
There are now four ways we can protect our privacy online: encryption, agreements, fiduciaries and laws. Three of those are new.
The internet didn't come with privacy, any more than the planet did. But at least the planet had nature, which provided raw materials for the privacy technologies we call clothing and shelter. On the net, we use human nature to make our own raw materials. Those include code, protocols, standards, frameworks and best practices, such as those behind free and open-source software.
So far, our best privacy tech is encryption. But I won't dwell on that one, because I assume all Linux Journal readers are experts at that. Instead, I want to visit three others, all of which are new.
The first is agreements.
The most popular informal agreements in the physical world are called secrets. These aren't especially enforceable, but they are backed by norms, which are powerful constraints operating in a social context. For example, we trust that people, other than the intended recipient, won't open a sealed envelope, even if they can. The seal (such as the one shown in Figure 1) signals secrecy and has been in use for hundreds of years.

Figure 1. Seal Signaling Secrecy
More formal are the legal agreements we call terms. We encounter these every time we click “agree” to something that looks like what is shown in Figure 2.

Figure 2. The Legal Agreements We Call Terms
Did you read that? Go back and try reading it again.
These are “contracts of adhesion”, defined (by the Legal Dictionary) as “a standardized contract offered to consumers on a 'take it or leave it' basis without giving the consumer an opportunity to bargain for terms that are more favorable” (legaldictionary.net/adhesion-contract). After industry won the industrial revolution, large companies needed to create legal agreements for dealing with up to millions of customers. Contracts of adhesion were the only way. Alas, this also sidelined freedom of contract (www.lawteacher.net/free-law-essays/contract-law/the-doctrine-of-freedom-of-contract.php), “which allows parties to provide for the terms and conditions that will govern the relationship” (says LawTeacher.net).
But now we have the internet, a natural heterarchy (www.linuxjournal.com/content/opening-minds-spheres-among-us) defined by protocols that start by assuming that every entity on it is both free to participate and a peer. In this world we can bring back freedom of contract by writing code that gives each of us ways to make and assert our own terms, and to apply leverage as well—in other words, to give us scale, as first parties. The second parties are companies we deal with, and which can agree to our terms. This isn't about turning the tables on companies, but rather setting a table that's flat, with both parties operating in a trusting way with each other.
To get this rolling, we now have Customer Commons (customercommons.org), which will do for personal terms what Creative Commons (https://creativecommons.org) does for copyright. Right now Customer Commons is co-baking standard terms with the Consent & Information Sharing Working Group at Kantara (https://kantarainitiative.org/confluence/display/infosharing/User+Submitted+Terms+project+overview). For example, see Figure 3 (customercommons.org/2016/01/04/terms-what-are-they-and-why-should-you-care).
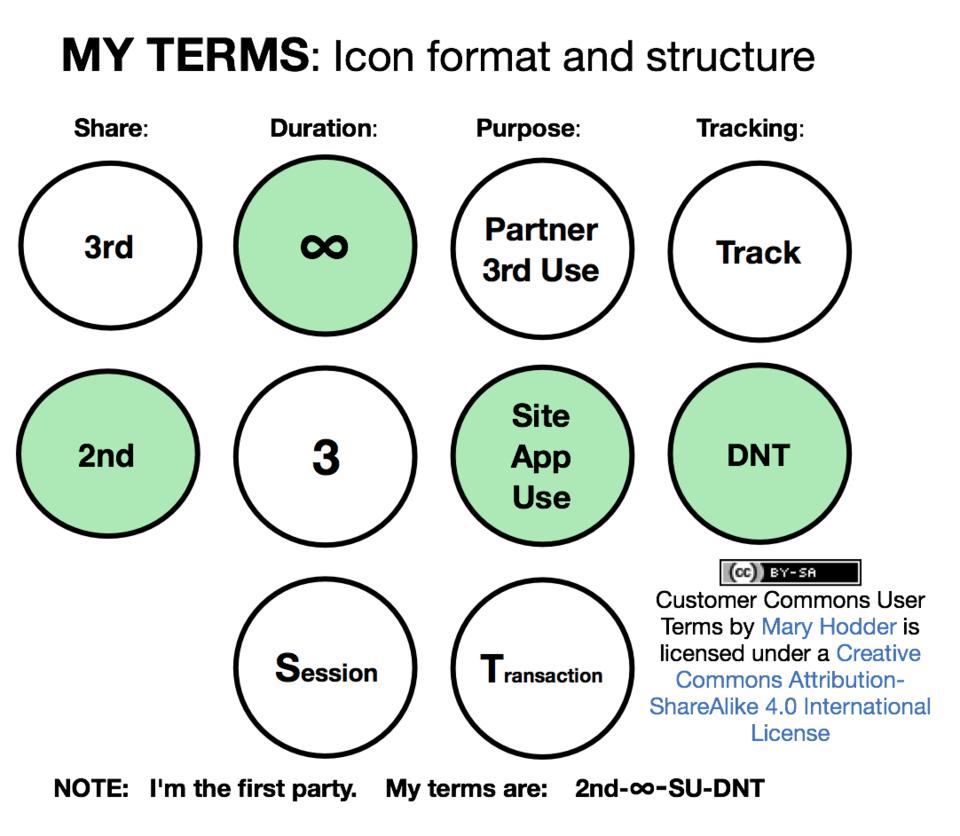
Figure 3. Customer Commons User Terms
