
This article is about the R advanced statistical package. Despite its simple name, R is a wonderful piece of statistical software with many complex capabilities and an interpreted computer language—it's also free. Don't be afraid of R if you don't feel very comfortable with mathematics or statistics. This article presents some easy-to-understand and practical scenarios that illustrate the use of R.
R is a GNU project based on S, which is a statistics-specific language and environment developed at the famous AT&T Bell Labs. You can think of R as the free version of S. The R system distribution supports a large number of statistical procedures, including linear and generalized linear models, nonlinear regression models, time series analysis, classical parametric and nonparametric tests, clustering and smoothing. At the time of this writing, the current version of R is 3.0.1, which was released May 16, 2013.
You can use GUIs for R, and the most popular GUI, which also is my favorite, is called RStudio. However, I use only the command-line version of R for this article to keep things as general as possible.
Your Linux/UNIX distribution probably includes a ready-to-install R package, so go ahead and install it. Alternatively, you can go to cran.r-project.org and download a precompiled binary or get the source code and compile it yourself. After installing it, typing R on your terminal will take you to the R shell. Once the R shell starts, you can start typing R commands. The initial R output on your screen should look similar to the following:
$ R R version 3.0.1 (2013-05-16) -- "Good Sport" Copyright (C) 2013 The R Foundation for Statistical Computing Platform: x86_64-apple-darwin12.3.0 (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under certain conditions. Type 'license()' or 'licence()' for distribution details. Natural language support but running in an English locale R is a collaborative project with many contributors. Type 'contributors()' for more information and 'citation()' on how to cite R or R packages in publications. Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. > q() Save workspace image? [y/n/c]: n mtsouk$
One of the first things you will want to learn is how to quit R. Typing q() quits the R shell and takes you back to the UNIX shell.
R keeps a history of all typed commands in a hidden file called .Rhistory. The .Rhistory file is stored inside the directory where you ran the R binary, so if you are running R from multiple directories, you will have multiple .Rhistory files on your computer.
The contents of a simple .Rhistory file look like this:
$ cat .Rhistory
install.packages("RCurl")
install.packages("RJSON")
install.packages("rjson")
install.packages("rgoogleanalytics")
install.packages("google")
source("./RGoogleAnalytics.R")
source("db.R")
summary(wwwdatacomma)
q <- sqldf("SELECT count(*) FROM WWW", dbname = "WWW.sqlite")
q()
Notice that the .Rhistory file also includes erroneous commands that were typed but not executed, so don't trust everything you see in it.
In order to avoid retyping the same R code, you can create R scripts, which is a very handy R feature. A good practice is first to try the commands one by one inside the R shell and then convert them into a script to save time. As always, don't forget to include comments in your code.
The source() command is used for calling an existing R script when you are inside the R shell. If you want to find help for the source() command (or any other existing command), simply type the following:
> ?source()
If you want to search for help, but you don't know the exact command, try the following:
> help.search("keywords to find")
R supports the use of the Tab key, as in the bash shell, so type the first letters of a command, press the Tab key, and R will help you find the rest of the command you are trying to type.
R has a large repository of existing packages, so you don't have to program everything from the beginning. There are two ways to install an R package:
Install a package that can be found on CRAN (The Comprehensive R Archive Network) using the install.packages() function.
Download it to your computer and install it from the local file using the same install.packages() command but with different parameters.
The next section of this article shows examples of both installation methods.
The library() function, without any arguments, prints a list of all the installed packages. To get more-detailed output of all the installed R packages, you also can use the installed.packages() command. The update.packages() command will update the installed CRAN packages to their latest versions.
R can communicate with Google Analytics natively using an R package, so you can retrieve and perform statistical analysis of the Google Analytics data. The first step is to download the relevant R package from https://code.google.com/p/r-google-analytics, because CRAN does not contain the RGoogleAnalytics package. Make sure you don't download the ZIP file, because it is the Windows version of the R package. The UNIX version is a .tar.gz file called RGoogleAnalytics_1.3.tar.gz (at the time of this writing).
