
Yes, you still need a firewall. How about a transparent one?
When I started writing this column in autumn of 2000, I had the day job of firewall engineer. I enjoyed that type of work, but I was enough of a big-picture kind of guy to be aware that every year, firewalls were becoming less important in the overall scheme of things. In fact, I was convinced that within a decade or so, firewalls would be nearly if not completely obsolete.
But, I was wrong! Firewalls aren't dying. They're evolving, and even though traditional firewall technologies probably achieve less than they did ten years ago, the threats we'd face if we did without them still justify the effort and expense of keeping them around.
So, I think the time is ripe for me to return to my roots, so to speak. This month, I kick off a series of articles I've been meaning to tackle for some time: how to build a transparent firewall using Linux. To begin, I set the stage by explaining why firewalls are still relevant in the first place and the difference between “routing” and “bridging” (transparent) firewalls.
I was tempted to begin with a primer on firewall architecture and design, discussing the difference between the multihomed and “sandwich” topologies, rule design methodology and so forth. But my April 2007 article “Linux Firewalls for Everyone” does that just fine, and you still can read it on-line (see Resources). Instead, I'm going to talk about why firewalls are still useful.
An IP firewall, as opposed to an application firewall or XML gateway, inspects network traffic at the IP and TCP/UDP layers, possibly with some very limited amount of application intelligence (for example, being able to distinguish between FTP “get” and “put” commands, HTTP “post” vs. “get” and so forth). In actual practice, most packet-filtering and “stateful” IP-filtering firewalls evaluate traffic primarily based on source and destination IP addresses, and source and destination UDP or TCP ports.
When I started out in network engineering, just filtering traffic based on these few criteria seemed plenty powerful enough for most practical firewall applications, especially if the firewall was smart enough to track network traffic by session rather than by individual packet. (In olden times, it wasn't enough to program your IP-filtering firewall to allow outbound DNS queries on UDP port 53; you also had to put in a corresponding rule to allow DNS replies originating from UDP port 53. State-tracking, or “stateful”, firewalls automatically correlate packets to already-allowed sessions.)
Because in those days of yore different network applications all used different TCP and UDP ports—TCP port 23 for telnet, TCP and UDP ports 53 for DNS, TCP ports 20 and 21 for FTP and so forth—filtering by port number equated to filtering by application type.
This didn't mean firewalls could detect or prevent evil that might occur over an allowed source/destination/address/port combination. We had no illusions that the firewall could stop, for example, Apache buffer overflow attacks against a public Web server reachable from the entire world on TCP port 80. The firewall could (and can), however, prevent attempts to connect to that Web server via Secure Shell on TCP port 22, except perhaps from some internal, authorized access point.
The problem is that every year, we're less able to rely on the assumption that the things we should be worried most about will happen on ports that the firewall can block altogether. This is because so much of what people use networks for happens on only two TCP ports: TCP 80 (HTTP) and TCP 443 (HTTPS).
Even ten years ago, developers were racing to migrate from client-server application architectures, in which every network application used its own communication protocol, to the Web services model, in which there are really only two types of network transactions, Web sessions and database transactions. Well before then, people started figuring out ways to do practically everything that can be done over networks—from browsing a filesystem to running a remote desktop session—over HTTP using a Web browser.
But does this really mean that firewalls are obsolete? Definitely not, not even in contexts where Web servers are involved. Let's suppose it were true that all network traffic between two security zones happened over TCP port 443. By restricting traffic by source IP address and destination IP address, you still could make decisions about which hosts could initiate any transactions to any other given host.
If one filters traffic strictly based on source and destination IP addresses and, in practical terms, not by TCP/UDP port (service type), you may think that you haven't achieved much. All an attacker has to do in order to attack a protected system is gain access to some other system that the firewall allows to initiate transactions with your actual target. But, what if none of those “secondary” systems that the firewall considers trusted is externally reachable? If that's the case, your “crude” firewall rules may, in fact, have effectively mitigated the risk of remote compromise for that system.
This scenario is illustrated in Figure 1, which shows a firewall that sits in between two different networks, Zone A and Zone B, and the Internet. The firewall blocks all inbound traffic from the Internet to either zone, but allows hosts in Zone B to initiate transactions with hosts in Zone A. In this case, the firewall is highly effective in making it unfeasible for Internet-based attackers to exploit the trust relationship between Zones A and B, even if the firewall filters only on source IP address.

Figure 1. Filtering Only by Source IP Address
But, I'm not really advocating address-only filtering. The fact is there are still plenty of important network services that use ports and protocols besides TCP 80/443 and HTTP/HTTPS. Domain Name Services still use TCP and UDP 53; Microsoft Remote Desktop Protocol (Terminal Services) still uses TCP port 3389; Oracle still uses TCP port 1521; and so on. Modern firewalls still make plenty of meaningful decisions about what traffic to allow, based on service type.
Another argument against the usefulness of firewalls is the fact that malware (viruses, trojans, worms) has evolved from being mainly a nuisance to becoming a sophisticated means of infiltrating even well-secured networks. Ten years ago, the most likely impact of a virus or worm outbreak in one's organization was a disruption of service. Malware tended to strain system and network resources, but by its indiscriminate nature, it wasn't very useful for stealing data or breaching sensitive systems.
