
We chose open-source tools for their superior quality, not because they're free. It turned out we needed some closed source tools as well.
Heart diseases are common all over the world. They lower life expectancy and quality, and weigh heavily upon healthcare budgets. At the HAGA teaching hospital in The Hague, we're developing a software package named Sculptor, which allows detailed localization of heart problems while avoiding exploratory surgery. Development took us along a path that involved both Linux and Windows. I share our experiences in this article.
Apart from being a pump, the heart is a current generator. To find out what's wrong with it, a cardiologist needs a 3D image of its electrical behavior. To obtain this image from skin electrodes, we had to turn around the path traveled by the electrical signals from heart to body surface. This “inverse problem”, as mathematicians call it, requires solving a set of equations that have been known since the time of Faraday.
On their way to the body surface, the electrical signals undergo the influence of the organs they meet. Until recently, it was hard to visualize this influence, but with the availability of more and more computing power on the desktop, it is possible to generate a 3D map that exactly shows how the lungs, the spine and the chest bone bend the electrical currents. To trace the signal path, we overlay a 3D grid on the heart, using the splendid GMSH open-source package that has been under development for many years.
We then apply a mathematical trick we took from construction engineering to solve the equations. Fenics-Dolphin, another great open-source package developed in an international cooperation of four universities, helps achieve this feat. Both packages are part of some Linux distributions, and they can be installed on others easily.
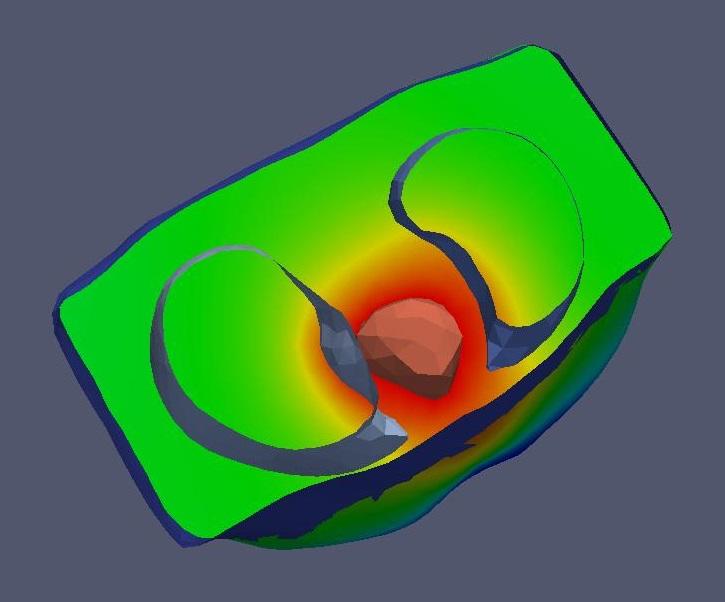
Figure 1. Electrical Field of the Heart Penetrating the Lungs (Top View)
To fine-tune our equations, we also needed a method to guide the flow of electrical currents inside the heart itself. For this, we use a combination of two algorithms, both of which are open source. To keep the electric currents inside the conductive parts of the heart, we use a gem from the computer game industry: the Moeller-Trumbore triangle intersection algorithm. To make sure the electrical signals travel straight to their targets, we use another popular recipe, although few know its name: the Floyd-Warshall shortest path algorithm. This algorithm and its cousin, the Dijkstra shortest path algorithm, are routinely used in car navigation systems. So, no rocket science.
Algorithms, algorithms, algorithms—fast, well documented, resulting from years of dedicated research work, with implementations available for free on Linux—we felt like kids in a candy shop. Why write anything ourselves? It looked like open source had all we needed. The main thing we had to do was tie it together, which, we thought, would be simple. But, it wasn't. We had underestimated this hidden booby trap of software engineering: accumulated complexity. We had pieces of knitted Matlab code, featuring fuzzy module boundaries and cryptic one-letter variable names. We had lumps of archaic Kernighan and Ritchie C code, littered with macros. We even had some well conserved Fortran IV code, shouting at us in all capitals. Call sequences, memory models and tool versions to compile the whole bunch were all incompatible.
