
 | Chapter 1 PL/SQL Packages |  |
You will want to take maximum possible advantage of builtin and prebuilt packages. Soon, however, you will be building your own packages. This section explores syntax and issues related to package construction.
Remember that a package consists of up to two distinct parts: the specification and the body. The specification and body are completely distinct objects. You can write and compile the specification independently of the body. When you create and replace stored packages in the database, you perform this action separately for each specification and each body. The package specification describes the different elements of the package that can be called or referenced. The package body contains the implementation or executable code for the elements of the specification.
This chapter has already introduced to you the package specification. Before turning our attention to the package body, let's examine the circumstances under which you should consider building your own package.
When should you build a package, instead of just creating a set of standalone procedures and functions? Anyone who has attended any of my classes or presentations could probably guess my answer (or is it my dogma): Always! You should always build a package! A package is the answer to all of your problems in PL/SQL!
I do realize that my readers deserve a more reasoned and nuanced answer. So I'll review the reasons for building a package. I believe you will want to create a package whenever you find yourself in the following kinds of situations.
Do you have dozens, perhaps hundreds, of standalone functions and procedures stored in the database? Do you wonder if there is overlap between these programs? Do you have a sense that you have lost control of your development/stored code environment? The package construct can help bring everything into focus and get you and your code organized.
The package is the closest thing in PL/SQL (prior to PL/SQL Release 3) to an object. A package bundles together different -- usually related -- PL/SQL elements. Rather than have separate, standalone programs to maintain the contents of a particular table, to return information from that table and so on, you can place all of those programs within the context of the package. This simple transfer of code within the boundaries of a package makes it easier for you to manage all of your code. It will also be much, much easier for others to understand and maintain the code you have written.
So if you are new to packages and really do not believe that you have a grip on what is actually out there in the database, it would be a good time to analyze your stored code and reorganize it into a set of packages.
The data structures defined inside the body of packages are shared by (or accessible to) all elements of the package, but cannot be referenced outside of the package. This means that you can control tightly any access to your data. I recommend, in fact, that you never define variables and data structures in the specification of the package.
This advice applies not only to in-memory data defined inside the package, but also to table-based data in the Oracle Server. You can set up your environment so that users cannot access database tables directly for read or write purposes. You then create a package that maintains the data in the table. The owner of the package is given access to the underlying table. Finally, you grant execute authority on the package to the end users. Now all access to the table goes through the package. As a result, you can now use the PL/SQL language to apply business rules to all user-initiated transactions. This approach is particularly important when you use a third-party frontend tool like Gupta Corporation's SQL*Windows to access the Oracle database. You want to do everything you can to avoid hard-coding your data structures (in the form of SELECTs, INSERTs, and so on) into client-side code, whether in Oracle Developer/2000 or in SQL*Windows.
When you declare a variable in the specification of a package, that variable becomes, for all intents and purposes, a global variable within a given user session. It can be accessed by any PL/SQL program, regardless of where the variable was first referenced and assigned a value, as long as that program is run under the same session. (Note that you can make use of the DBMS_PIPE package to make data available across different Oracle sessions.)
If you declare a data structure inside the body of the package, that structure is still "global" -- but only within the package. It also persists for the duration of your session; in other words, the variable (whether scalar or composite) maintains its value until it is changed or until you disconnect.
If you need to define and then access persistent, global data in your session, the PL/SQL package is the only way to accomplish this particular trick. Common scenarios requiring global data include:
Configuration information for a session or even for an application. What is my printer name? What is the latest date allowed for entry of new orders?
Memory-based lists of information. Rather than having to constantly go back to the database to obtain and display a list of options, you can load these values into a PL/SQL table and then display those values. You will use more memory, but improve the performance of your application.
Running totals and other accumulated or derived values. Your application might perform lots of what-if analysis on current information in the database and new information entered by users. Package-based data structures can be used to keep track of derived, analytical values until they are ready to be saved to the database or discarded when the session ends.
We all know that you should never, or hardly ever, put hard-coded literal values in your application code.
