
SciPy is used in scientific programming, but now with the parallel functionality in IPython, you can run your code in an HPC environment.
More and more science is happening on silicon, if not completely, then at least partially. With its ability to run interactively, as well as heavy support for packages with tuned C components, Python quickly is filling the scientific computing environment. The main package people import for handling scientific programming is SciPy (scipy.org). This package provides several functions that allow you to write code to solve your scientific problems. To take full advantage of all of these capabilities, however, you really need a decent development environment. IPython (ipython.org) can provide just such an environment. It is a good balance between ease of use, especially for exploratory work, and it offers a complete development environment. This article covers using IPython and SciPy to set up an environment for scientific computations.
The first step is to install IPython and SciPy. Luckily, most distributions should have packages available for both of these. For example, on Ubuntu, simply execute:
sudo apt-get install ipython python-scipy
Most distributions, unless they are rolling-release distros, are at least a version behind the latest and greatest. If you want to have the latest capabilities or bug fixes, you need to download the sources from the projects' Web sites. For both packages, you should be able to download the sources, unpack them and run the following in each source directory:
python setup.py install
Be sure to check the documentation for both packages. They each have a rather large set of dependencies that need to be installed before you try to build.
Now that you have them both installed, let's look at what you can do, starting with IPython. IPython provides a very enhanced interactive shell for interactive work, including access to GUI components, and an architecture for interactive parallel computing. When you start working with IPython, you have access to the sorts of features available to users of bash. For example, pressing Tab provides auto-completion of the command you currently are typing. All of your previous commands, both input and output, are available as numbered items. They are stored in two separate arrays called In and Out. You can access them by using In[1] or Out[3], just like any other array.
IPython also is really useful in interacting with the objects in memory. You can look at details of these object with the ? operator. For example, you can pull up information on your object by typing:
my_object?
Figure 1. Starting IPython shows the license information and some help functions.
You also can get specific pieces of information by using the commands %pdoc, %pdef, %psource and %pfile.
A useful feature of IPython in code development is the ability to log all of the work you are doing to an external file. Within your session, you can start logging with the magic command %logstart. Or, you can turn on logging from the start by adding the command-line option --logfile=log.py to IPython. You then can load this log file at a later time to get IPython to replay the commands and essentially restore your session to its previous state. It's not perfect, but it's still useful. (I discuss the plotting functions and parallel options after covering a bit of SciPy.)
SciPy is actually an extension to another Python package, NumPy. NumPy provides extensions that define numerical array and matrix types, along with basic operations that apply to them. SciPy builds on these, allowing you to do advanced math, signal processing, optimization, statistics and more. Let's get some work done by starting up IPython. You'll see the licensing information, along with some initial commands that tell you how to get help. To begin with, let's look at some of the extras that NumPy gives you for scientific computing. One of the best features, from a code-writing perspective, is the overloading of mathematical operators. For example, the old way of adding two vectors looks something like this:
for i in range(len(a)): c.append(a[i] + b[i])
This actually can be relatively slow for large vectors, because Python needs to do some verifying of the data types and the operations at each iteration of the for loop. With NumPy, you can rewrite this as:
import numpy as np ... c = a + b
This is quite a bit faster, because the actual work is handled by an external library as a single unit of work. As you can see above, in Python, you need to import external packages with the import command. The most basic version of the import statement is:
import numpy
This adds everything from NumPy into your Python session's namespace, and you can access the imported functions with their short names. You can import a package and attach it to a new name, as I did in the example above. You then can access the imported items by prepending the name that it is imported as to the function short names.
Importing the entire package is fine for something moderate in size like NumPy, but SciPy has grown over the years to be a rather large and complicated package. Importing everything available can be quite time-consuming initially. To try to help with this, SciPy actually subdivides the available functions as sub-packages. When you import SciPy, you get only the functions not in one of the sub-packages. If you really want to load everything in SciPy, you need to use this:
import scipy; scipy.pkgload()
If you know what kind of work you will be doing, it will make more sense to import only the parts you need, with a command like this:
from scipy.fftpack import fft as scipy_fft
When you use IPython, you can skip all of this by using the profile system. In IPython, you can define a session profile that takes care of initialization steps that you would have to do every time. Several profiles are included when you install IPython, so in this case, you simply can start IPython with:
ipython -p scipy
This handles the imports for you so you have everything you might need.
As an example, one thing that gets done numerically is transforming and analyzing sound. When looking at sound, you may be interested in analyzing the spread of frequencies. This can be done by using fast Fourier transform (FFT) functions. In SciPy, you can import the sub-package fftpack to access the FFT functions. For example, you can create a vector of 100 ones followed by 900 zeros with:
a = zeros(1000) a[:100] = 1
You can get the Fourier transform of this vector with:
b = fft(a)
The result is a list of complex numbers.
When you are doing exploratory work, it is really helpful to be able to see the results graphically. Luckily, IPython includes the matplotlib module. If you want to have it available, you either can start your IPython session with ipython -pylab, or you can import the pylab module manually. With that done, you then can plot results with something like:
plot(abs(b)) show()
Figure 2. SciPy has a lot of functionality, like fast Fourier transforms.