In this example, the individual (as the first party) says personal data in a session is to be shared only with the second party (the website) for site use only, and to obey the Do Not Track request (https://en.wikipedia.org/wiki/Do_Not_Track) expressed by the HTTP header in the individual's browser.
Another one is #NoStalking (customercommons.org/2016/07/15/latest-draft-of-the-no-stalking-for-advertising-term-v-2), shown in Figure 4, copied off a whiteboard last May at VRM Day (https://www.flickr.com/photos/docsearls/sets/72157668230728355).

Figure 4. #NoStalking
While Do Not Track, tracking protection and ad blocking have prophylactic effects on privacy threats to individuals, #NoStalking works as a peace offering to publishers in the midst of the “war” over ad blocking (blogs.harvard.edu/doc/the-adblock-war). As I explain in “Why #NoStalking is a good deal for publishers” (blogs.harvard.edu/vrm/2016/05/11/why-a-nostalking-deal-is-good-for-publishers), “it's a good one for both sides. Individuals proffering the #NoStalking term get guilt-free use of the goods they come to the publisher for, and the publisher gets to stay in business—and improve that business by running advertising that is actually valued by its recipients.”
By valued I mean not based on tracking. As Don Marti (zgp.org/~dmarti) explains in “Targeted Advertising Considered Harmful” (zgp.org/targeted-advertising-considered-harmful), “The more targetable that an ad medium is, the less it's worth.” That's because non-targeted (that is, non-tracking-based) ads support the value of the publication they sponsor while also being supported by it. As Don puts it, non-targeted ads carry an economic signal (https://en.wikipedia.org/wiki/Signalling_%28economics%29), which “is proportional to the value of the content, not just the ad itself”. So, when your browser tells a publisher you want #NoStalking from them, and the publisher agrees, you know that the ads you'll see are ones that value the content you came to the site for, rather than ones based on robotic surveillance of your life online, and likely to have little or nothing to do with the value of publication itself (serving, as it does, only as a sluice of convenience for advertising messages). It also says both the publication and the advertiser value your privacy.
The third privacy protection comes through fiduciaries. This is both an old and a new idea. In their book Net Worth: Shaping Markets When Customers Make the Rules (Harvard Business Review Press, 1999, https://www.amazon.com/Net-Worth-Shaping-Markets-Customers/dp/0875848893), John Hagel and Marc Singer coined the term infomediary, for “a trusted third party” or “a kind of agent” that will “become the custodians and brokers of customer information”. In “A Grand Bargain to Make Tech Companies Trustworthy” (The Atlantic, October 3, 2016, www.theatlantic.com/technology/archive/2016/10/information-fiduciary/502346), law professors Jack Balkin of Yale (https://www.law.yale.edu/jack-m-balkin) and Jonathan Zittrain of Harvard (hls.harvard.edu/faculty/directory/10992/Zittrain) advance the concept of an information fiduciary: “a person or business that deals not in money but in information”. Like doctors, lawyers and accountants, fiduciaries “have to keep our secrets and they can't use the information they collect about us against our interests”. This gives companies like Facebook and Google a job they didn't know they took on when they began to gather mountains of personal information about us. “The important question is whether these businesses, like older fiduciaries, have legal obligations to be trustworthy. The answer is that they should.”