One of the most common causes for program failure is, I believe, the undying belief by programmers that a particular value will never change and so can be hard-coded into a system. Why do we developers make this mistake again and again? I believe that it is a subconscious reaction to the fundamental uncertainty in our lives. Our end users change their minds about their specifications, requirements, and user interface preferences on a daily -- if not hourly -- basis. We can find no comfort, no security, from our users.
And what about our own IS management? CIOs and their architectures teams seem to always be discovering the next "silver bullet" methodology or application development tool -- and pulling the proverbial carpet out from under us.
So when you read in your application specifications that C will represent a "closed account," you are swept up by an irresistible urge to bet the house on that particular value not changing. But of course it will -- and your code will suffer for it.
You are much better off establishing a package of constants that holds all the application-wide and/or system-wide constants that you will be using. Then when you feel the need to hard-code a literal into your program, instead switch over to your constants package (I talk more about this in the "simultaneous package construction" best practice, described in the next chapter). Deposit the literal value there and give it a name with a CONSTANT declaration. From then on, reference the value by package constant name. If the value ever must be changed, you change it in the constants package specification, recompile all dependent programs, and you are done!
As an alternative, you can also define constants in the packages to which they relate. I have found that I will usually create a single, application-level package of constants if I am reviewing and cleaning up an existing application.
If you know that an aspect of your application -- or even the technology on which your application is based -- is volatile and bound to change, build a package around that functionality to protect your application from that volatility.
One of the most volatile areas of an application is its underlying data structures. Many developers tend to think of the database -- all those tables, primary keys, constraints and so forth -- as the bedrock of the application. Now, it is true that these data structures are the foundation upon which most code is built. But it is most definitely not true that this foundation is unchanging. The entity-relationship diagram (ERD) maps the real world to the relational world.
The real world -- at least as perceived by our users -- is a moving target. New or changed tables, modified columns, evolving relationships: these are an everyday element of our work. They are also one of the most complicated aspects of our development. It is not unusual, for instance, to require triple and quadruple joins of tables to retrieve the most basic information about an entity.
So, yes, you have to build your applications on top of these data structures, but you do not have to do so in a blind and short-sighted manner. There are two approaches you can take to deal with the complexity and volatility:
Option 1. Train all of your developers about all the subtleties of your organization's data. You will, of course, need to keep training them as your data structures change over time.
Option 2. Hide as many of these subtleties as you can, allowing your developers to work at a higher level of abstraction.
The optimal choice should be clear. While it is an admirable goal to educate everyone about every aspect of the work, it is simply not practical. You can use a package to encapsulate the triple joins and present a unified front to a developer. They can skip the complex SQL and apply the prebuilt package code to their needs much more quickly. Assume, in other words, that your structures will change. Protect your code (and your sanity) accordingly. Here are some recommendations to follow that employ the package to improve the robustness of your application:
Avoid implicit queries. When you write an implicit query, you place a SELECT statement directly in your program. You fetch data from the database directly into local PL/SQL variables. When you take this approach, you essentially hard-code your data structures into your programs. What happens when that two-table join turns into a six-table join? You have to find all those implicit queries and fix them.
Set as a general rule that developers do not write DML statements directly in their own applications. Again, if everyone is writing whatever SQL they find appropriate to their individual circumstances, you will end up with an application in which your entity relationships are distributed throughout your code. How do you maintain and upgrade such code to match your changing database? Instead...
Consolidate all of your SQL statements into one or more packages. Provide programmatic access to the SQL, or offer explicit cursors defined in the package. With this approach, you anticipate developer needs concerning the SQL layer. Will developers need to update the emp table with a new salary? Provide a procedure that does this. Do you need to query employees by decreasing salaries? Create an explicit cursor with this structure and let developers open and fetch from the cursor.
If you succeed in predefining and consolidating your SQL statements behind the package interface, you will have gone a long way towards making your application change-proof. This approach takes up-front planning and lots of discipline. You might even want to build scripts to query the contents of the USER_SOURCE data dictionary view to verify that DML statements do not appear outside of your SQL packages. In the long run, however, you will achieve higher productivity and higher code quality. Individual developers are liberated from writing complex, bug-prone SQL and instead concentrate on the user interface -- or whatever is the task at hand.