Then, you need to install it manually using the following command, provided that the RGoogleAnalytics_1.3.tar.gz file is in your current working directory:
> install.packages("./RGoogleAnalytics_1.3.tar.gz",
↪repos=NULL, type="source")
The first time I tried to install it, I got the following error messages:
> install.packages("./RGoogleAnalytics_1.3.tar.gz",
↪repos=NULL, type="source")
Warning in install.packages("./RGoogleAnalytics_1.3.tar.gz",
↪repos = NULL, :
'lib = "/opt/local/Library/Frameworks/R.framework/Versions/
↪3.0/Resources/library"' is not writable
Would you like to use a personal library instead? (y/n) y
Would you like to create a personal library
~/Library/R/3.0/library
to install packages into? (y/n) y
ERROR: dependencies 'rjson', 'RCurl'are not available for
↪package 'RGoogleAnalytics'
* removing '/Users/mtsouk/Library/R/3.0/library/RGoogleAnalytics'
Warning message:
In install.packages("./RGoogleAnalytics_1.3.tar.gz",
↪repos = NULL, :
installation of package './RGoogleAnalytics_1.3.tar.gz'
↪had non-zero exit status
>
This error messages tells me I need to have the rjson and RCurl packages installed in advance. Both of them can be found on CRAN, and the following shows their installation process:
> install.packages('rjson')
Installing package into '/Users/mtsouk/Library/R/3.0/library'
(as 'lib' is unspecified)
...
...
The downloaded source packages are in
'/private/var/folders/9m/8b9b4ttn6gvbwg7drb2jcp540000gn/
↪T/RtmpIBUmtw/downloaded_packages'
> install.packages('RCurl')
Installing package into '/Users/mtsouk/Library/R/3.0/library'
(as 'lib' is unspecified)
also installing the dependency 'bitops'
trying URL 'http://cran.cc.uoc.gr/src/contrib/bitops_1.0-5.tar.gz'
Content type 'application/x-gzip' length 8518 bytes
opened URL
==================================================
downloaded 8518 bytes
trying URL 'http://cran.cc.uoc.gr/src/contrib/RCurl_1.95-4.1.tar.gz'
Content type 'application/x-gzip' length 870915 bytes (850 Kb)
opened URL
==================================================
downloaded 850 Kb
...
...
** building package indices
** installing vignettes
** testing if installed package can be loaded
* DONE (RCurl)
The downloaded source packages are in
'/private/var/folders/9m/8b9b4ttn6gvbwg7drb2jcp540000gn/
↪T/RtmpIBUmtw/downloaded_packages'
>
Finally, you can install the desired r-google-analytics R package without any problems:
> install.packages("./RGoogleAnalytics_1.3.tar.gz",
↪repos=NULL, type="source")
Installing package into '/Users/mtsouk/Library/R/3.0/library'
(as 'lib' is unspecified)
* installing *source* package 'RGoogleAnalytics' ...
** R
** preparing package for lazy loading
** help
*** installing help indices
** building package indices
** testing if installed package can be loaded
* DONE (RGoogleAnalytics)
>
The contents of the RGoogleAnalytics directory are the following:
-rw-r--r-- 1 mtsouk staff 902 Jun 6 23:01 DESCRIPTION -rw-r--r-- 1 mtsouk staff 2071 Jun 6 23:01 INDEX drwxr-xr-x 7 mtsouk staff 238 Jun 6 23:01 Meta -rw-r--r-- 1 mtsouk staff 30 Jun 6 23:01 NAMESPACE drwxr-xr-x 5 mtsouk staff 170 Jun 6 23:01 R drwxr-xr-x 7 mtsouk staff 238 Jun 6 23:01 help drwxr-xr-x 4 mtsouk staff 136 Jun 6 23:01 html
To make sure that the RGoogleAnalytics package is installed properly, run the following command inside the R shell:
> library("RGoogleAnalytics")
Loading required package: rjson
Loading required package: RCurl
Loading required package: bitops
If your output is similar to the above, everything is fine, and you are ready to continue with the rest of the article. As you also can see in this output, if you try to load the RGoogleAnalytics package, it automatically will load the rjson, RCurl and bitops packages, so you don't need to load them manually inside your R scripts.
The RGoogleAnalytics package consists of the following two classes:
R Google Analytics: this is the main R package class.
Query Builder: this class simplifies the creation of queries.
The following is an R script (saved as a file called GA.R) that uses the Google Analytics R package (the line numbers were added to refer to the R code—those need not to be typed):
1 require("RGoogleAnalytics")
2 query <- QueryBuilder()
3 access_token <- query$authorize()
4 ga <- RGoogleAnalytics()
5 ga.profiles <- ga$GetProfileData(access_token)
6 # ga.profiles
7 query$Init(start.date = "2013-03-01",
8 end.date = "2013-04-01",
9 dimensions = "ga:date,ga:pagePath",
10 metrics = "ga:visits,ga:pageviews,ga:timeOnPage",
11 sort = "ga:visits",
12 #filters="",
13 #segment="",
14 max.results = 99,
15 table.id = paste("ga:",ga.profiles$id[1],
↪sep="",collapse=","),
16 access_token=access_token)
17 ga.data <- ga$GetReportData(query)
18 # head(ga.data)
Let me explain the R script line by line:
1: the first command loads the RGoogleAnalytics library and its dependencies.
