
Playbooks make Ansible even more powerful than before.
To be quite honest, if Ansible had nothing but its ad-hoc mode, it still would be a powerful and useful tool for automating large numbers of computers. In fact, if it weren't for a few features, I might consider sticking with ad-hoc mode and adding a bunch of those ad-hoc commands to a Bash script and be done with learning. Those few additional features, however, make the continued effort well worth it.
Ansible goes out of its way to use an easy-to-read configuration file for making “playbooks”, which are files full of separate Ansible “tasks”. A task is basically an ad-hoc command written out in a configuration file that makes it more organized and easy to expand. The configuration files use YAML, which stands for “Yet Another Markup Language”. It's an easy-to-read markup language, but it does rely on whitespace, which isn't terribly common with most config files. A simple playbook looks something like this:
---
- hosts: webservers
become: yes
tasks:
- name: this installs a package
apt: name=apache2 update_cache=yes state=latest
- name: this restarts the apache service
service: name=apache2 enabled=yes state=restarted
The contents should be fairly easy to identify. It's basically two ad-hoc commands broken up into a YAML configuration file. There are a few important things to notice. First, every filename ends with .yaml, and every YAML file must begin with three hyphen characters. Also, as mentioned above, whitespace matters. Finally, when a hyphen should precede a section and when it should just be spaced appropriately often is confusing. Basically every new section needs to start with a - symbol, but it's often hard to tell what should be its own section. Nevertheless, it starts to feel natural as you create more and more playbooks.
The above playbook would be executed by typing:
ansible-playbook filename.yaml
And that is the equivalent of these two commands:
ansible webservers -b -m apt -a "name=apache2 ↪update_cache=yes state=latest" ansible webservers -b -m service -a "name=apache2 ↪enabled=yes state=restarted"
But a bit of organization is really only the beginning of why playbooks are so powerful. First off, there's the idea of “Handlers”, which are tasks that are executed only when “notified” that a task has made a change. How does that work exactly? Let's rewrite the above YAML file to make the second task a handler:
---
- hosts: webservers
become: yes
tasks:
- name: this installs a package
apt: name=apache2 update_cache=yes state=latest
notify: enable apache
handlers:
- name: enable apache
service: name=apache2 enabled=yes state=started
On the surface, this looks very similar to just executing multiple tasks. When the first task (installing Apache) executes, if a change is made, it notifies the “enable apache” handler, which makes sure Apache is enabled on boot and currently running. The significance is that if Apache is already installed, and no changes are made, the handler never is called. That makes the code much more efficient, but it also means no unnecessary interruption of the already running Apache process.
There are other subtle time-saving issues with handlers too—for example, multiple tasks can call a handler, but it executes only a single time regardless of how many times it's called. But the really significant thing to remember is that handlers are executed (notified) only when an Ansible task makes a change on the remote system.
Variable substitution works quite simply inside a playbook. Here's a simple example:
---
- hosts: webservers
become: yes
vars:
package_name: apache2
tasks:
- name: this installs a package
apt: "name={{ package_name }} update_cache=yes state=latest"
notify: enable apache
handlers:
- name: enable apache
service: "name={{ package_name }} enabled=yes state=started"
It should be fairly easy to understand what's happening above. Note that I did put the entire module action section in quotes. It's not always required, but sometimes Ansible is funny about unquoted variable substitutions, so I always try to put things in quotes when variables are involved.
The really interesting thing about variables, however, are the “Gathered Facts” about every host. You might notice when executing a playbook that the first thing Ansible does is “Gathering Facts...”, which completes without error, but doesn't actually seem to do anything. What's really happening is that system information is getting populated into variables that can be used inside a playbook. To see the entire list of “Gathered Facts”, you can execute an ad-hoc command:
ansible webservers -m setup
You'll get a huge list of facts generated from the individual hosts. Some of them are particularly useful. For example, ansible_os_family will return something like “RedHat” or “Debian” depending on which distribution you're using. Ubuntu and Debian systems both return “Debian”, while Red Hat and CentOS will return “RedHat”. Although that's certainly interesting information, it's really useful when different distros use different tools—for example, apt vs. yum.
One of the frustrations of moving from Ansible ad-hoc commands to playbooks is that in playbook mode, Ansible tends to keep fairly quiet with regard to output. With ad-hoc mode, you often can see what is going on, but with a playbook, you know only if it finished okay, and if a change was made. There are two easy ways to change that. The first is just to add the -v flag when executing ansible-playbook. That adds verbosity and provides lots of feedback when things are executed. Unfortunately, it often gives so much information, that usefulness gets lost in the mix. Still, in a pinch, just adding the -v flag helps.
If you're creating a playbook and want to be notified of things along the way, the debug module is really your friend. In ad-hoc mode, the debug module doesn't make much sense to use, but in a playbook, it can act as a “reporting” tool about what is going on. For example:
---
- hosts: webservers
tasks:
- name: describe hosts
debug: msg="Computer {{ ansible_hostname }} is running
↪{{ ansible_os_family }} or equivalent"
The above will show you something like Figure 1, which is incredibly useful when you're trying to figure out the sort of systems you're using. The nice thing about the debug module is that it can display anything you want, so if a value changes, you can have it displayed on the screen so you can troubleshoot a playbook that isn't working like you expect it to work. It is important to note that the debug module doesn't do anything other than display information on the screen for you. It's not a logging system; rather, it's just a way to have information (customized information, unlike the verbose flag) displayed during execution. Still, it can be invaluable as your playbooks become more complex.