Every release of every piece of software comes with bugs, undocumented "features," and functionality that lacks, shall we say, a certain polish. You can whine about this situation, but sooner or later you have to deal with it. This usually means that you have to use elements of the language that are substandard. You will figure out the workaround or whatever compensation is necessary to keep the development process moving forward. At this point, you have two choices of how to apply this workaround:
Whenever you encounter the problem area, you code the workaround directly in the program.
You build a package that contains the workaround. The package specification provides the solution without revealing the nature of the workaround. It is hidden inside the body of the package.
In the first approach, which is almost always the route chosen, you hard-code the (usually temporary) drawback of the language directly in multiple places in your programs. When the upgrade to PL/SQL (or whatever language you are using) arrives at your installation, you have to hunt down every place you put the workaround and replace it with the new, fixed functionality.
With the second (package-based) approach, the code for the workaround is in one place only. When the patch tape or upgrade arrives, you make the change only inside the body of the package. All the code that called the package element to apply the workaround will now call that same package element, but this time use the new, fixed version.
If you build yourself a layer of code with a package that hides the implementation of workarounds, you can then easily and rapidly apply upgrades that completely obviate the need for the workaround.
To illustrate this technique, consider the task of clearing or emptying PL/SQL tables. Prior to Release 2.3 of PL/SQL, the only way to delete all rows from a PL/SQL table was to assign an empty table to the populated table. There is, in other words, no DELETE function or operator for PL/SQL tables. The PLVtab package of PL/Vision makes it as easy as possible for you to use PL/SQL tables by predefined table types in the package. To similarly ease the task of emptying tables, PLVtab provides an empty table for each table TYPE defined in the package. The PLVprsps.init_table procedure below shows how these elements are put to use in PL/Vision to delete all rows from a PL/SQL table:
PROCEDURE init_table
(tokens_out IN OUT PLVtab.vc2000_table,
num_tokens_out IN OUT INTEGER)
IS
BEGIN
tokens_out := PLVtab.empty_vc2000;
num_tokens_out := 0;
END;The problem with this approach is that it exposes the implementation of my workaround and makes it very difficult to upgrade this code to PL/SQL Release 2.3.
You see, PL/SQL Release 2.3 provides a DELETE method for PL/SQL tables. Rather than assigning an empty table to delete all rows from tokens_out, I could simply issue this statement:
tokens_out.DELETE;
I can certainly make this substitution in the init_table program, but in how many other places are these empty tables utilized? Taking a different approach within PLVtab would have left me in a much stronger position. Suppose that instead of providing a set of predefined empty tables, I built a series of procedures to empty the tables. The procedure to empty the VARCHAR2(2000) tables would look like this:
PROCEDURE empty (table_inout IN OUT PLVtab.vc2000_table) IS BEGIN tokens_inout := PLVtab.empty_vc2000; END;
and the init_table procedure would change to this:
PROCEDURE init_table
(tokens_out IN OUT PLVtab.vc2000_table,
num_tokens_out IN OUT INTEGER)
IS
BEGIN
PLVtab.empty (tokens_out);
num_tokens_out := 0;
END;Notice that there is no mention of the empty table outside of PLVtab. So when Release 2.3 comes along, I can change the empty procedure of PLVtab as follows:
PROCEDURE empty (table_inout IN OUT PLVtab.vc2000_table) IS
BEGIN tokens_inout.DELETE; END;
Like magic, without making any change to the PLVprsps.init_table procedure, it is now using the new capabilities of the PL/SQL language. This is just one very simple example of how you can and should use packages to make feasible the upgrade to new features and fixes to bugs.