2: defines a QueryBuilder variable that will be used when defining the query.
3: this command gets the required access token that will be generated by Google (Figure 1). You need to log in to Google Analytics using your favorite Web browser. As you also can see in Figure 1, for security reasons, the provided access token expires if you do not refresh it.
4: creates a new Google Analytics API object.
5: gets the available profiles that are connected to the Google Analytics account.
6: prints the available profiles. This is an optional step and is commented out.
7–16: defines the Query that will be used. There are many parameters; go to https://developers.google.com/analytics/devguides to learn more about them.
17: files a request to get the data from the API.
18: allows you to look at the returned data. This is an optional step and is commented out (I think it's better to execute it manually).
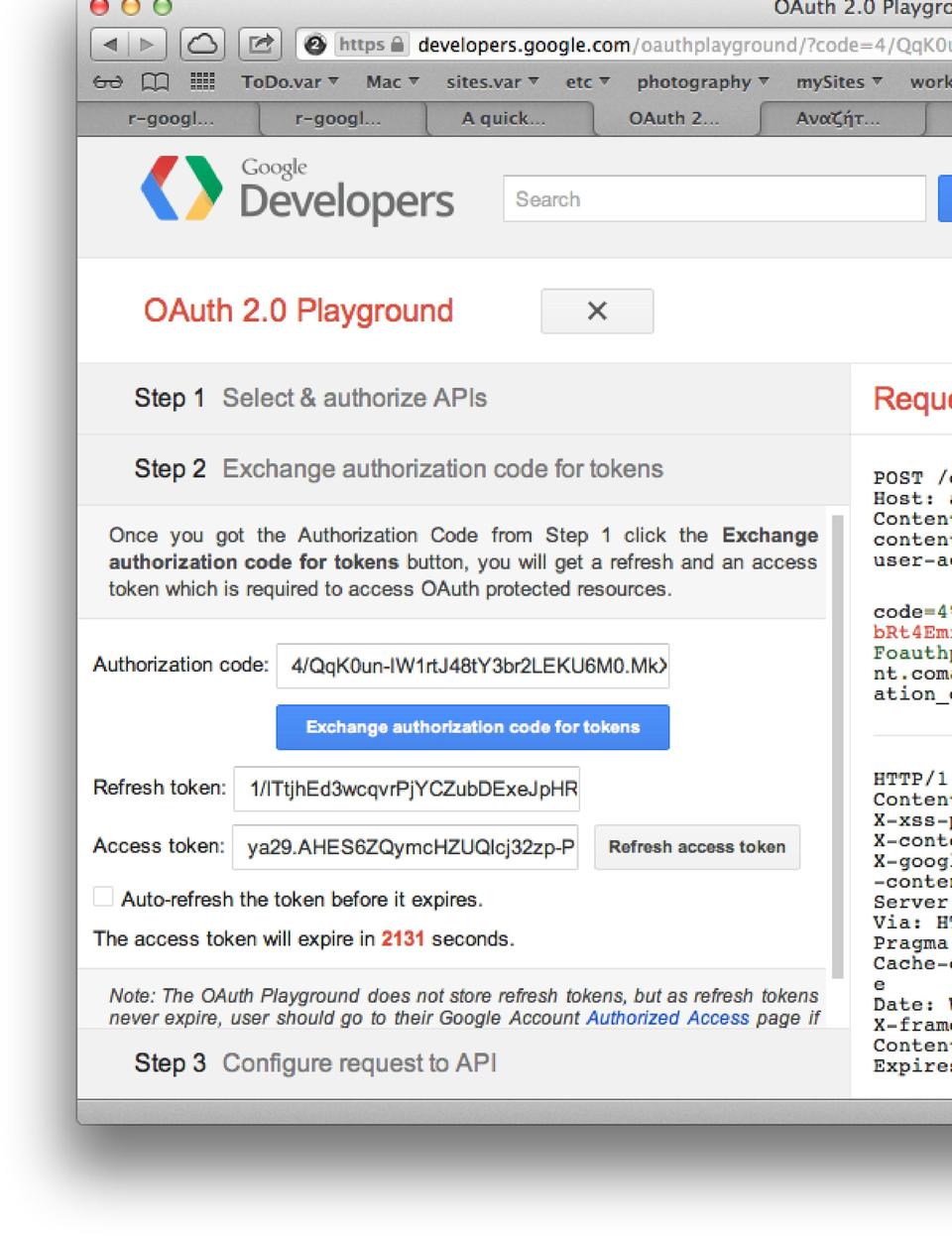
Figure 1. Input for the query$authorize() Command
In order to run the GA.R script, you can use the source() R command as follows (provided that GA.R is in your current working directory):
> source ("./GA.R")
Loading required package: RGoogleAnalytics
Loading required package: rjson
Loading required package: RCurl
Loading required package: bitops
The GA data extraction process requires an access token. To accept the access token from the Oauth 2.0 Playground, you need to follow certain steps in your browser. This access token will be valid only for one hour.
