
Understand and defend against DNS cache poisoning.
Few recent Internet threats have made such a big impact as security researcher Dan Kaminsky's discovery, in 2008, of fundamental flaws in the Domain Name System (DNS) protocol that can be used by attackers to redirect or even hijack many types of Internet transactions. The immediate response by DNS software providers was to release software patches that make the problematic “DNS cache poisoning” attacks more difficult to carry out, and this certainly helped.
But, the best fix is to use DNSSEC, a secure version of the DNS protocol that uses x.509 digital certificates validated through Public Key Infrastructure (PKI) to protect DNS data from spoofing. Slowly but surely, DNSSEC is being deployed across key swaths of Internet infrastructure.
What does DNS cache poisoning mean, and how does it affect you? How can you protect your users from attacks on your organization's nameserver? The next few months, I'm going to explore DNS cache poisoning and DNSSEC in depth, including how DNS queries are supposed to work, how they can be compromised, and how they can be protected both in general and specific terms.
I'm not going to attempt to cover all aspects of DNS server security, like in Chapter Six of my book Linux Server Security (see Resources). Armed with the next few months' columns, however, I hope you'll understand and be able to defend against cache poisoning, a particular but very nasty DNS vulnerability.
As seems to be the pattern with these multiple-installment extravaganzas, I'm going to start out at a general, less-hands-on level, and enter increasingly technical levels of detail as the series progresses. With that, let's talk about how DNS is supposed to work and how it can break.
The Domain Name System is both a protocol and an Internet infrastructure for associating user-friendly “names” (for example, www.linuxjournal.com) with networks and computers that are, in fact, known to each other and to network infrastructure devices by their Internet Protocol (IP) addresses (for example, 76.74.252.198).
Sounds simple enough, right? Perhaps it would be, if the Internet wasn't composed of thousands of different organizations, each needing to control and manage its own IP addresses and namespaces. Being such, the Internet's Domain Name System is a hierarchical but highly distributed network of “name authorities”—that is, DNS servers that are “authoritative” only for specific swaths of namespace.
Resolving a host or network/domain name to an IP address, therefore, is a matter of determining which name authority knows the answer to your particular question. And, as you'll see shortly, it's extremely important that you can trust the answer you ultimately receive. If you punch the name of your bank's on-line banking site into your Web browser, you don't want to be sent to a clever clone of online.mybank.com that behaves just like the real thing but with the “extra feature” of sending your login credentials to an organized crime syndicate; you want to be sent to the real online.mybank.com.
The security challenge in DNS lookups (also called queries) is, therefore, to ensure that an attacker can't tamper with or replace DNS data. Unfortunately, the DNS protocol was designed with no rigorous technical controls for preventing such attacks.
But, I'm getting ahead of myself! Let's dissect a DNS lookup to show what happens between the time you type that URL into your browser and the time the page begins to load.
Your Web browser doesn't actually interact with authoritative nameservers. it passes the question “what's the IP address of online.mybank.com?” to your computer's local “stub resolver”, a part of the operating system. Your operating system forwards the query to your local network's DNS server, whose IP address is usually stored, on UNIX and UNIX-like systems, in the file /etc/resolv.conf (although this often is just a copy of data stored in some other network configuration script or file or of configuration data received from a DHCP server).
That local nameserver, which in practice is run either by your organization's Information Technology department or by your Internet Service Provider, then does one of two things. If it already has resolved online.mybank.com reasonably recently, it sends your browser the query results from its “cache” of recently resolved names. If online.mybank.com isn't in its cache, it will perform a recursive query on your behalf.
Recursive queries generally take several steps, illustrated in Figure 1. In our example, the recursing DNS server first randomly selects the IP address of one of the Internet's “root” nameservers from a locally stored list (every DNS server has this list; it isn't very long and seldom changes). It asks that root nameserver for the IP address of online.mybank.com.
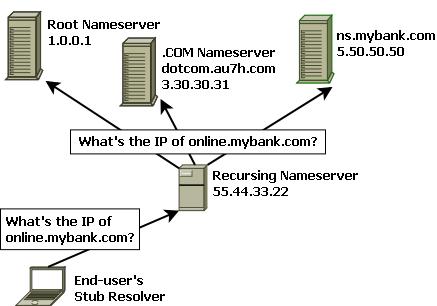
Figure 1. A Recursive DNS Query
The root nameserver replies that it doesn't know, but it refers the recursing nameserver to an authoritative nameserver for the .com top-level domain (TLD)—in our example, the fictional host dotcom.au7h.com. The root nameserver also provides this host's IP address (3.30.30.31). These two records, the NS record referring dotcom.au7h.com as an authority for .com and the A record providing dotcom.au7h.com's IP address, are called glue records.
The recursing nameserver then asks dotcom.au7h.com if it knows the IP address for online.mybank.com. It too replies that it doesn't know, but it refers the recursing nameserver to another nameserver, ns.mybank.com, which is authoritative for the mybank.com domain. It also provides that host's IP address (5.50.50.50).