There are many situations in PL/SQL development that cry out for a package. I hope the previous sections will help raise a flag as you proceed through your application development projects. Do you find yourself dealing repeatedly with some weakness in PL/SQL or another element of the Oracle product set? Are you writing the same complex SQL statement again and again in your code? Stop! Take the time required to bundle the logic, the flaws, the relationships into a package. The payoff will come instantaneously and continuously; the investment will never be regretted.
Once you have decided to build your package and constructed the interface (specification) for that package, you will then embark on constructing the guts of the package: its body.
The body of the package contains all the code behind the package specification: the implementation of the modules, cursors, and other elements. Whereas package specifications tend to be short and to the point ("here are the programs you can run and the data you can access"), package bodies can easily grow to intimidating length and complexity. Several coding recommendations presented in the next chapter address organizing your package bodies.
The packages of PL/Vision offer many examples of package bodies. Let's take a look now at a relatively simple package body. The package body shown below illustrates the code required to implement the specification of the sp_timer package shown earlier.
PACKAGE BODY sp_timer
IS
last_timing NUMBER := NULL;
PROCEDURE capture IS
BEGIN
last_timing := DBMS_UTILITY.GET_TIME;
END;
PROCEDURE show_elapsed IS
BEGIN
DBMS_OUTPUT.PUT_LINE
(DBMS_UTILITY.GET_TIME - last_timing);
END;
END sp_timer;Notice that the body contains a declaration of a local variable, last_timing. This variable does not appear in the specification; instead, it is referenced within capture (which sets the value of last_timing) and in show_elapsed (which references the variable). Consequently, the only programs that can directly reference the last_timing variable are capture and show_elapsed, as shown in Figure 1.4.
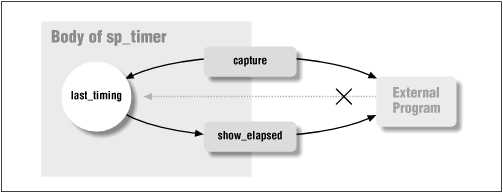
The body of the package resembles a standalone module's declaration section. It contains both the declarations of variables and the definitions of all package modules. The package body may also contain an execution section, which is called the initialization section because it is run only once, to initialize the package. (This aspect of packages is discussed in the next section.)
The general syntax for the package body is shown below:
PACKAGE BODY package_name
IS
[ declarations of variables and types ]
[ header and SELECT statement of cursors ]
[ header and body of modules ]
[ BEGIN
executable statements ]
[ EXCEPTION
exception handlers ]
END [ package_name ];In the body you can declare other variables, but you do not repeat the declarations in the specification. The body contains the full implementation of cursors and modules. In the case of a cursor, the package body contains both the header and the SQL statement for the cursor. In the case of a module, the package body contains both the header and body of the module.
The BEGIN keyword indicates the presence of an execution or initialization section for the package. This section can also optionally include an exception section.
As with a procedure, function, and package specification, you can add the name of the package, as a label, after the END keyword in both the specification and package.
The first time your application makes a reference to a package element, the entire package (in precompiled form) is loaded into the System Global Area of the database instance, making all objects immediately available in memory. All package data structures are defined and default values are assigned. You can supplement this automatic instantiation of the package code with the execution of startup code for the package. This initialization code is contained in the optional initialization section of the package body.
The initialization section consists of all statements following the BEGIN statement through the END statement for the entire package body. It is called the initialization section because the statements in this part of the package are executed only once, the first time an object in the package is referenced (to name a few possibilities, when a program is called, a cursor is opened, or a variable is used in an assignment). The initialization section initializes the package; it is commonly used to set values for variables declared and referenced in the package.
The initialization section is a powerful mechanism: PL/SQL detects automatically when this code should be run. You do not have to explicitly execute the statements, and you can be sure they are run only once. There is, however, a downside to use of the initialization section. It can be difficult to trace actions triggered automatically by the package ("Now where does that variable get set?" "How did that record get inserted into that table? I don't see it in any of my code!"). It can also be difficult for less experienced developers to locate and be aware of the initialization code.
You should only use the initialization section when you cannot rely on the normal initialization mechanisms (such as setting a default value when a variable is declared), as explored below.