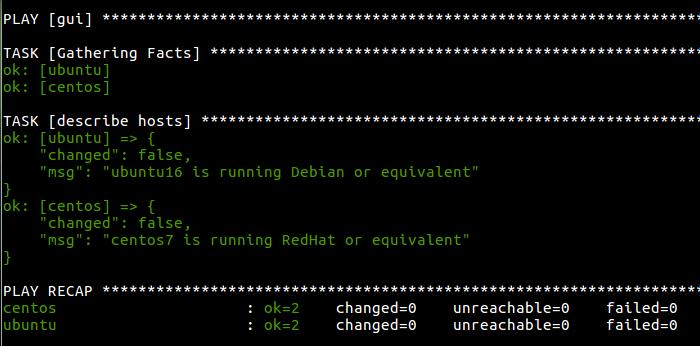
Figure 1. Debug mode is the best way to get some information on what's happening inside your playbooks.
Conditionals are a part of pretty much every programming language. Ansible YAML files also can take advantage of conditional execution, but the format is a little wacky. Normally the condition comes first, and then if it evaluates as true, the following code executes. With Ansible, it's a little backward. The task is completely spelled out, then a when statement is added at the end. It makes the code very readable, but as someone who's been using if/then mentality his entire career, it feels funny. Here's a slightly more complicated playbook. See if you can parse out what would happen in an environment with both Debian/Ubuntu and Red Hat/CentOS systems:
---
- hosts: webservers
become: yes
tasks:
- name: install apache this way
apt: name=apache2 update_cache=yes state=latest
notify: start apache2
when: ansible_os_family == "Debian"
- name: install apache that way
yum: name=httpd state=latest
notify: start httpd
when: ansible_os_family == "RedHat"
handlers:
- name: start apache2
service: name=apache2 enabled=yes state=started
- name: start httpd
service: name=httpd enabled=yes state=started
Hopefully the YAML format makes that fairly easy to read. Basically, it's a playbook that will install Apache on hosts using either yum or apt based on which type of distro they have installed. Then handlers make sure the newly installed packages are enabled and running.
It's easy to see how useful a combination of gathered facts and conditional statements can be. Thankfully, Ansible doesn't stop there. As with other configuration management systems, it includes most features of programming and scripting languages. For example, there are loops.
If there is one thing Ansible does well, it's loops. Quite frankly, it supports so many different sorts of loops, I can't cover them all here. The best way to figure out the perfect sort of loop for your situation is to read the Ansible documentation directly at docs.ansible.com/ansible/latest/playbooks_loops.html.
For simple lists, playbooks use a familiar, easy-to-read method for doing multiple tasks. For example:
---
- hosts: webservers
become: yes
tasks:
- name: install a bunch of stuff
apt: "name={{ item }} state=latest update_cache=yes"
with_items:
- apache2
- vim
- chromium-browser
This simple playbook will install multiple packages using the apt module. Note the special variable named item, which is replaced with the items one at a time in the with_items section. Again, this is pretty easy to understand and utilize in your own playbooks. Other loops work in similar ways, but they're formatted differently. Just check out the documentation for the wide variety of ways Ansible can repeat similar tasks.
One last module I find myself using often is the template module. If you've ever used mail merge in a word processor, templating works similarly. Basically, you create a text file and then use variable substitution to create a custom version on the fly. I most often do this for creating HTML files or config files. Ansible uses the Jinja2 templating language, which is conveniently similar to standard variable substitution in playbooks themselves. The example I almost always use is a custom HTML file that can be installed on a remote batch of web servers. Let's look at a fairly complex playbook and an accompanying HTML template file.
Here's the playbook:
---
- hosts: webservers
become: yes
tasks:
- name: install apache2
apt: name=apache2 state=latest update_cache=yes
when: ansible_os_family == "Debian"
- name: install httpd
yum: name=httpd state=latest
when: ansible_os_family == "RedHat"
- name: start apache2
service: name=apache2 state=started enable=yes
when: ansible_os_family == "Debian"
- name: start httpd
service: name=httpd state=started enable=yes
when: ansible_os_family == "RedHat
- name: install index
template:
src: index.html.j2
dest: /var/www/html/index.html
Here's the template file, which must end in .j2 (it's the file referenced in the last task above):
<html><center>
<h1>This computer is running {{ ansible_os_family }},
and its hostname is:</h1>
<h3>{{ ansible_hostname }}</h3>
{# this is a comment, which won't be copied to the index.html file #}
</center></html>
This also should be fairly easy to understand. The playbook takes a few different things it learned and installs Apache on the remote systems, regardless of whether they are Red Hat- or Debian-based. Then, it starts the web servers and makes sure the web server starts on system boot. Finally, the playbook takes the template file, index.html.j2, and substitutes the variables while copying the file to the remote system. Note the {# #} format for making comments. Those comments are completely erased on the remote system and are visible only in the .j2 file on the Ansible machine.
I'll finish up this series in my next article, where I plan to cover how to build on your playbook knowledge to create entire roles and take advantage of the community contributions available. Ansible is a very powerful tool that is surprisingly simple to understand and use. If you've been experimenting with ad-hoc commands, I encourage you to create playbooks that will allow you to do multiple tasks on a multitude of computers with minimal effort. At the very least, play around with the “Facts” gathered by the ansible-playbook app, because those are things unavailable to the ad-hoc mode of Ansible. Until next time, learn, experiment, play and have fun!