In short, we had a set of beautiful Christmas balls, but how to hang them on one single tree—that was the question. Early attempts had used a lot of messy glue code, and our first task was to scrape the glue off the balls and give them all the same hooks: a clean interface. Matlab, Fortran and C balls were all converted to C++, sticking to the solid concepts of object orientation: encapsulation, inheritance and polymorphism, but avoiding the jungle of template- and overload resolution.
Oh yes, and there was this one ball we didn't yet have: we needed a simple, static 3D model of the heart tissue to allow for computing our currents. None of the many research articles we read had paid any attention to this step, so we assumed it was trivial and that something like Blender could be used. Not so.
As it turned out, drawing up a 3D static model of the heart wasn't simple at all. We tried Blender and at least a dozen things, but they all failed at the task. The reason is that they were not made for computation but for visualization, typically involving steps like smoothing to make things look nice.
As I am writing this, I am sitting behind a steel desk, my bare wrists resting upon the surface. On my desk, there's a lamp with a power cord, running over the edge to a wall outlet. Now suppose I want to draw up a 3D model of that desk, including the lamp and the power cord. The model is built out of tiny triangles and is smoothed to look good, with tiny gaps puttied automatically. For visualization, this model is great. But unfortunately, the smoothing closed one gap too many: the tiny gap between the copper core of the power cord and the edge of my desk, originally separated by a tenth of an inch of plastic insulator material. From an aesthetic point of view, my model is great. But from an electrical point of view, it's completely worthless. The distinction between typing quietly and being subjected to the full power-grid voltage on my wrists is what scientists would call “a significant difference”.
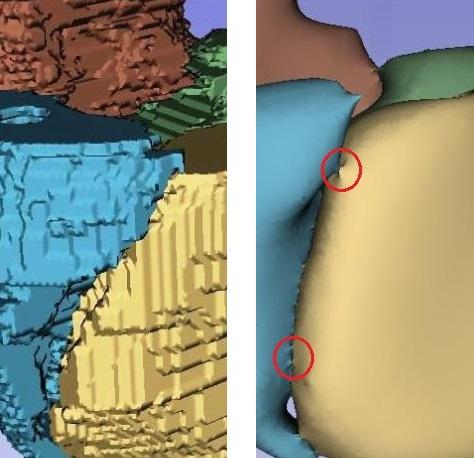
Figure 2. Smoothing causes short-circuits between tissue patches.
What this meant for us is that, although tools like Blender give nice-looking results, they only rarely produce something accurate enough for simulation of electrical behavior. There are many (open-source, you guessed it) tools to repair small defects in 3D models, and we spent at least two months trying them in every possible combination. In the end, we had to admit total failure, and we concluded that we had to make this Christmas ball ourselves. We decided upon Python, NumPy and OpenGL to do it. To be able to read images generated by an MRI scanner, we needed another open-source package called PyDicom.
By now our software depended upon a large number of open-source components, some of them mainstream, some of them less so. Having installed several versions of Ubuntu on a diversity of hardware in the course of the project, something else became clear: although kernel versions followed a single upward-bound track, Linux distributions as a whole were more like a grab bag filled by a drunken Santa Claus. Sometimes basic tools were completely lacking; sometimes several incompatible versions were on the same distribution.
We spent quite some time composing our own “standard distribution” on one of our machines, and we were nearly there when we decided to replace Python 2.7 with the Conda Python 3.5 distribution, which includes OpenGL, Numpy and even PyDicom. As Python 2.7 kept popping up at unexpected moments, we uninstalled it...which left us with a Linux that could just barely bring up a command-line console. Since installing everything properly had taken so much time, we attempted to repair our installation, spending hours reading about the adventures of other developers as laid down on Stack Overflow. In the end, we had to give up. Simply uninstalling a development tool turned out to have wrecked our OS beyond repair by mere mortals.