Use the initialization section only when you need to set the initial values of package elements using rules and complex logic that cannot be handled in the default value syntax for variables. You do not, for example, need an initialization section to set the value of the constant earliest_date to today's date. Instead, simply declare the variable with a default value.
The following package body contains unnecessary initialization code:
PACKAGE config IS earliest_date DATE; BEGIN earliest_date := SYSDATE; END config;
This code should be replaced with a much simpler and more direct default assignment as follows:
PACKAGE config IS earliest_date DATE := SYSDATE; END config;
Suppose, on the other hand, that you wanted to use PLVlst to maintain a list of companies that the user has selected for financial analysis. The analysis is performed by a package you built called compcalc (COMPany CALCulation). You want to make sure that the list is defined and available whenever any program in compcalc is used, but you don't want the list refreshed or created anytime after the start of a user session. This is the perfect opportunity for an initialization section. The following package shows you how to achieve this effect:
PACKAGE BODY compcalc
IS
c_list CHAR(8) := 'compcalc';
PROCEDURE total_sales
IS
BEGIN
FOR list_ind IN 1 .. PLVlst.nitems (c_list)
LOOP
calc_sales (PLVlst.getitem (c_list, list_ind));
END LOOP;
END;
BEGIN
PLVlst.make (c_list);
END;The package body declares a constant containing the name of the list. This constant is then referenced throughout the package to avoid hard-coding of literals. The total_sales procedure calculates the sales for each item in the list. The initialization section at the bottom of the package consists of a single line of code that makes the list for use in the package. The PLVlst.make procedure is called only once in a user's session; the list is then available for the duration of the session.
You will also want to use an initialization section when you need to handle exceptions that might arise when initializing values.
As noted earlier, the initialization section of a package can also have its own exception section. The ability to handle exceptions is one of the most important characteristics of this section of the package.
Remember that the exception handlers in this section will only trap exceptions that occur in the initialization section itself. If an exception is raised in one of the programs defined in the package or if an exception is raised in the process of instantiating data in the package, the initialization section exception handlers will not be able to trap those exceptions.
To understand this flow, consider the following package specification and body:
PACKAGE going
IS
PROCEDURE bad;
END going;
PACKAGE BODY going
IS
fast VARCHAR2(3) := 'fast';
PROCEDURE bad IS
BEGIN
DBMS_OUTPUT.PUT_LINE (fast);
END;
BEGIN
NULL;
EXCEPTION
WHEN VALUE_ERROR
THEN
DBMS_OUTPUT.PUT_LINE ('too late');
END going;This package contains a single public procedure, going.bad, and a single private variable, fast. When any program tries to execute going.bad, the PL/SQL runtime engine loads the package into shared memory and instantiates all package data. When it tries to assign the value of fast to the variable going.bad, however, the runtime engine will raise the VALUE_ERROR exception. The literal value has four characters, but the fast variable is restricted to three characters.
It would appear at first glance that the exception handler for VALUE_ERROR at the bottom of the package body would trap this exception and display "too late". Instead, the exception will go unhandled.
Let's now see how to use the initialization section to your advantage when initializing values in a package. Consider the simple package body below:
PACKAGE BODY analysis IS best_salesperson INTEGER := sales_list (1); END analysis;
This package sets the default value for the best salesperson ID to the value in row 1 of the sales_list PL/SQL table. If for any reason this row has not yet been defined, the PL/SQL runtime engine will raise a NO_DATA_FOUND exception simply for trying to reference the analysis.best_salesperson variable.
If you move the assignment to an initialization section, on the other hand, you can handle gracefully the scenario in which row 1 in the table has not been set:
PACKAGE BODY analysis
IS
best_salesperson INTEGER;
BEGIN
best_salesperson := sales_list (1);
EXCEPTION
WHEN NO_DATA_FOUND
THEN
best_salesperson := NULL;
END analysis;There is a limit to the size of any PL/SQL program, whether it is a procedure or a package. The restriction on code size is determined by the limitation of the size of the PL/SQL parse tree, which is built for compilation purposes. In PL/SQL Release 2.2 and earlier, the number of nodes in the parse tree is limited to 16K. In Release 7.3, the upper limit is raised to 32K. A node in the parse tree typically consists of a keyword, application identifier, or operator.
