
If you've had problems reading PDF files on various devices (like mobile phones), PdfMasher may be just what you're looking for. According to the Web site:
PdfMasher is a tool to convert PDF files containing text in ready-for-e-book HTML files. Most e-book readers support PDF files natively, but it's often a real pain to read those documents, because we don't have font-size control over the document like we have with native e-books. In many cases, we have to use the zooming feature, and it's just a pain. Another drawback of PDFs on e-book readers is that annotations are not supported.
There are already tools to convert PDFs to e-books, like Calibre, but what they do is try to guess the role of each piece of text in the PDF (and that's if you're lucky). I think that in all but the simplest cases, it's a mistake to think that anything short of an AI can do that kind of guessing.
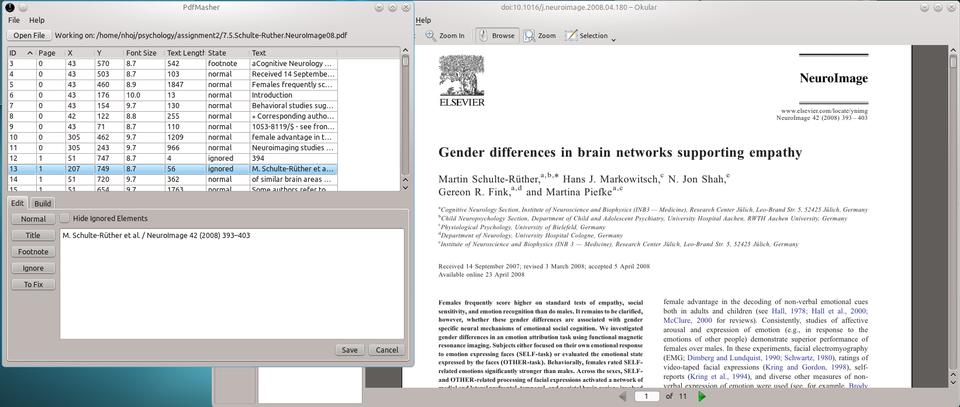
Using PdfMasher, PDF files like these can be manipulated manually for conversion into other formats.
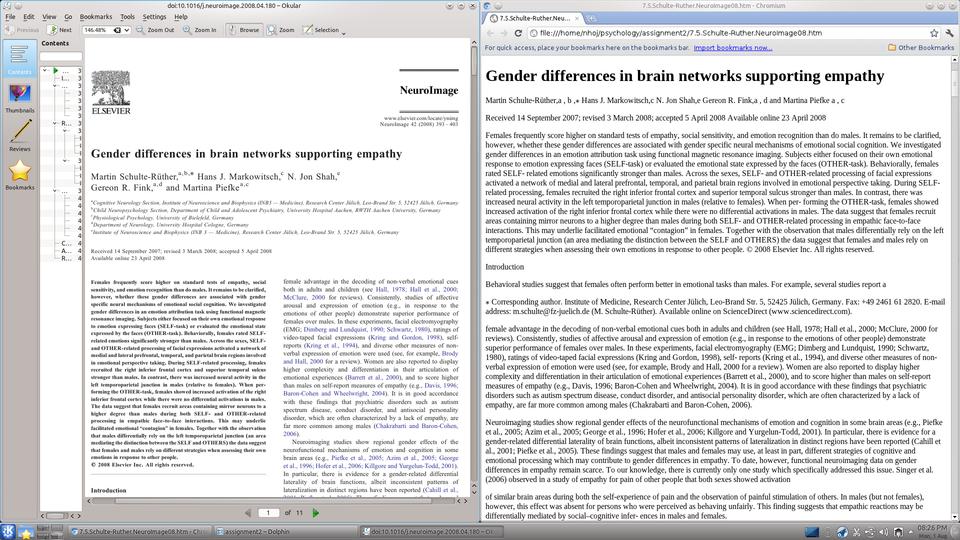
With the original PDF on the left and outputted HTML on the right, this e-book now can be read on any device without readability woes.
Installation
If you can install this with a binary, by all means do so. Available on the site are 32- and 64-bit Linux .deb packages for the ubiquitous Intel x86 architecture. For masochists, or those who don't have an Intel-based CPU, there is the obligatory source.