Matplotlib is modeled after the graphics system in R where the different steps of plotting are actually separate manual steps. So plotting graphs is one step, and showing the plots on the screen is a separate step. This means you need the show() command to get the graphical output. Lots of options are available in matplotlib to handle graphical display of data and results.
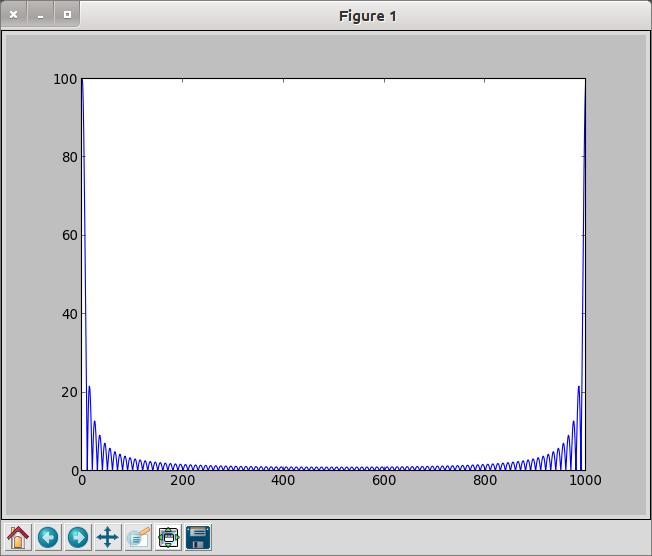
Figure 3. Matplotlib gives you the functionality to analyze your results graphically.
The last thing to look at here is the parallel support you get with IPython. In any large scientific code, you will need to run on some sort of parallel machine in order to get your work done in a reasonable amount of time. With IPython, you have support for the following:
Single Instruction Multiple Data (SIMD) parallelism.
Multiple Instruction Multiple Data (MIMD) parallelism.
Message passing using MPI.
Task farming.
Data parallelization.
You can use combinations of these or develop your own custom parallel techniques. The most powerful capability in IPython is the ability to develop, execute, debug and monitor your parallel code interactively. This means you can start to develop your code and then add in parallelism when you reach the appropriate stage.
The IPython architecture consists of four parts:
IPython engine: an instance that takes Python commands over the network and runs them.
IPython hub: the central process that manages engine connections, schedulers, clients and so on.
IPython scheduler: all actions go through a scheduler to a specific engine, allowing work to be queued up.
Controller client: made up of a hub and a set of schedulers, providing an interface for working with a set of engines.
To start using IPython's parallel components, you need to start up a controller and some number of engines. The easiest way to start is to use ipcluster on a single machine. For example, if you want to start a controller and four engines on a single host, you can type:
ipcluster start -n 4
You likely will get an error at this point due to not being able to import the module zmq. This module handles the security issues in the communications between the different parts of IPython. Again, there should be a package for that. In Ubuntu, the package is named python-zmq.
Once you get your four engines started, they are available when you start IPython. You will need to do this in another terminal window, because ipcluster still will be running in the original terminal. After importing the parallel module, you can create a Client object to interact with the engines created by ipcluster:
from IPython.parallel import Client rc = Client()
Figure 4. When you start ipcluster, it will display status information to the console.
As a first test that the parallel functionality is working correctly, you can check the IDs of the available engines by executing:
rc.ids
In this case, you should notice that four engines are available.
One of the simplest forms of parallelism is to divide Python's map command across the available engines. Remember that the map command takes some function and applies it to each element of a list. The parallel version of map takes the list and divides it across the available engines. To do so, you can create a DirectView object using list notation and use its map method:
dview = rc[:] parallel_results = dview.map_sync(lambda x: x**10, range(32))
Figure 5. when you start IPython, it will pick up the newly created engines.
In more complicated systems, you actually can create profiles defining how the parallel system is to be configured. This way, you don't need to remember all of the details. To create a profile, you can run:
ipython profile create --parallel --profile=myprofile
This will create a directory named profile_myprofile in $IPYTHONDIR. This is usually in $HOME/.config/ipython. You then can go in and edit the generated files and define the options. For example, you can set up a system where the IPython engines are created on machines over a network with MPI and a controller is created on your local machine.
Once the profile is finished, you can start the cluster with:
ipcluster start --profile=myprofile
Then when you start IPython, you can run code on all of these networked machines. With this kind of functionality, you can get some really serious work done on a full-sized HPC cluster.
Python, with IPython and SciPy, has been growing in popularity as a language for doing high-performance scientific work. Traditionally, the opinion was that it is useful only for smaller problems, and that you needed to move to C or Fortran to get “real” work done. With the parallel functionality in IPython combined with SciPy, this no longer applies. You can do work on larger clusters and deal with even larger problem sets. This article barely scratched the surface, so look at the related Web sites to learn even more.