Nowadays, however, malware often is targeted at specific organizations by attackers who first go to great lengths to learn what data and systems to have their malware seek out, based on known (or highly probable) vulnerabilities on those systems. In other words, nowadays malicious hackers often deploy worms as “avatars” of themselves!
Such targeted malware is extremely difficult to detect, remediate against or trace back. Often, it's placed directly on target networks or systems by co-opted insiders. Therefore, firewalls frequently have little useful role in blocking the activity of targeted malware. It doesn't matter how thick your fortress walls are if your mailroom guys have been bribed to ignore the fact that the large package addressed to your king is ticking.
But I ask you, does the fact that bad guys may simply mail your king a bomb, mean that you can safely replace those expensive castle walls—the tuckpointing-bill for which in any given year is probably astronomical—with cardboard? I, for one, don't think you can.
Just because attackers are developing ever-more sophisticated tools doesn't mean they'll forget how to use the old ones. Remember the LAND attack from the late 1990s? It involved sending spoofed TCP packets bearing the same source IP address as the target to which you're sending them, causing a massive “reply to myself” sort of loop, which impairs system performance (potentially cripplingly). LAND was made obsolete by system patches and firewall protections—or so we thought. But in 2005, a security researcher named Dejan Levaja discovered that Windows Server 2003 and Windows XP SP2 were vulnerable to the LAND attack.
The fact that LAND attacks are (still) trivially blockable by firewalls is actually beside the point. What I'm really trying to illustrate is that no attack is truly obsolete for as long as it's still feasible and as long as systems are vulnerable to it. In theory, if your organization rigorously hardened every single computer connected to the network, if you took down your firewalls you might not get infected or attacked right away. But I guarantee you would, sooner rather than later, and not strictly by completely cutting-edge attack techniques.
So, to summarize, even if you think all your firewall does is block traffic from unexpected sources, it still provides meaningful protection. Modern network traffic does not, in fact, consist solely of HTTP and HTTPS; it still plays out over a surprisingly wide range of different ports and protocols. And, the rise in use of targeted malware and attacks against Web applications aren't arguments against firewalls; they're simply reasons that firewalls alone aren't sufficient to protect critical systems.
Can we agree, then, that firewalls are still an important tool in the network security toolkit? I hope so, because I'm about to spend several months showing you how to build a particularly clever type of Linux firewall: a transparent firewall.
Normally, a firewall acts like a router. It receives traffic from two or more network interfaces and makes decisions about whether and how to route that traffic. Any host that needs to send traffic through the firewall must either use the IP address of the firewall interface that faces it as its default gateway, or a router between that host and the firewall must be configured to use the firewall as a route to whatever networks are on the other side of the firewall.
Figure 2 shows a routing firewall. As you can see, each firewall interface has its own IP address that is valid on the network to which that interface connects, and that IP address serves as the route to the other side of the firewall. In this example, hosts in Network A have to know (or send packets to some router that knows) that 10.20.30.254 is the gateway to reach Network B. Hosts in Network B have to know (or speak to a router that knows) that 44.55.66.254 is the gateway to reach Network A.
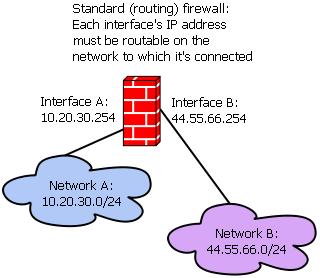
Figure 2. A Standard (Routing) Firewall
One ramification of the “firewall as router” approach is that normally, if you have a big bunch of existing systems you want to divide into two security zones, one “trusted” and the other “non-trusted”, you'll probably need to re-IP-address the hosts in one or both zones (or re-mask the subnet they're on, which may not be possible) and insert a firewall configured as a gateway between those zones. In other words, inserting a routing firewall into an existing network usually means reconfiguring both the network and the systems connected to it.
But, what if you wanted to insert a firewall between two parts of the same network, without re-addressing anything? Is it possible to configure a firewall to act more like a bridge than a router?
Indeed, it is. And best of all, the firewall's rules will look and behave in much the same way as if it were a standard routing firewall! All the trickery is in the firewall's network configuration.
Figure 3 shows a transparent (bridging) firewall. In this example, the firewall has been configured to treat both of its network interfaces as switch ports. Neither interface has an IP address bound to it! Instead, the virtual switch that they comprise has a shared IP address of 44.55.66.254. Although the firewall might be reachable by this IP address (actually there are good reasons for it not to be), none of the hosts in Zone A need to use that IP as a gateway in order to reach the hosts in Zone B, or vice versa. Just as with any other switch, the firewall will propagate packets automatically without needing to be explicitly routed through.

Figure 3. A Transparent (Bridging) Firewall
However, the firewall will propagate packets only after first matching them against its firewall rule set and determining whether it even should propagate them. If you want to evaluate packets based on Ethernet header attributes, you can do so using ebtables. However, in this series of articles on building your very own transparent Linux firewall, we'll use plain-old iptables to evaluate packets in the same way that routing firewalls do, using IP/TCP/UDP header information.
But, that will have to wait until next time. Hopefully, you now understand the difference between a standard, routing firewall and a transparent, bridging firewall. In my next column, I'll sketch out an example usage scenario (conceptually very similar to the network in Figure 3), describe a couple different approaches to selecting Linux firewall hardware and begin showing how to configure a transparent firewall, starting with bridge/switch setup. Until then, be safe!