Whatever the current limit, someone will always come up against it. And even if you don't actually threaten to exceed the theoretical limit, you might easily come up against a practical limit to the size of the package you can deal with. For example, do you really want to endure a 10-minute compile every time you have to make a small change to your monster package?
When PL/SQL developers ask me what they should do about their packages that are 10,000 lines long and causing all sorts of problems, I tell them: shorten your package or turn it into multiple packages. There, that was easy! And sometimes it really is that easy. Most programs, and certainly most packages, contain redundancies that needlessly increase code volume. A very careful review will almost always uncover ways to reduce the size of a program through fanatical modularization. In addition, few developers properly break apart their packages into distinct areas of functionality. Most large packages I have analyzed should have been broken up into multiple packages, regardless of the original size so that functionality would be more accessible and reuseable.
Yet in other situations, it really is difficult to shrink the size of one's package. Many real world tables have dozens, if not hundreds, of columns. Any Data Manipulation Language (DML) statement on such a table requires many bytes of code. And that 25,000-line package might really just contain code related to one specific area of functionality. To break that package into more than one package means requiring the user of those packages to deal with different package names. Why does procedure A reside in package X while function B can be found only in package Y?
There is, however, a technique you can use to break up a large package into multiple packages, while still maintaining the appearance of a single package for your users. You can create a cover package[4] that offers all the elements of the package under a single name. This cover package is, however, nothing more than a pass-through to other packages that contain the application logic.
[4] Note that the initial idea for this cover technique came from John M. Beresniewicz.
To see how this cover package technique works, consider the three packages defined below:
CREATE OR REPLACE PACKAGE forreal1
IS
PROCEDURE proc1;
END forreal1;
/
CREATE OR REPLACE PACKAGE BODY forreal1
IS
PROCEDURE proc1 IS BEGIN DBMS_OUTPUT.PUT_LINE ('for real 1'); End;
END forreal1;
/
CREATE OR REPLACE PACKAGE forreal2
IS
PROCEDURE proc1;
END forreal2;
/
CREATE OR REPLACE PACKAGE BODY forreal2
IS
PROCEDURE proc2 IS BEGIN DBMS_OUTPUT.PUT_LINE ('for real 2'); End;
END forreal2;
/CREATE OR REPLACE PACKAGE cover IS
PROCEDURE proc1; PROCEDURE proc2; END cover; / CREATE OR REPLACE PACKAGE BODY cover IS PROCEDURE proc1 IS BEGIN forreal1.proc1; END; PROCEDURE proc2 IS BEGIN forreal2.proc2; END; END cover; /
The cover package contains two procedures. But if you look at the implementation of those procedures in cover, you see that all they do is call the "for real" version of those procedures in their respective "for real" packages, forreal1 and forreal2. When a developer calls the cover procedures, she doesn't know that she is actually calling the underlying "for real" procedures.
SQL> exec cover.proc1 for real 1 SQL> exec cover.proc2 for real 2
This redirection or passthrough in and of itself is not a major breakthrough. What makes this cover layer of code so useful is that you can set up access to these packages so that a developer can only execute the cover package and never even know about the underlying packages. This preserves the integrity of existing applications (written way back when all the code managed to fit in a single package) and protects the underlying code from being accessed improperly.
Suppose, for example, that the cover and "for real" packages are created in the APPOWNER account. I can then grant access to the cover package to SCOTT as follows:
SQL> GRANT EXECUTE ON cover TO scott;
I can also create a synonym for cover:
SQL> CREATE PUBLIC SYNONYM cover FOR appowner.cover;
Now a developer working in the SCOTT account can execute the cover procedures, but cannot execute the "for real" package-based procedures. All anyone knows about is the cover -- and if you name the packages differently, you don't even know you are working with a cover!
