else, return a “not found” error. Otherwise, move to the next character, repeat, and if you get through the whole word, the data node associated with the terminal character points to the DictEntry object.
The code for the trie is shown in Listing 3.
As the code for inserting and searching both binary trees and tries illustrates, we can work with database objects almost as though they were purely in memory objects. Specifically, we can attach an object to an index simply by storing its object reference in the data reference element.
In addition, because the database makes no distinction between index objects and data objects, we need not create a separate index and data files. This keeps everything in one place, which is actually more of an advantage than one might first suppose.
Code for reading a text file with words and definitions, creating DictEntry objects and storing them in the database, and also building binary tree and trie indexes and attaching the DictEntry objects to them looks like this:
string theword;
string pronunciation;
int numdefs;
int partofspeech;
string definition;
DictEntry _dictEntry;
// Open a streamreader for the text file
FileInfo sourceFile = new FileInfo(textFilePath);
reader = sourceFile.OpenText();
// Open/create the database file
ObjectContainer db = Db4o.openFile(databaseFilePath);
// Create an empty Binary tree, and an empty trie
BinaryTree mybintree = new BinaryTree();
Trie mytrie = new Trie();
// Sit in an endless loop, reading text,
// building objects, and putting those objects
// in the database
while(true)
{
// Read a word.
// If we read a "#", then we're done.
theword = ReadWord();
if(theword.Equals("#")) break;
// Read the pronunciation and put
// it in the object
pronunciation = ReadPronunciation();
_dictEntry = new DictEntry(theword, pronunciation);
// Read the number of definitions
numdefs = ReadNumOfDefs();
// Loop through definitions. For each,
// read the part of speech and the
// definition, add it to the definition
// array.
for(int i=0; i<numdefs; i++)
{
partofspeech = ReadPartOfSpeech();
definition = ReadDef();
Defn def = new Defn(partofspeech, definition);
_dictEntry.add(def);
}
// We've read all of the definitions.
// Put the DictEntry object into the
// database
db.set(_dictEntry);
// Now insert _dictEntry into the binary tree
// and the trie
mybintree.insert(_dictEntry.TheWord, _dictEntry);
mytrie.insert(_dictEntry.TheWord, _dictEntry);
}
// All done.
// Store the binary tree and the trie
db.set(mybintree);
db.set(mytrie);
// Commit everything
db.commit();
This, of course, presumes a number of helper methods for reading the source file, but the flow of logic is nonetheless apparent. Notice again that we were able to store each index—in entirety—simply by storing the root with a single call to db.set().
Fetching something from the database is only somewhat trickier. As much as we'd like to treat persistent objects identically to transient objects, we cannot. Objects on disk must be read into memory, and this requires an explicit fetch. The initial fetch is, of course, is a call to db.get() to locate the root of the index. So, code that allows us to search for a word using either the binary tree or the trie index would look like this:
public static void Main(string[] args)
{
Object[] found;
DictEntry _entry;
// Verify proper number of arguments
if(args.Length !=3)
{
Console.WriteLine("usage: SearchDictDatabase <database> B|T <word>");
Console.WriteLine("<database> = path to db4o database");
Console.WriteLine("B = use binary tree; T = use trie");
Console.WriteLine("<word> = word to search for");
return;
}
// Verify 2nd argument
if("BT".IndexOf(args[1])==-1)
{
Console.WriteLine("2nd argument must be B or T");
return;
}
// Open the database file
ObjectContainer db = Db4o.openFile(args[0]);
if(db!=null) Console.WriteLine("Open OK");
// Switch on the 2nd argument (B or T)
if("BT".IndexOf(args[1])==0)
{ // Search binary tree
// Create an empty binary tree object for the
// search template
BinaryTree btt = new BinaryTree();
ObjectSet result = db.get(btt);
BinaryTree bt = (BinaryTree) result.next();
// Now search for the results
found = bt.search(args[2],db);
}
else
{ // Search trie
// Create an empty trie object fore the search
// template
Trie triet = new Trie();
ObjectSet result = db.get(triet);
Trie mytrie = (Trie) result.next();
// Now search for the results
found = mytrie.search(args[2],db);
}
// Close the database
db.close();
// Was it in the database?
if(found == null)
{
Console.WriteLine("Not found");
return;
}
// Fetch the DictEntry
_entry = (DictEntry)found[0];
... <Do stuff with _entry here> ...
And now we can explain the purpose of the calls to db.activate() in the search methods of both Listings 1 and 3.
When you call the db.set() method, as we explained, the db4o engine spiders through the object tree, persisting all reachable objects. (This is known as persistence by reachability.) In the reverse direction—that is, calling db.get() to fetch an object—db4o does not pull the entire object tree out of the database. If it did that, then fetching the root of, for example, the binary index, would cause db4o to pull the entire index, plus all the dictionary entries, plus all the definitions into memory at once—not very efficient if we want only one word.
Instead, db4o uses a concept called activation depth. Suppose I've fetched object A into memory from a db4o database using a db.get() call. If I then call db.activate(A,6), that tells db4o also to fetch into memory all objects referenced by A, up to a depth of 6. So, the db.activate() calls that are sprinkled throughout the search routines of the binary tree and the trie classes ensure that the search operation always pulls in enough of the index so that the search can proceed. (And, at the end of a successful search, the dictionary objects are fetched.)
OO databases provide the developer with flexibility not so easily gotten with an RDBMS. In particular, you can design complex, deep object structures, persist them to a database and not have to concern yourself with the translation between the object model and the relational model.
The OO database db4o's simple-to-grasp API did not hinder our building indexing structures in the database side by side with the actual data. Though the binary tree and trie indexes we chose were uncomplicated, they demonstrated that the developer is free to augment a database with custom indexing and navigation structures of arbitrary complexity. So, we can tailor-make an organization scheme that fits the application's requirements of its data, and we can design it using plain-old objects—Java or Mono/.NET. Best of all, db4o is open-source, so there's nothing stopping you from grabbing it for your next database application. For more information concerning db4o, see www.db4objects.com.
