 | Programming the Perl DBI |  |

The Relational Database Methodology
Datatypes and NULL Values
Querying Data
Modifying Data Within Tables
Creating and Destroying Tables
The Structured Query Language, or SQL,[20] is a language designed for the purpose of manipulating data within databases.
[20]Officially pronounced ``ess-que-ell,'' although ``sequel'' is also popular. We have also heard the term ``squeal,'' but that's usually only heard when people first see the syntax or when they've just deleted all their data!
In 1970, E. F. Codd, working for IBM, published a now classic paper, "A Relational Model of Data for Large Shared Data Banks," in which he laid down a set of abstract principles for data management that became known as the relational model. The entire field of relational database technology has its roots in that paper.
One of the many research projects sparked by that paper was the design and implementation of a language that could make interacting with relational databases simple. And it didn't make the programmer write horrendously complex sections of code to interact with the database.[21]
[21]Chapter 2, "Basic Non-DBI Databases " shows many examples of how long-winded and inflexible database interaction can be!
This chapter serves to give the complete database neophyte a very limited overview of what SQL is and how you can do some simple tasks with it. Many of the more complex details of SQL's design and operation have been omitted or greatly simplified to allow the neophyte to learn enough to use the DBI in a simple, but effective, way. Section 0.1, "Resources " in the Preface lists other books and web sites dedicated to SQL and relational database technologies.
The relational database model revolves around data storage units called tables, which have a number of attributes associated with them, called columns. For example, we might wish to store the name of the megalithic site, its location, what sort of site it is, and where it can be found on the map in our megaliths table. Each of these items of data would be a separate column.
In most large database systems, tables are created within containing structures known as schemas . A schema is a collection of logical data structures, or schema objects, such as tables and views. In some databases, a schema corresponds to a user created within the database. In others, it's a more general way of grouping related tables. For example, in our megalithic database, using Oracle, we have created a user called stones. Within the stones user's schema, the various tables that compose the megalithic database have been created.
Data is stored within a table in the form of rows . That is, the data for one site is stored within one row that contains the appropriate values for each column. This sort of data layout corresponds exactly to the row-column metaphor used by spreadsheets, ledgers, or even plain old tabulated lists you might scribble in a notepad.
An example of such a list containing megalithic data is:
Site Location Type Map Reference ---- -------- ---- ------------- Callanish I Western Isles Stone Circle and Rows NB 213 330 Stonehenge Wiltshire Stone Circle and Henge SU 123 422 Avebury Wiltshire Stone Circle and Henge SU 103 700 Sunhoney Aberdeenshire Recumbent Stone Circle NJ 716 058 Lundin Links Fife Four Poster NO 404 027
This system lends itself quite well to a generalized query such as ``Give me the names of all the megaliths'' or ``Give me the map locations of all the megaliths in Wiltshire.'' To perform these queries, we simply specify the columns we wish to see and the conditions each column in each row must meet to be returned as a valid result.
Similarly, data manipulation operations are easily specified using a similar syntax, such as "Insert a new row into the megaliths table with the following values..." or "Delete all the rows containing megaliths in Fife."
The sheer simplicity of SQL belies the fact that it is an extraordinarily powerful syntax for manipulating data stored within databases, and helps enforce a logical structure for your data.
The main thrust of the relational database design is that related information should be stored either in the same place or in a separate place that is related to the original in some meaningful way. It also is designed around the principle that data should not be duplicated within the database.
Using our megalithic database as an example, we have decided to store all information directly related to each megalithic site within the megaliths table and all the multimedia clips in a separate table. This is a good example of a relational database, albeit a small one, because if we stored the multimedia clip information in the megaliths table, we would duplicate the megalith information many times over -- once per clip for that site, in fact. This leads to redundancy of data, which is one problem the relational database model is designed to avoid.
We have also split the categorization of a site into a separate table called site_types to avoid further redundancy of data.
The process of rationalizing your data into tables to avoid data redundancy is known as normalization. The corollary operation is known as denormalization and can be desirable in certain situations.
Data stored across multiple normalized tables can be retrieved by making joins between the tables that allow queries to retrieve columns from all the tables included in the join. Joins would allow us to fetch the name of the megalithic site and the URL of multimedia clips from the same query, for example. This is an efficient way of storing data and stores exactly enough data necessary to retrieve the desired information.
On the downside, creating multi-table joins on a regular basis can perform badly on databases with large data quantities. Extra disk accesses are required to relate the rows of one table to another, and it can be difficult for the database to work out how best to do it.
This is a major problem in the discipline known as data warehousing , in which massive quantities of information are stored to allow users to produce reports and analyses of that data. The typical solution for these situations is to create new wide, denormalized tables that contain much information duplicated from other tables. This greatly increases performance at the expense of storage space and, since the information contained within the data warehouses is generally read-only, you don't have to worry about keeping data changes synchronized.
For the purposes of these chapters, a small database containing three tables will be used to demonstrate the various ways in which SQL can be used to query and manipulate data. These tables are named megaliths, media, and site_types. Figure 3-1 illustrates the structure of these three tables.
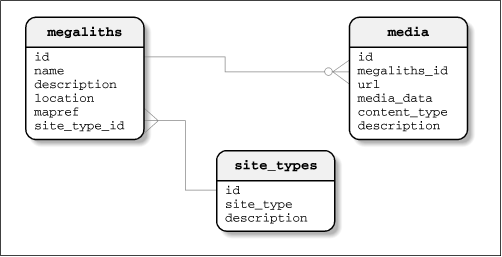
These tables are designed to contain information on megalithic sites and multi-media clips associated with those sites respectively. In essence, each megalithic site will have zero or more multimedia clips associated with it and will be categorized as exactly one type of site. This small database will form the basis of our examples throughout the remainder of the book.
|  | |
| 2.9. Summary |  | 3.2. Datatypes and NULL Values |

Copyright © 2001 O'Reilly & Associates. All rights reserved.