Sure, it would be better to be able to keep all related code in a single package. But at least with the cover technique developers using your software don't have to know about the smoke-filled back room manipulations.
As of PL/SQL Release 2.1, you can call stored functions like total_comp anywhere in a SQL statement where an expression is allowed, including the SELECT, WHERE, START WITH, GROUP BY, HAVING, ORDER BY, SET, and VALUES clauses. (Since stored procedures are in and of themselves PL/SQL executable statements, they cannot be embedded in a SQL statement.)
Suppose, for example, that you need to calculate and use an employee's total compensation both in native SQL and in your forms. The computation itself is straightforward enough:
Total compenstation = salary + bonus
My SQL statement would include this formula:
SELECT employee_name, salary + NVL (bonus, 0) FROM employee;
while my Post-Query trigger in my Oracle Forms application might employ the following PL/SQL code:
:employee.total_comp := :employee.salary + NVL (:employee.bonus, 0);
In this case, the calculation is very simple, but the fact remains that if, for any reason, you need to change the total compensation formula (different kinds of bonuses, for example), you would then have to change all of these hard-coded calculations both in the SQL statements and in the frontend application components.
A far better approach is to create a function that returns the total compensation:
FUNCTION total_comp (salary_in IN employee.salary%TYPE, bonus_in IN employee.bonus%TYPE) RETURN NUMBER IS BEGIN RETURN salary_in + NVL (bonus_in, 0); END;
Then I can replace the formulas in my code as follows:
SELECT employee_name, total_comp (salary, bonus) FROM employee; :employee.total_comp := total_comp (:employee.salary, :employee.bonus);
You can use one of your own functions just as you would a builtin SQL function such as TO_DATE or SUBSTR or LENGTH. (Chapter 19, of Oracle PL/SQL Programming, offers many examples and details about how to use stored functions in this way.) There are, for example, many restrictions on functions called in SQL, most notably that:
The function may not execute INSERTs, UPDATEs, or DELETEs. You can't change data while you are executing the function in your SQL statement.
The function may not execute any builtin packaged programs. You cannot, in other words, use DBMS_SQL or DBMS_PIPE in a function and then call it in SQL.
In the remainder of this chapter, I take a look at the steps you need to take to make package-based functions callable in your SQL statements. Specifically, you will need to make use of the RESTRICT_REFERENCES pragma.
A stored function can exist as a standalone function or as a function in a package. For standalone functions, the Oracle Server automatically determines whether it is callable in SQL. It will, for example, reject your SQL statement if it uses a function that issues an UPDATE statement. The situation with packaged functions is a bit more complicated.
As noted earlier, the specification and body of a package are distinct; a specification can exist even before its body. For this and other reasons, the Oracle Server cannot automatically determine (when you execute your SQL) that a packaged function is valid for SQL execution. Instead, you must state explicitly the "purity level" of a function in a package with the RESTRICT_REFERENCES pragma. The Oracle Server then determines at compile time (of the package body) if the function violates the purity level, and raise a compilation error if this is the case. Once the package is compiled, the functions for which assertions have been made can be called in SQL.
Let's explore the specific syntax required to achieve this effect.
A pragma is a special directive to the PL/SQL compiler. If you have ever created a programmer-defined, named exception, you have already encountered your first pragma. In the case of the RESTRICT_REFERENCES pragma, you are telling the compiler the purity level you believe your function meets or exceeds.
You need a separate PRAGMA statement for each packaged function you wish to use in a SQL statement, and it must come after the function declaration in the package specification (you do not specify the pragma in the package body).