Finally, the recursing nameserver asks ns.mybank.com whether it knows the IP address for online.mybank.com. Yes, it does: ns.mybank.com replies with the requested IP address, and the recursing nameserver forwards that information back to the end user's stub resolver, which in turn provides the IP address to the end user's Web browser.
In this example, then, the simple query from your stub resolver results in three queries from your local recursing DNS server, representing queries against root, the .com TLD and, finally, the mybank.com name domain. The results from all three of these queries are cached by the local DNS server, obviating the need for your server to pester authoritative nameservers for .com and .mybank.com until those cache entries expire.
That expiration time is determined by each cached record's Time to Live (TTL) value, which is specified by whatever authoritative nameserver provides a given record. A records that map IPs to specific hosts tend to have relatively short TTLs, but NS records that specify authoritative nameservers for entire domains or TLDs tend to have longer TTLs.
I've described how DNS query recursion is supposed to work. How can it be broken?
Two things should be fairly obvious to you by now. First, DNS is an essential Internet infrastructure service that must work correctly in order for users to reach the systems with which they wish to interact. Second, even a simple DNS query for a single IP address can result in multiple network transactions, any one of which might be tampered with.
Relying, as it does, on the “stateless” UDP protocol for most queries and replies, DNS transactions are inherently prone to tampering, packet-injection and spoofing. Tampering with the reply to a DNS query, on a local level, is as simple as sending spoofed packets to the “target” system making the query and hoping they arrive before the query's “real” answer does.
Spoofing a DNS reply being sent from a recursing DNS server to a client system impacts only that one client system's users. What if you could instead tamper with the recursive nameserver's queries, injecting false data into its cache and, thus, affecting the DNS queries of all computers that use that DNS server?
And, what if, instead of tampering strictly with individual A records describing the IPs of individual hosts, you could inject fraudulent NS records that redirect DNS queries to your (fraudulent) nameserver, potentially impacting an entire name domain?
When security researcher Dan Kaminsky discovered fundamental flaws in the DNS protocol in 2008, these were the very attack scenarios he identified. Before you get too panicky, I'm going to give a little spoiler, and say that even in 2008, before he gave his now-renowned Black Hat presentation on these attacks, Kaminsky worked with DNS server software vendors, such as ISC and Microsoft, to release urgent patches that at least partially mitigated this risk before Kaminsky's attack became widely known.
But, the attack has been only partially mitigated by patching. Because this is such an important, widespread and interesting issue, let's explore Kaminsky's DNS cache poisoning attack in depth.
All the transactions comprising the DNS query in Figure 1 use UDP, which I've said is easily spoofed. So, what's to prevent an attacker from sending fraudulent replies to any one of those transactions?
Before 2008, the answer to this question was twofold: Query IDs and bailiwick checking. Every DNS query packet contains a Query ID, a 16-bit number that must be included in any reply to that query. At the very least, Query IDs help a recursive DNS server that may have numerous, concurrent queries pending at any given time to correlate replies to the proper queries as they arrive, but the Query ID also is supposed to make it harder to spoof DNS replies.
Bailiwick is, here, a synonym for “relevance”. Any glue records included in a DNS reply must be relevant to the corresponding query. Therefore, if an attacker attempts to poison a recursing DNS server's cache via a “Kashpureff attack” (see the Cricket Liu interview in the Resources section) in which extraneous information is sent via glue records to a recursing DNS server that has been tricked into making a query against a hostile nameserver, the attack will succeed only if the recursing nameserver fails to perform bailiwick checking that correlates those glue records to the query.
For example, if I can get a recursing DNS server to look up the name an.evilserver.com, and I control the evilserver.com name domain, I could send a reply that includes not only the requested IP, but “extra” A records that point www.citibank.com, www.ameritrade.com and other sites whose traffic I wish to intercept using impostor servers.
Those fake A records will replace any records for those hosts already cached by the target recursing nameserver. However, bailiwick checking has been a standard, default feature for practically all DNS server software since 1997, so the Kashpureff attack is largely obsolete (insofar as any historical TCP/IP attack ever is).
So to review, Query IDs are supposed to prevent reply spoofing, and bailiwick checking is supposed to prevent weirdness with glue records.
Yet, Kaminsky discovered that despite Query IDs and bailiwick checking, it nonetheless was possible both to spoof DNS replies and abuse glue records and, thus, to poison the caches of most recursing nameservers successfully. Here's how Kaminsky's attack works.
The object of this attack is to poison a recursing DNS nameserver's cache with fraudulent A records (for individual hosts) or even fraudulent NS records (for entire domains). In the example I'm about to use, the objective will be to inject a fraudulent A record for the host online.mybank.com.
This will be achieved by either initiating, or tricking some other host served by the recursing nameserver into initiating, a flood of queries against random, presumably nonexistent hostnames in the same name domain as that of the host whose name we wish to hijack. Figure 2 shows an attacker sending a flood of queries for hostnames, such as random3232.mybank.com, random4232.mybank.com and so forth.
