
Western European Languages
Conforming to Local Customs
Non-Western European Languages
Multiple Languages
Dynamic Language Negotiation
HTML Forms
Receiving Multilingual Input
Despite its name, the World Wide Web has a long way to go before it can be considered to truly extend worldwide. Sure, physical wires carry web content to nearly every country across the globe. But to be considered a true worldwide resource, that web content has to be readable to the person receiving it--something that often doesn't occur with today's large number of English-only web pages.
The situation is starting to change, however. Many of the largest web sites have established areas designed for non-English languages. For example, the Netscape home page is available to English speakers at http://home.netscape.com/index.html, to French speakers at http://home.netscape.com/fr/index.html, and to speakers of a dozen other languages at a dozen other URLs.
Many web servers also support a transparent solution, where a single URL can be used to view the same content in several languages, with the language chosen based on the preferences of the client. For example, the Internet Movie Database home page at http://us.imdb.com/index.html can be read in English, German, or French. Which language you see depends on how you've configured your browser.[1] Although this technique creates the impression that a dynamic translation is occurring, in reality the server just has several specially named versions of the static document at its disposal.
[1]Many older browsers do not support language customization, however. For example, the feature is new in Netscape Navigator 4 and Microsoft Internet Explorer 4.
While these techniques work well for static documents, they don't address the problem of how to internationalize and localize dynamic content. That's the topic of this chapter. Here we explore how servlets can use the internationalization capabilities added to JDK 1.1 to truly extend the Web worldwide.
First, let's discuss terminology. Internationalization (a word that's often mercifully shortened to "i18n" because it begins with an "I", ends with an "n", and has 18 letters in between) is the task of making a program flexible enough to run in any locale. Localization (often shortened to "l10n") is the process of arranging for a program to run in a specific locale. This chapter, for the most part, covers servlet internationalization. We'll cover localization only in the case of dates, times, numbers, and other objects for which Java has built-in localization support.
Let's begin with a look at how a servlet outputs a page written in a Western European language such as English, Spanish, German, French, Italian, Dutch, Norwegian, Finnish, or Swedish. As our example, we'll say "Hello World!" in Spanish, generating a page similar to the one shown in Figure 12-1.
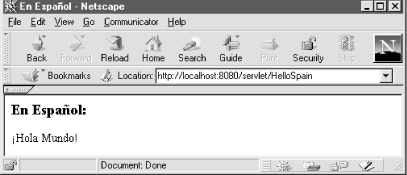
Notice the use of the special characters "ñ" and "¡". Characters such as these, while scarce in English, are prevalent in Western European languages. Servlets have two ways to generate these characters: with HTML character entities or Unicode escape sequences.
HTML 2.0 introduced the ability for specific sequences of characters in an HTML page to be displayed as a single character. The sequences, called characterentities, begin with an ampersand (&) and end with a semi-colon (;). Character entities can either be named or numbered. For example, the named character entity "ñ" represents "ñ", while "¡" represents "¡". A complete listing of special characters and their names is given in Appendix D, "Character Entities". Example 12-1 shows a servlet that uses named entities to say hello in Spanish.
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HelloSpain extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
PrintWriter out = res.getWriter();
res.setHeader("Content-Language", "es");
out.println("<HTML><HEAD><TITLE>En Español</TITLE></HEAD>");
out.println("<BODY>");
out.println("<H3>En Español:</H3>");
out.println("¡Hola Mundo!");
out.println("</BODY></HTML>");
}
}
You may have noticed that, in addition to using character entities, this servlet sets its Content-Language header to the value "es". The Content-Language header is used to specify the language of the following entity body. In this case, the servlet uses the header to indicate to the client that the page is written in Spanish (Español). Most clients ignore this information, but it's polite to send it anyway. Languages are always represented using two-character lowercase abbreviations. For a complete listing, see the ISO-639 standard at http://www.ics.uci.edu/pub/ietf/http/related/iso639.txt.
Character entities can also be referenced by number. For example, "ñ" represents "ñ", and "¡" represents "¡". The number corresponds to the character's ISO-8859-1 (Latin-1) decimal value, which you will hear more about later in this chapter. A complete listing of the numeric values for character entities can also be found in Appendix D, "Character Entities". Example 12-2 shows HelloSpain rewritten using numeric entities.
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HelloSpain extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
PrintWriter out = res.getWriter();
res.setHeader("Content-Language", "es");
out.println("<HTML><HEAD><TITLE>En Español</TITLE></HEAD>");
out.println("<BODY>");
out.println("<H3>En Espa&241;ol:</H3>");
out.println("¡Hola Mundo!");
out.println("</BODY></HTML>");
}
}
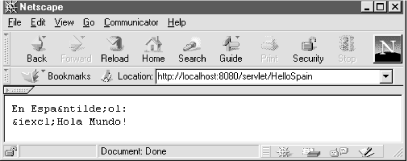
Unfortunately, there's one major problem with the use of character entities: they work only for HTML pages. If the servlet's output isn't HTML, the page looks something like Figure 12-2. To handle non-HTML output, we need to use Unicode escapes.
In Java, all characters, strings, and identifiers are internally composed of 16-bit (2-byte) Unicode characters. Unicode was established by the Unicode Consortium, which describes the standard as follows (see http://www.unicode.org/unicode/standard/standard.html):
The Unicode Worldwide Character Standard is a character coding system designed to support the interchange, processing, and display of the written texts of the diverse langiages of the modern world. In addition, it supports classical and historical texts of many written languages.
In its current version (2.0), the Unicode standard contains 38,885 distinct coded characters derived from the Supported Scripts. These characters cover the principal written languages of the Americas, Europe, the Middle East, Africa, India, Asia, and Pacifica.
For more information on Unicode see http://www.unicode.org. Also see The Unicode Standard, Version 2.0(Addison-Wesley).
Java's use of Unicode is very important to this chapter because it means a servlet can internally represent essentially any character in any commonly used written language. We can represent 16-bit Unicode characters in 7-bit US-ASCII source code using Unicode escapes of the form \uxxxx, where xxxx is a sequence of four hexadecimal digits. The Java compiler interprets each Unicode escape sequence as a single character.
Conveniently, and not coincidentally, the first 256 characters of Unicode (\u0000 to \u00ff) correspond to the 256 characters of ISO-8859-1 (Latin-1). Thus, the "ñ" character can be written as \u00f1 and the "¡" character can be written as \u00a1. A complete listing of the Unicode escape sequences for ISO-8859-1 characters is also included in Appendix D, "Character Entities". Example 12-3 shows HelloSpain rewritten using Unicode escapes.
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HelloSpain extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/plain");
PrintWriter out = res.getWriter();
res.setHeader("Content-Language", "es");
out.println("En Espa\u00f1ol:");
out.println("\u00a1Hola Mundo!");
}
}
The output from this servlet displays correctly when used as part of an HTML page or when used for plain-text output.
 |  |  |
| 11.4. Recap |  | 12.2. Conforming to Local Customs |

Copyright © 2001 O'Reilly & Associates. All rights reserved.