In order to grab the latest source, first you need to install hg, which was under the package name “mercurial” on my Kubuntu system. Once that's installed, grab the latest source by entering the command:
$ hg clone https://bitbucket.org/hsoft/pdfmasher
Once that has finished downloading, keep this terminal open where it is, because next you'll need to sort out the library requirements, and then you'll return to this terminal and continue the installation. As far as dependencies are concerned, the documentation lists the following:
Python 3.2 (www.python.org)
pdfminer3k (hg.hardcoded.net/pdfminer3k)
jobprogress 1.0.0 (hg.hardcoded.net/jobprogress)
Sphinx 1.0.7 (sphinx.pocoo.org)
pytest 2.0.3 to run unit tests (pytest.org)
Markdown 2.0.3 (www.freewisdom.org/projects/python-markdown)
PyQt 4.7.5 (www.riverbankcomputing.co.uk/news)
With the dependencies out of the way, re-open the terminal from before and enter the following commands:
$ cd pdfmasher $ python configure.py $ python build.py
Then, run the program with:
$ python run.py
If you're lucky enough to have the binary installed, you simply can run the program with the command:
$ pdfmasher
Usage
Before I try to explain how to use PdfMasher myself, I should include the following from the Web site:
PdfMasher asks the user about the role of each piece of text, and does it in an efficient manner. Your PDF has a header on each page, and you don't want them to litter your text? Sort text elements by Y-position (thus grouping them all together); Shift-select the elements and flag them as ignored. They will not appear on your final HTML. Your PDF has footnotes on many pages? Sort your elements by text content (thus grouping all elements with the text starting with a number together) and flag them as footnotes. They will be moved to the end of the document, and PdfMasher will try to create hyperlinks to footnote references.
Before changing things under PdfMasher, I recommend having your PDF open to one side in another program so you can cross-check bits of text as you're culling sections. When you're ready to start, click on Open File and choose the PDF you want to “mash”.
Once open, the pane below fills up in a manner that at first glance is overwhelming and incomprehensible. However, on a very basic level, each line is a section of text in your PDF. If you explore each line, you can check which part of the PDF is being examined, and if it's redundant, you can choose to ignore it in the conversion.
Looking at these PdfMasher lines in detail, each line has an X and Y axis reference, as well as font size, text length and page number. Whenever you click a line, the full text content of its section in the PDF is shown in the pane below.
If you've decided on which sections to remove, click Ignore to cut out the text from the final product. Click Normal to reinstate the text for inclusion. Depending on which device you'll be reading the resulting e-book, the header and footer information may be something you want to cut out of the page.
For example, in the screenshot, I'm removing the beginning references and page headers in a psychology paper that otherwise would leave a hard-to-navigate, garbled mess if I translated it into something I could read on my phone.
However, if what you're preparing is intended to be something like a public Web page instead of a trimmed-down e-book, you might want to use the Title and Footnote buttons. Title will result in an H1 title header in the outputted HTML. The Footnote button will move the text to the bottom of the document, and PdfMasher will try to make one of the cool hyperlinks mentioned earlier.
Once you've finished editing your document, click on the Build tab below, and then click on the Generate Markdown button. A raw text file will be generated in the same folder as the original PDF. Click on Reveal Markdown, and the source folder will be opened in your default file manager. Edit Markdown will open the actual text file in your default text editor, and View HTML will show the end product in a Web browser.
If you've made any errors, the output will reveal them quickly, and you can go back and simply start the Build process again. From here, you either can leave your output as is or convert your files into specific e-book formats.
Either way, PdfMasher uses some very simple methods to create something very clever and is a must-have for any regular e-book reader.
According to its Freshmeat entry:
Fpdb is a free/open-source tracker/HUD for use with on-line poker. The intent is to make fpdb capable of supporting all games on all sites.
Fpdb currently supports flop games (Hold 'em, Omaha, Omaha hi/low), stud games (7 card stud, Stud 8 and Razz) and draw games (2–7 Lowball single and triple draw, Badugi and 5 card draw).
Cash games are fully supported, and tournament support is improving all the time.
Currently supported sites include PokerStars, Full Tilt Poker, the Everleaf network, the Boss Media network and others; see Features for a full list. Additional poker sites can be supported by writing a plugin to parse the site's hand history files. Several additional plugins are under development and in the development tree.