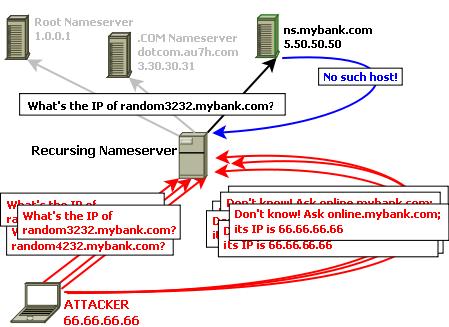
Figure 2. Kaminsky's Cache Poisoning Attack
Besides the fact that it's convenient to generate a lot of them, querying randomized/nonexistent hostnames increases the odds that the answers aren't already cached. Obviously, if you send a query for some host whose IP already is in the recursing nameserver's cache, that nameserver will send you the IP in question without making any recursive queries. Without recursive queries, there are no nameserver replies to spoof!
Almost concurrently with sending the queries, the attacker unleashes a flood of spoofed replies purporting to originate from that name domain's authoritative nameserver (in Figure 2, ns.mybank.com). There are several notable things about these replies.
First, also as shown in Figure 2, they do not provide answers to the attacker's queries, which as you know concern nonexistent hosts anyhow. Rather, they refer the recursing nameserver to another “nameserver”, online.mybank.com, conveniently offering its IP address as well (which, of course, is actually the IP address of an attacker-controlled system).
The whole point of these queries is to provide an opportunity to send glue records that pass bailiwick checking but are nonetheless fraudulent. If you're trying to hijack DNS for an entire domain, in which case you'd spoof replies to queries against a Top-Level Domain authority, such as for .com, you'd send glue records pointing to a hostile DNS server that could, for example, send fraudulent (attacker-controlled) IPs for popular on-line banking and e-commerce sites, and simply recurse everything else.
In the example here, however, the attacker instead is using the pretense of referring to a different nameserver, in order to plant a fake online.mybank.com Web server's IP address into the target recursing nameserver's cache. The fact that this fake Web server doesn't even respond to DNS queries doesn't matter; the attacker wants on-line banking traffic to go there.
The second notable thing about the attacker's spoofed replies (and this is not shown in Figure 2), is that each contains a different, random Query ID. The reason for sending a flood of queries and a flood of replies is to maximize the chance that one of these reply's Query IDs will match that of one of the corresponding recursed queries that the targeted recursing nameserver has initiated to ns.mybank.com.
And, this is arguably the most important aspect of Kaminsky's attack. By simultaneously making multiple guesses at the Query IDs of multiple queries, the attack takes advantage of the “birthday problem” to improve the chances of matching a spoofed reply to a real query. I'll resist the temptation to describe the birthday problem here (see Resources), but suffice it to say, it's a statistical principle that states that for any potentially shared characteristic, the odds of two or more subjects sharing that characteristic increases significantly by increasing the population of subjects even slightly.
Thus, even though the odds are 65,534 to 1 against an attacker guessing the correct Query ID of a single DNS query, these odds become exponentially more favorable if the attacker attempts multiple queries, each with multiple fake replies. In fact, using a scripted attack, Kaminsky reported success in as little as ten seconds!
Yet another thing not shown in Figure 2 is the TTL for the fraudulent glue A records in the attacker's spoofed replies. The attacker will set this TTL very high, so that if the attack succeeds, the victim nameserver will keep the fraudulent A record in its cache for as long as possible.
The last thing to note about this attack is that it will fail if none of the spoofed replies matches a query, before ns.mybank.com manages to get its real reply back to the recursing nameserver. Here again, initiating lots of simultaneous queries increases the odds of winning at least one race with the real nameserver, with a reply containing a valid Query ID.
As scary as Dan Kaminsky's cache poisoning attack is, the short-term fix is simple: make DNS server software send its DNS queries from random UDP source ports, rather than using UDP port 53 or some other static, predictable port. Prior to 2008, BIND, Microsoft DNS Server and other DNS server packages would send all DNS queries from a single port. This meant that to spoof replies to DNS queries, the attacker needed to know only what type of DNS software the target server was running to know what UDP port to use as the destination port for spoofed reply packets.
Randomizing query source ports thus makes spoofers' jobs much harder: they either have to eavesdrop network traffic and observe from what port a given query originates or send lots of spoofed replies to many different ports in the hope that one of them is “listening” for the reply. Thus, in the context of Kaminsky's cache poisoning attack, selecting a random source port from a pool even as small as 2,048 possible ports makes it exactly 2,048 times harder for attackers to guess what a valid DNS reply packet should look like, than if they have to guess only the correct Query ID!
Sure enough, before Kaminsky publicly announced the details of his attack, he convinced DNS server software vendors to issue patches that made their respective products randomize DNS query source ports, and now in 2011, this is the way DNS servers behave by default. This was only a partial fix, however. It's still possible to make Kaminsky's attack work; it just takes much longer.
A better fix is to sign DNS zone data cryptographically, so that recursing nameservers can validate DNS replies. This is possible with the DNSSEC extension to the DNS protocol, and DNSSEC will be the subject of the next column or two.
Having described DNS recursion and cache poisoning attacks in gory detail, next time, I'll begin showing you how to enable DNSSEC on your own (BIND-based) recursing nameserver, so that it checks the signatures of any signed DNS data it comes across. Until then, make sure your DNS software is fully patched, try not to worry too much, and be safe!