To assert a purity level with the pragma, use the following syntax:
PRAGMA RESTRICT_REFERENCES (function_name, WNDS [, WNPS] [, RNDS] [, RNPS])
where function_name is the name of the function whose purity level you wish to assert, and the four different codes have the following meanings:
Purity Code | Description |
|---|---|
Stands for "Writes No Database State." Asserts that the function does not modify any database tables. | |
WNPS | Stands for "Writes No Package State." Asserts that the function does not modify any package variables. |
RNDS | Stands for "Reads No Database State." Asserts that the function does not read any database tables. |
RNPS | Stands for "Reads No Package State." Asserts that the function does not read any package variables. |
Notice that only the WNDS level is mandatory in the pragma. That is consistent with the restriction that stored functions in SQL may not execute an UPDATE, INSERT, or DELETE statement. All other states are optional. You can list them in any order, but you must include the WNDS argument. No one argument implies another argument. For example, I can write to the database without reading from it. I can read a package variable without writing to a package variable.
Here is an example of two different purity level assertions for functions in the company_financials package:
PACKAGE company_financials
IS
FUNCTION company_type (type_code_in IN VARCHAR2)
RETURN VARCHAR2;
FUNCTION company_name (company_id_in IN company.company_id%TYPE)
RETURN VARCHAR2;
PRAGMA RESTRICT_REFERENCES (company_type, WNDS, RNDS, WNPS, RNPS);
PRAGMA RESTRICT_REFERENCES (company_name, WNDS, WNPS, RNPS);
END company;
In this package, the company_name function does read from the database to obtain the name for the specified company. Notice that I placed both pragmas together at the bottom of the package specification. The pragma does not need to immediately follow the function specification. I also went to the trouble of specifying the WNPS and RNPS arguments for both of the functions. Oracle Corporation recommends that you assert the highest possible purity levels so that the compiler will never reject the function unnecessarily.
I have found, on the other hand, that the PL/SQL compiler does at times reject my purity level assertions when there does not seem to be any apparent violation. You may at times have to retreat to the minimal WNDS assertion simply to get your package to compile.
If your package contains an initialization section (executable statements after a BEGIN statement in the package body), you must also assert the purity level of that section. The initialization section is executed automatically the first time any package object is referenced. So if a packaged function is used in a SQL statement, it will trigger execution of that code. If the initialization section modifies package variables or database information, the compiler needs to know about that through the pragma.
You can assert the purity level of the initialization section either directly or indirectly. To use a direct assertion, you use this variation of the pragma RESTRICT_REFERENCES:
PRAGMA RESTRICT_REFERENCES (package_name, WNDS, [, WNPS] [, RNDS] [, RNPS])
Instead of specifying the name of the function, you include the name of the package itself, followed by all the applicable state arguments. In the following argument I assert only WNDS and WNPS because the initialization section reads data from the configuration table and also reads the value of a global variable from another package (session_pkg.user_id).
PACKAGE configure
IS
PRAGMA RESTRICT_REFERENCES (configure, WNDS, WNPS);
user_name VARCHAR2(100);
END configure;
PACKAGE BODY configure
IS
BEGIN
SELECT lname || ', ' || fname INTO user_name
FROM user_table
WHERE user_id = session_pkg.user_id;
END configure;Why can I assert the WNPS even though I do write to the user_name package variable? Answer: It's a variable from this same package, so the action is not considered a side effect.
You can also assert the purity level of the package's initialization section by allowing the compiler to infer that level from the purity level(s) of all the pragmas for individual functions in the package. In the following version of the company package, the two pragmas for the functions allow the Oracle Server to infer a combined purity level of RNDS, WNPS for the initialization section. This means that the initialization section cannot read from the database and cannot write to a package variable.
PACKAGE company
IS
FUNCTION get_company (company_id_in IN VARCHAR2)
RETURN company%ROWTYPE;
FUNCTION deactivate_company (company_id_in IN company.company_id%TYPE)
RETURN VARCHAR2;
PRAGMA RESTRICT_REFERENCES (get_company, RNDS, WNPS);
PRAGMA RESTRICT_REFERENCES (deactivate_name, WNPS);
END company;Generally, you are probably better off providing an explicit purity level assertion for the initialization section. This makes it easier for those responsible for maintaining the package to understand both your intentions and your understanding of the package.
|  | |
| 1.5 Types of Packages |  | 2. Best Practices for Packages |
Copyright (c) 2000 O'Reilly & Associates. All rights reserved.