Here are the steps:
1) Authorize your Google Analytics account by providing your e-mail and password.
2) On the left side of the screen, click the button “Exchange authorization code for tokens” to generate the access token.
3) Copy the generated access token and paste it here:
:=>ya29.AHES6ZRvf0GqfI4yv2LvZXGIF2eGyz34nymGpRkll_4FOi9SFPsv1w [1] "Your query matched 99 results that are stored to ↪dataframe ga.data" >
The ga.profiles variable holds the following values:
> ga.profiles
id name
1 725011 users.sch.gr/tsoukalos/
2 725056 www.lprotopapas.gr
3 2780821 gym-ag-anarg.att.sch.gr/library/
4 2814395 gym-ag-anarg.att.sch.gr/
5 5793223 store.kagi.com
6 5921572 widgetbook.blogspot.com/
7 21911813 tsoukalosphotography.blogspot.com
8 50079161 Truth Target
The returned values are all the supported Google Analytics profiles that I have in my Google Analytics account.
The important thing to remember here is that you can access your Google Analytics data natively from R. What you can do with the data is up to your imagination.
This section describes how to extract useful information from a log file of an Apache Web server and analyze it using R. The name of the log file is www6.ex000704.log and is hard-coded inside the shell script. You should change its name it to match yours.
A (small) shell script (called www.sh) is used to extract the preferred information from the Apache log file. Here's the script:
#!/bin/bash
echo "Time" "ServerBytes" "ClientBytes" "StatusCode"
grep -v '^#' www6.ex000704.log | awk '{print $2, $10, $11, $9}'
↪| sed 's/:/ /g' |
awk '{print $1 ":" $2, $4, $5, "_"$6}'
The data is saved in a file called www.data using the following command:
$ ./www.sh > www.data
Here are the first ten lines of the www.data file so you can understand its format:
Time ServerBytes ClientBytes StatusCode 00:00 141 433 _304 00:00 142 437 _304 00:00 0 426 _200 00:00 142 435 _304 00:00 142 431 _304 00:00 114096 465 _200 00:00 141 436 _304 00:00 0 295 _200 00:00 141 434 _304
Note that the underscore in front of the status code was added by the www.sh script so that the StatusCode will not be considered a numeric value by R. The read.table() command is used to read the www.data file and import the data. Then the summary() command is used to get a general overview of the WWWDATA data set:
> WWWDATA <- read.table("./www.data", header=TRUE )
> summary(WWWDATA)
Time ServerBytes ClientBytes StatusCode
10:46 : 3145 Min. : 0 Min. : 0.0 _304 :709255
10:58 : 3081 1st Qu.: 140 1st Qu.: 401.0 _200 :435146
10:55 : 3066 Median : 142 Median : 435.0 _302 : 7371
10:37 : 3054 Mean : 2460 Mean : 438.1 _404 : 4641
10:32 : 2959 3rd Qu.: 407 3rd Qu.: 470.0 _500 : 3983
09:30 : 2814 Max. :49083902 Max. :2158.0 _206 : 2254
(Other):1144676 (Other): 145
>
The following statistical definitions will help you better understand the output of the summary() command:
Min.: the minimum value of the whole data set.
Median: an element that divides the data set into two subsets (left and right subsets) with the same number of elements. If the data set has an odd number of elements, the Median is part of the data set. On the other hand, if the data set has an even number of elements, the Median is the mean value of the two center elements of the data set.
1st Qu.: the 1st Quartile (q1) is a value that does not necessarily belong to the data set, with the property that, at most, 25% of the data set values are smaller than q1, and, at most, 75% of the data set values are bigger than q1. Or more simply, you can consider it as the Median value of the left-half subset of the sorted data set. If the number of elements of the data set is such that q1 does not belong to the data set, it is produced by interpolating the two values at the left (v) and the right (w) of its position to the sorted data set as: q1 = 0.75 * v + 0.25 * w.
Mean: the mean value of the data set (the sum of all values divided by the number of the items in the data set).