That wasn't all bad. We decided to grab the opportunity to make the move from Ubuntu 12 to Ubuntu 14, which had newer versions of nearly everything we needed—yet another mistake. Fenics-Dolphin turned out to depend on Python 2.7, which it couldn't find, since it wasn't the default anymore. The GCC C++ compiler had become more picky and refused several constructs for reasons that we have yet to understand. CLang was said to be the solution, and indeed, it was better at some points, but worse at others.
To cut a long story short, we had poured months into development of software that we planned to use for five to ten years at least, but installing a new Linux version after only a year left us with a dysfunctional system that was near to impossible to repair. What to expect in three years? Or six? With regard to every component we used, we had to pose one serious question: will it still be here next year? After reading through many blogs about life-cycle policies, we finally came up with a clear conclusion: 1) We don't know. 2) Nobody knows. It's hard to base a multi-year investment decision on that. Choosing to stay with a fixed set of legacy tools eventually would cut us off from new developments, which in the case of research, isn't an option. Using state-of-the-art tools would cripple our system over and over again.
The only viable path out of this dilemma was to start with a very bare-bones Linux and follow a rigid script to install exactly everything we wanted in exactly the right order, manually accounting for uncharted dependencies. In the end, it worked out. We now can install the newest version of everything we need on any system capable of running it. But the illusion that Linux is a kind of prepackaged development paradise fell to pieces. We all love Linux, and we know we aren't full-time system administrators. But surely the Linux world could benefit from some unification and clear policies in this area.
Computations are best done on one or more Linux boxes, but physicians are used to Windows. That's one problem we still had to solve. The other problem was about the one missing Christmas ball: obtaining an accurate static 3D model of the heart without short circuits. We embarked on writing this missing ball, and since Windows was available on every laptop in the hospital, we started development in the closed-source world. No problem—Python, C++ and OpenGL were all platform-independent, so once everything was ready, we would just recompile for Linux. We thought.
It took us three months to develop a fast, reliable application to draw up the required accurate 3D models from fuzzy, misaligned MRI scans. Obtaining a good model for each patient requires human intervention, and since radiologists were to spend many hours using this application, we paid attention to things like minimizing the number of mouse clicks and allowing intuitive manipulation of the anatomical parts that make up the heart. We could remove valves, leave out the atria or the ventricles, look from the inside out and so on—all of this fast and in high resolution. Doctoral researchers loved the result and spent many hours drawing up topologically correct models of hearts of men, women and children—a whole stock of them.

Figure 3. Electrical Activity in a Male Adult Heart, Viewed from the Inside
The disappointment indeed came when we wanted to move this ball to our Linux Christmas tree. Suddenly our graphics were slow, memory corruption occurred frequently, and weird striping patterns haunted our displays. We didn't panic. This must be just a matter of getting the right drivers. We thought. This is one area where long-standing cooperation between hardware and software manufacturers has paid off in the Windows world. Being able to entertain such a stable cooperation between separate industries is one of the benefits of the contract-driven closed-source world, and it is not to be underestimated. If you buy a Windows box, you can be quite certain all capabilities of the graphics card are used to their utmost. For Linux, it's different.
Since we already had learned enough to doubt our capacities as system administrators, we sought specialist help on this one. The result didn't please us. Making the most of a state-of-the-art graphics card in Linux is often just impossible. The drivers aren't there, or they're buggy, or they refuse to cooperate with the Linux distro at hand—many reasons that in the end all boil down to the same response: forget it. Oh yes, results sometimes were quite nice. But currently I am staring at the screen of a stereovision laptop, wirelessly controlling a pair of NVIDIA shutter glasses. The results on Windows for our heart models are stunning; seeing depth really makes interpretation of disease patterns much easier. Only, after three years, we couldn't make it run on Linux. Shame on us.