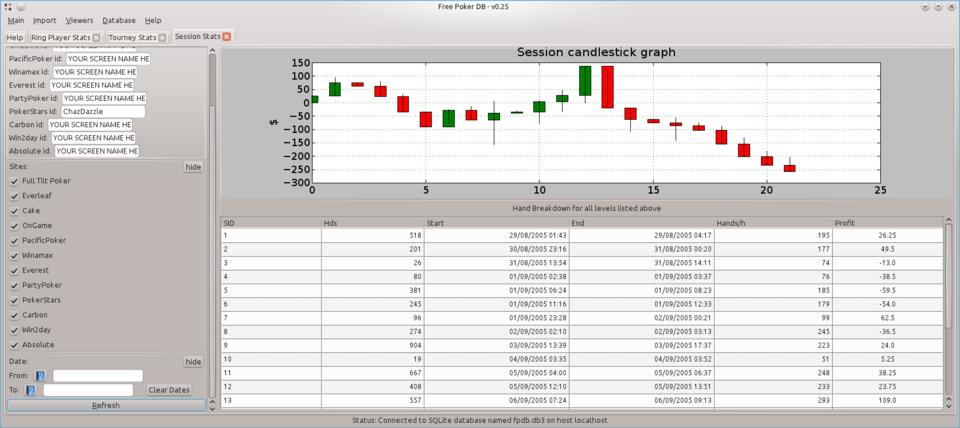
Fpdb provides impressive player statistics to give you the edge in on-line poker.
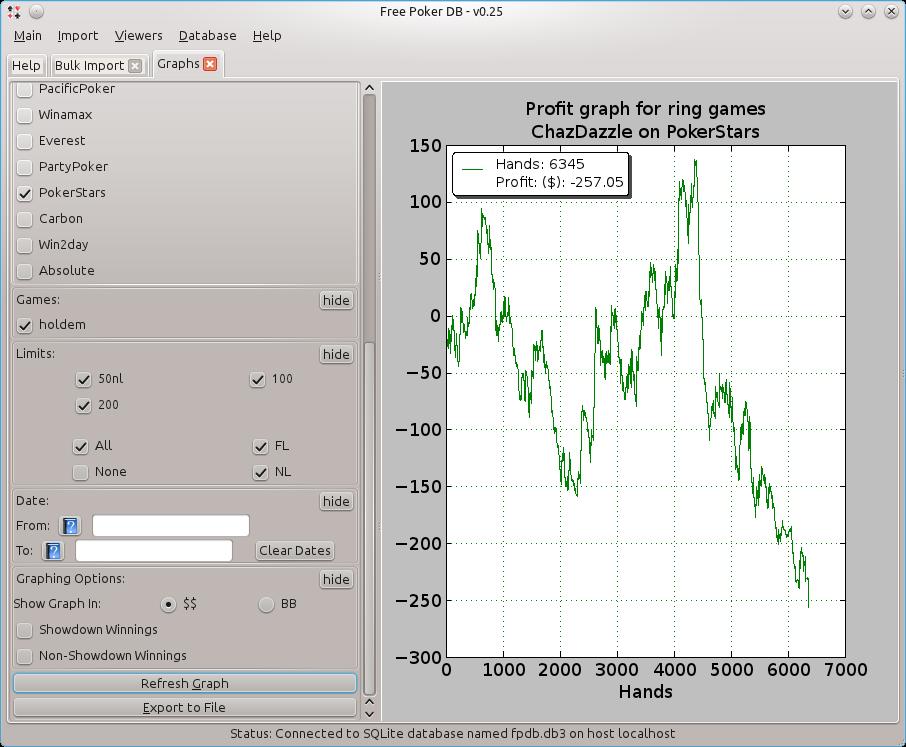
Fpdb's profit graph: looks like ChazDazzle had a bad weekend!
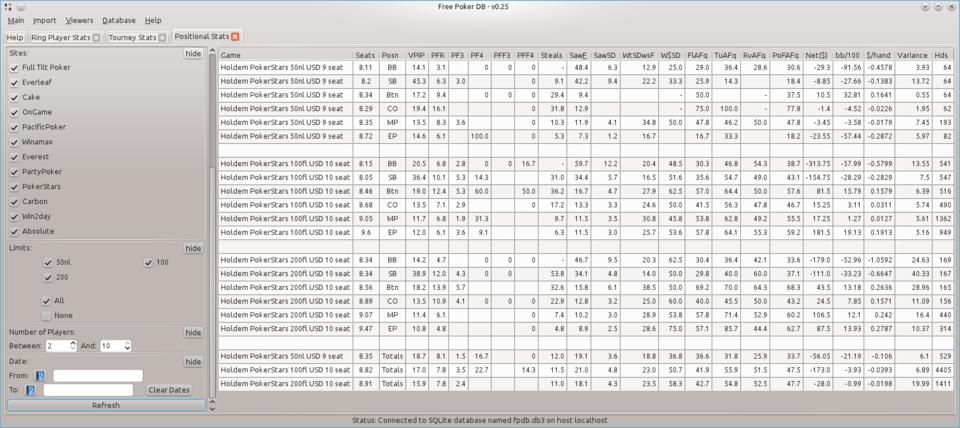
The Positional Stats are comprehensive to say the least.