This is a legal and rhetorical hack of the first water. Brilliant.
It also nicely frames up advances in regulation, which is the fourth form of privacy protection. In Australia and the European Union, personal data protection is already baked into in laws imposing strong privacy protection obligations on those collecting personal data about us. Of special interest is the General Data Protection Regulation (https://en.wikipedia.org/wiki/General_Data_Protection_Regulation), aka the GDPR, in the EU. Search on Google for https://www.google.com/search?q=General+Data+Protection+Regulation, and you'll have to look down past a pile of advertising toward “compliance” offices at big companies before you get to the link I just used (to the GDPR's Wikipedia article). That's because the sanctions imposed on violators (https://en.wikipedia.org/wiki/General_Data_Protection_Regulation#Sanctions) include “a fine up to 20,000,000 EUR, or in the case of an undertaking, up to 4% of the total worldwide annual turnover of the preceding financial year, whichever is higher” (Article 83, Paragraph 5 & 6). That doesn't hit until 2018, but it's a big ouch in the meantime. But, with the looming threat of GDPR enforcement, new terms coming from the individual (another great hack) can offer genuine relief, even if lawmakers didn't see them coming. (Note that I avoid the term “user”. That's because “user” positions the individual as the subordinate party, always “using” something provided by others. When the individual is the first party, sites and services such as those addressed by the GDPR are the actual users of personal data, and of terms to which they agree before using that data.)
On page 121 of Free Culture (Penguin Press, 2004, www.free-culture.cc/freeculture.pdf), Lawrence Lessig introduced a diagram that has since attained the status of canon (Figure 5).
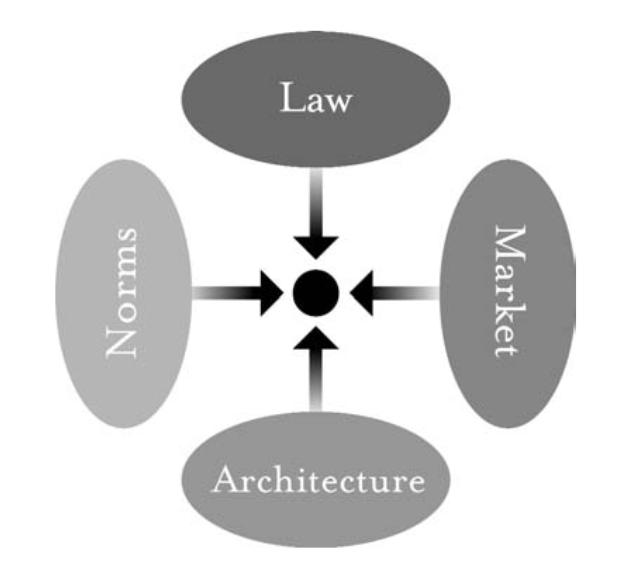
Figure 5. Lawrence Lessig's Diagram of the Individual as the Target of Regulation
Below it he explains, “At the center of this picture is a regulated dot: the individual or group that is the target of regulation, or the holder of a right....The ovals represent four ways in which the individual or group might be regulated—either constrained or, alternatively, enabled.”
We're talking about enablement here, and the assertion of rights. So think of those arrows pointing outward from the individual, influencing all four of those domains.
So how do these four approaches to privacy protection match up with those domains? Encryption is pure architecture. Balkin and Zittrain's fiduciary hack is on norms and law. New privacy rules such as the GDPR are already law. And terms proffered by individuals, in a freedom-of-contract way, are laws of their own, supported by architecture in the form of code, and influencing both norms and the market as well.
The result will be privacy that's as casual and uncontroversial online as it is in the offline world. But first we have to finish scaling up terms and the code and protocols required to make them work. Those four domains aren't going to fix themselves.