Since physicians prefer Windows anyhow, and in the end, our computations will run remotely on a cluster, we decided to have the GUI part running on Windows and the computational back end on Linux, not an unusual combination. For synchronization, we considered dinosaurs like CORBA and mouses like JSON, but finally settled for simple file versioning and locking, which worked flawlessly, even over a network. For demonstration purposes, we still wanted it all to run on one (very fast) laptop. A dual-boot system was no help; we needed Linux and Windows to cooperate, running simultaneously. VMware Player made it possible, and finally, we had the system of our dreams: razor-sharp visualization with stereovision capabilities under Windows, open-source computational tools running efficiently on a quad core under Linux on the same machine and standardization on two mainstream, highly complementary languages: C++ for fast execution and Python for fast development. I dare say we were pleased with the result. The next step was scaling up our research.
As the first publications were accepted by science journals, we were open to future international cooperation. There were several candidates inside and outside Europe. Even though we'd documented it well, our complicated setup could become a problem. The Netherlands are small, and if someone has an installation problem that can't be solved using a remote desktop, it's at most a short drive to provide personal assistance. Reliably deploying and supporting a setup over the borders is an entirely different matter. This made us think about thin clients and a browser GUI. For a start, we reserved a few URLs and began to look into security regulations for patient data.
Since we already had separated computation and visualization, having the latter run in a browser seemed doable. Not without reason, we'd chosen something ubiquitously supported like OpenGL. While getting OpenGL to run in a browser proved simple, our interactive 3D modelling Python code certainly wasn't. We did some experiments in JavaScript, but things like class-based object orientation and multiple inheritance were embedded so deeply in our thinking, that using JavaScript for this sent us back to square number one. So we looked into some alternatives, most notably Pythons that could run in the browser. We found several, some requiring special browser plugins, others producing slow, bulky code, yet others lean and mean but lacking some of the basic Python features we needed.
So we had to roll our own. Having such positive experiences with open source, it seemed only logical to choose this path ourselves. We embarked on developing an open-source Python-to-JavaScript compiler called Transcrypt, which was able to run our graphics routines. We wanted it to be fast, compact and able to use any JavaScript graphics library. The first versions uploaded to GitHub were accompanied by the warning that the code was unfit for any serious use and might go away any moment. But, that changed earlier than we had expected. Writing a compiler is a well documented undertaking, and Python itself comes with an excellent parser, so in a few months' time, we had all the functionality we ourselves needed. Execution speed and code size matched JavaScript, and we were quite satisfied. Since we didn't plan to go any further, we referred to our tool as a “Small Sane Subset” compiler. That was when the dynamics of open source took over.
Figure 4. Class-Based Object Orientation in the Browser
People started to notice our little compiler; they even used it professionally, and our first GitHub stars were acquired. Feature requests came in. Could you build in this? Could you build in that? It all wasn't too hard, and some of the new stuff we could use ourselves. Although Transcrypt was open source from the start, and its development decoupled from Sculptor, it now gained momentum of its own. Some very experienced and competent developers from all over the world made large contributions, and people started to use it for a diversity of projects, every bit as serious as our research. It was pure fun, and on top of that, it took away our last reservations about Linux in particular and open source in general. We clearly had been drawn into something bigger than ourselves.
Up to this point, we'd always wondered about reliability. Just how reliable can anything as complex and vulnerable as an operating system be, if it's developed in a loose cooperation of hundreds of developers that may withdraw their support at any time? How about code quality? How about continuity? From experience, we now can tell the answer. Let me make this personal. For some 35 years I've been a lead developer in many teams with many companies large and small, but I've never encountered such craftsmanship, such dedication, such enthusiasm, such energy and such a sense of responsibility as in the open-source world. Here's a message to any company still shy of trying: there's a world of competent, top-notch developers out there. Do you think you can survive without them, creating your own proprietary world with ten, 20, 100 developers being managed hierarchically? You don't stand a chance. It's as simple as that.