3rd Qu.: the 3rd Quartile (q3) is a value not necessarily belonging to the data set, with the property that, at most, 75% of the data set values are smaller than q3, and, at most, 25% of the data set values are larger than q3. Put simply, you can consider the 3rd Quartile as the Median of the right-half subset of the sorted data set. If the number of elements of the data set is such that q3 does not belong to the data set, it is produced by interpolation of the two values at the left (v) and the right (w) of its position to the sorted data set as: q3 = 0.25 * v + 0.75 * w.
Max.: the maximum value found in the data set. Note that many practices exist for finding Quartiles. If you try another statistical package, you may get slightly different results.
The summary() command provides very useful information about the data set. Above, you can see that the busiest minute was 10:46 when 3145 requests were served. You also can see that there were 4641 “Not found” error messages (denoted by the 404 StatusCode number) out of a total of about 1.1 million page requests.
The pairs() command produces an impressive matrix of scatterplots—a scatterplot is a diagram that uses Cartesian coordinates to display values for two variables for a set of data. It helps you get a quick visual overview of your data:
> pairs(WWWDATA)
Figure 2 shows the output of the pairs() command, which is impressive! As WWWDATA is a large data set, I had to wait a couple minutes for the pairs(WWWDATA) command to finish and produce its scatterplots.

Figure 2. The pairs(WWWDATA) Command Output
R also can communicate natively with many database management systems. For simplicity's sake, the database I use here is SQLite3; other popular supported options include MySQL, H2 and PostgreSQL.
SQLite is a public domain software library that implements a self-contained, serverless, zero-configuration, transactional SQL database engine. SQLite is the most widely deployed SQL database engine in the world. Its main advantage is that it does not need a server process to run. Its main disadvantage is that, for the same reason, it cannot operate with multiple users.
Let's create an SQLite3 database (a single file) using R commands, and then import the WWWDATA data set inside an SQLite3 table. Commas are used to separate the different column values, so the WWW.sh file needs to to change a little.
R can communicate with an SQLite3 database in two ways:
Using the RSQLite CRAN package, which you can install using the install.packages("RSQLite") R command.
Using the sqldf CRAN package (sqldf makes use of RSQLite, so installing sqldf also installs RSQLite). You can install it using the install.packages("sqldf") R command.
Both packages need the DBI R package, which, as you easily can understand, will be installed automatically before installing either of them. This example uses the sqldf package. Loading the sqldf package with the library() command produces the following output:
> library(sqldf) Loading required package: DBI Loading required package: gsubfn Loading required package: proto Loading required namespace: tcltk Loading required package: chron Loading required package: RSQLite Loading required package: RSQLite.extfuns >
The slightly changed www.sh script, called wwwcomma.sh, is the following:
#!/bin/bash
echo "Time," "ServerBytes," "ClientBytes," "StatusCode"
grep -v '^#' www6.ex000704.log | awk '{print $2, $10, $11, $9}'
↪| sed 's/:/ /g' |
awk '{print $1 ":" $2",", $4",", $5",", $6}'
The data is saved in a file called wwwcomma.data using the following command:
$ ./wwwcomma.sh > wwwcomma.data
The R script (named db.R) that does the job is the following (the line numbers are added for clarity and need not be typed):
1. library(sqldf)
2. db <- dbConnect(SQLite(), dbname="WWW.sqlite")
3. wwwdatacomma <- read.csv("wwwcomma.data")
4. dbWriteTable(conn = db, name = "WWW", value = wwwdatacomma,
↪RAW.NAMES=FALSE, APPEND=TRUE)
5. dbDisconnect(db)
Now, let's look at the R script line by line:
1: loads the required library.
2: creates a new database file called WWW.sqlite.
3: after creating the database file, it reads the wwwcommma.data CSV file into R and saves it into the wwwdatacomma variable.
4: imports the data frames into the database in a table called WWW.
5: closes the db connection.
Additional handy commands include dbListTables(db), which lists all the tables in a database using the db database connection; dbListFields(db, "WWW"), which lists all the fields of the WWW table using the db connection; and dbReadTable(db, "WWW"), which is like executing Select * from WWW using the db database connection. If your table is too populated, expect to see many lines of output.
You also can run SQL commands, such as the following, without opening a database connection by directly accessing the SQLite database file:
> q <- sqldf("SELECT count(*) FROM WWW", dbname = "WWW.sqlite")
Loading required package: tcltk
> q
count(*)
1 1162795
So, the important thing to remember here is that you now can use all the available SQLite3 commands natively from within the R package!
Even if you are leery of mathematics and statistics, it's a good idea to become familiar with R. R can provide a different perspective of your data that can be pretty as well as informative.
This article is just the beginning of data analysis using R. R has many more uses and features than I could show in a single article, and you should start experimenting with it.