Installation
Binaries may be available in your repository (called python-fpdb on my Kubuntu system). Source also is available, and it doesn't seem to require any awkward compiling. To get an idea of the library requirements, the documentation noted the following successful package combination for Ubuntu 9.10:
Python 2.6
GTK+ 2.18.3
PyGTK 2.16.0
matplotlib 0.99.0
numpy 1.3.0
sqlite3 2.4.1
sqlite 3.6.16
database mysql
Note the SQL dependencies, as they are particularly important. The fpdb wiki's installation section has a very involved section regarding MySQL under Gentoo, so hopefully a combination of the provided Ubuntu and Gentoo instructions will point you in the right direction for your system.
For those running with source, once you have the library requirements out of the way, you either can grab a source tarball or set up a local repository with git. For the git option, enter the command:
$ git clone git://git.assembla.com/free_poker_tools.git
For those wanting to use the source tarball, grab the latest tarball from the Downloads page and extract it. Open a terminal in the new folder, and you should be able to run the program simply by entering:
$ ./run_fpdb.py
Whereas my Kubuntu binary ran with the command:
$ fpdb
Usage
Before you start using fpdb, you obviously have to play some poker on one of the supported games, building up an account with some dealt hands against other players and whatnot. Once you've done that, you need to locate the local account files for this game so fpdb can find it later.
The best supported commercial site for Linux is PokerStars, as it runs almost perfectly under Wine. As a religious guy, I can't actually play for money, but I can vouch for PokerStars as it does have a “Play Money” mode for people like me. However, the developers did make it clear to me that fpdb is focused on real money games, so play money support isn't well tested but should work for PokerStars' cash games.
Moving back to fpdb, once you have some data ready to go, click on the Import menu and choose Bulk Import. Browse for the file(s) of your poker site below, and choose your game from the Site filter drop-down box. Now, click Bulk Import and wait a moment for your data to be processed.
I can take you through only a few basic steps, but it should be enough to get you started, after which you should pick up things pretty easily. Looking at the graphs first, click on the Viewers menu and choose Graphs. Find your game(s) below, and enter your user ID. Now in the Sites pane, check/uncheck the games you want to display, and choose Refresh Graph at the bottom. If all went well, a profit graph should display in the panel on the right.
This last step really shows you how to use all of the other viewers as well, so feel free to explore the other features to your heart's content—Ring Player Stats, Tourney Stats, Positional Stats, it's all there. And don't feel restricted to your own account either. You also can see the stats of other players, which, when you think of it, is really the whole point of this program!
Ultimately, Free Poker DB will give a genuine edge to any serious on-line poker players, particularly those taking part in tournaments and the like. However, I'd like to end this month on a slightly different note—an unsolicited comment from co-developer “Chaz” on some heart-warming realities of OSS:
I got involved in the project about a year ago after leaving my job as a management consultant in Washington, DC, to start Pokeit. Pokeit is a similar product to fpdb, except it's a Web application and a commercial venture. On the face of it, Pokeit's collaboration with fpdb might seem a bit odd, given that we're trying to charge for something that fpdb gives away for free. In practice, it feels perfectly natural, and really it should. It almost goes without saying that you can't launch a business today without depending on open-source software—whether that be databases, such as MySQL or Postgres, free development tools, languages, add-on modules or niche libraries. Likewise for us, any tools that track and analyze hands of Internet poker require a set of core functionality for reading and storing data. Developing such a core function from scratch would have been a monumental waste of time for us when fpdb already had a two-year head start and strong foundation already built. So instead of going it alone, we decided early on to collaborate with fpdb on developing the codebase in as many ways as it made sense.
Let's hope his example catches on.
